【笔记】ChatGPT是怎样炼成的(李宏毅2023机器学习课程引入部分)
ChatGPT太火热了,借此简单了解一下ChatGPT的newbie之处在哪里?同一个问题,它的每次回答都不同;处于同一个chat中,我可以追问多个问题,因为它知道上下文。
来源:【授权】李宏毅2023春机器学习课程
ChatGPT太火热了,借此简单了解一下
ChatGPT的newbie之处在哪里?
同一个问题,它的每次回答都不同;处于同一个chat中,我可以追问多个问题,因为它知道上下文。
对于ChatGPT的误解
误解1: ChatGPT的回应是罐头回应。(ie. 比如我让ChatGPT给我讲个笑话,罐头回应就是程序员让ChatGPT事先准备好了一些笑话,ChatGPT从中随机抽一个来回答我)
解释: 不是罐头回应哦,下文会解释。
误解2: ChatGPT的回答是Google一下的结果。
解释: ChatGPT不联网。它是用2021年前的网络数据训练的,所以问它2021年后的问题它会回答“无法预测”。
对于ChatGPT的正解
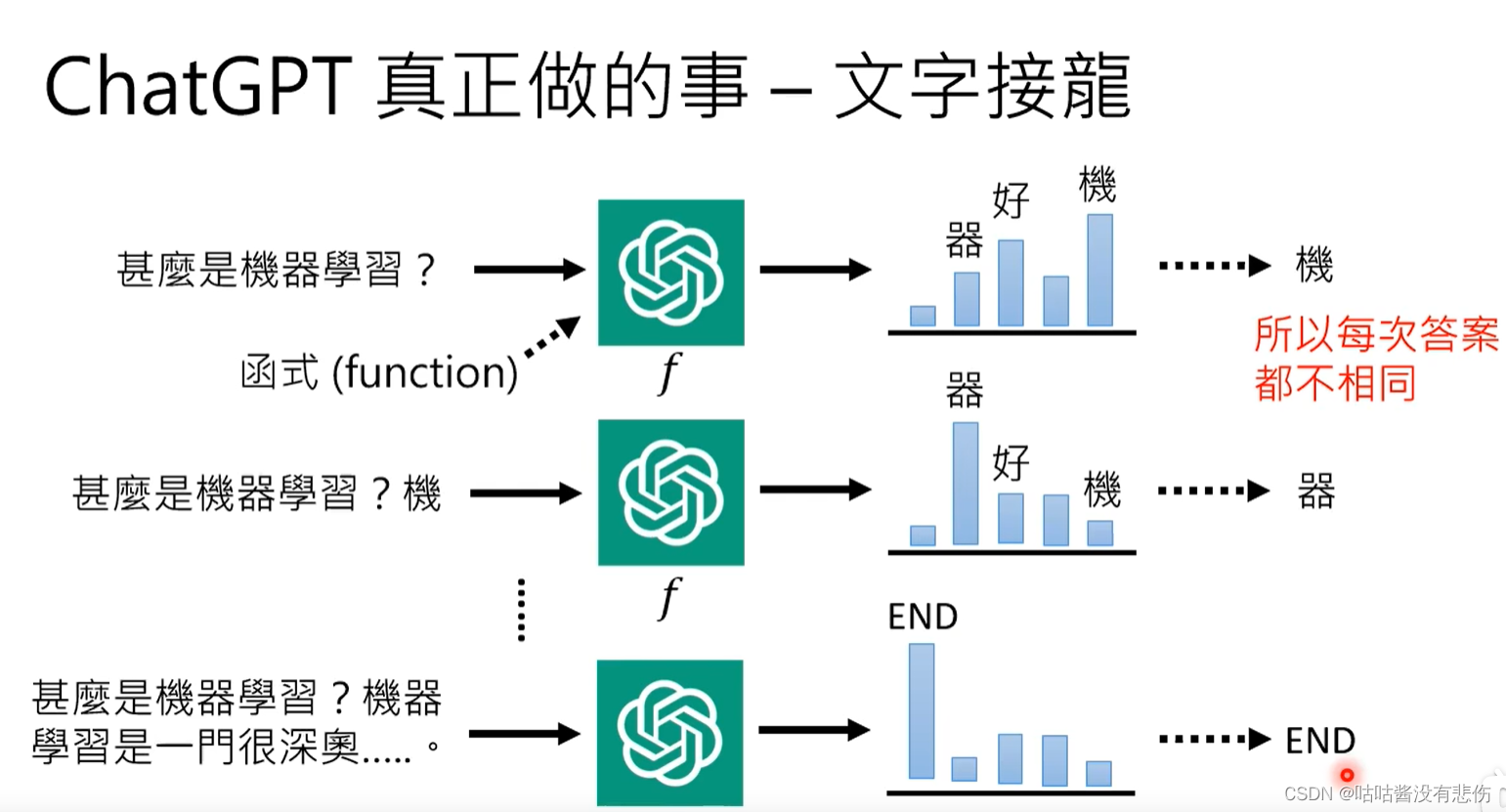
ChatGPT的工作原理实质是:文字接龙。
作为一个函数function,它的 input 是历史对话信息+我们输入的问题(eg. 历史对话信息+"什么是机器学习?")。
它的 output 是跟在 input 之后的可能紧跟着的词汇出现概率分布(eg. 机50%、是30%、我10%、所20%),然后ChatGPT选那个概率最大的(eg. 输入变成了 历史对话信息+"什么是机器学习?机")。至于候选的词汇,是sample出来的(所以每次它的回答都不一样)。那么何时结束呢?当候选词中“end符”的概率最大时。
李宏毅老师猜测ChatGPT这个模型拥有1700亿以上的参数。
ChatGPT的关键技术
pre-training预训练(或者叫 self-supervised model自监督模型 / foundation model基石模型)
从名字就可以体现—— ChatG(generative) P(pre-training) T(transformer)
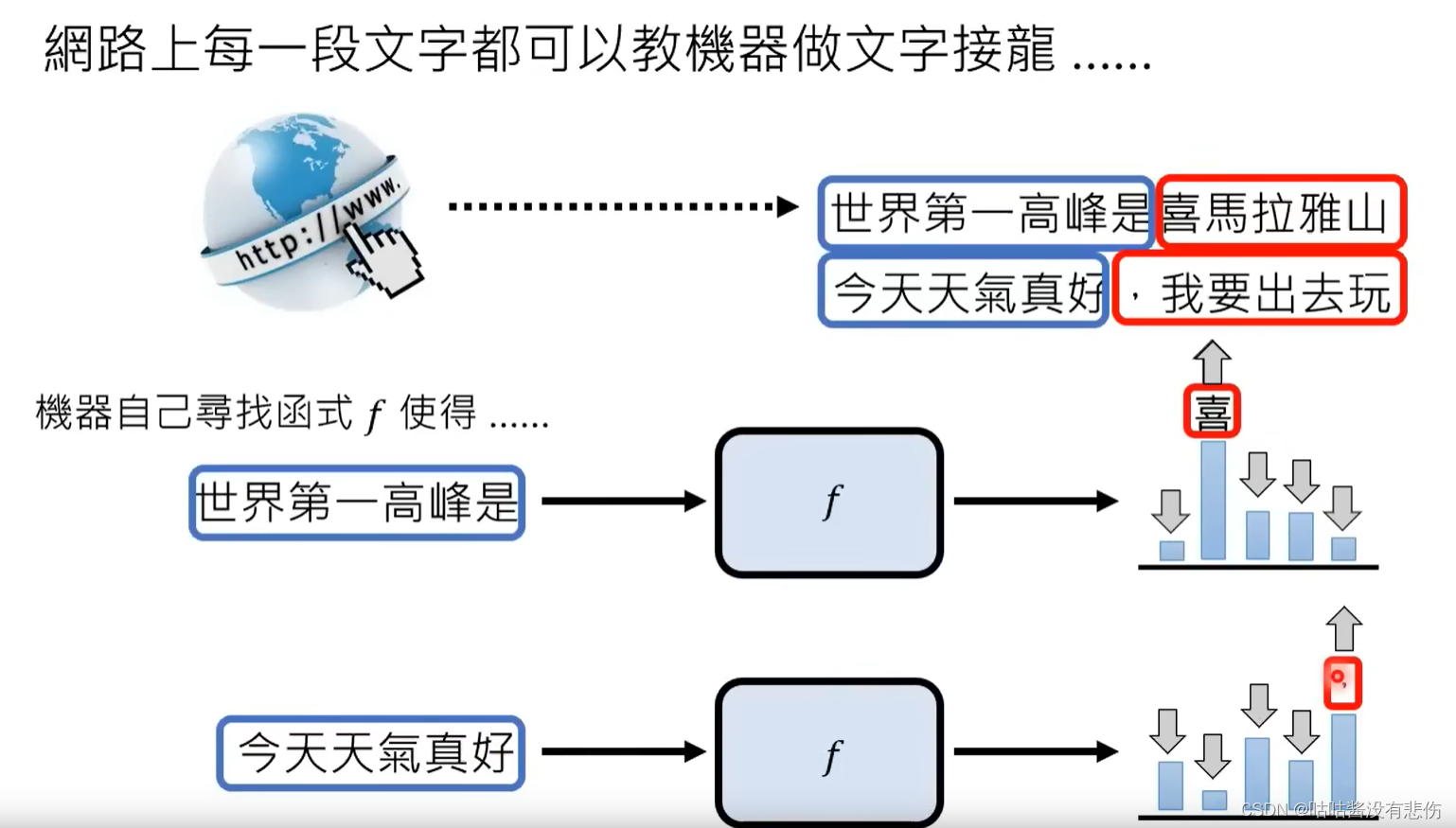
预训练技术的出现动机:人类能给出的带标签的训练数据是非常有限的,是成本很高的。
ChatGPT所需的对话数据,如果人工给出则非常耗时,但是其实网络上的每一段文字都能够作为文字接龙的训练数据。eg. [世界第一高峰是(input)] [喜马拉雅山(output)]。如果我们能让机器自己学习这些数据,就可以大大提高效率。
ChatGPT的历史
一代GPT-2018年。二代GPT-2019年。三代GPT-2020年(数据量已经到达了570GB)。ChatGPT是在三代GPT(GPT3)的基础上,补充了一些人为标注的数据集,然后训练的。
ChatGPT的结构
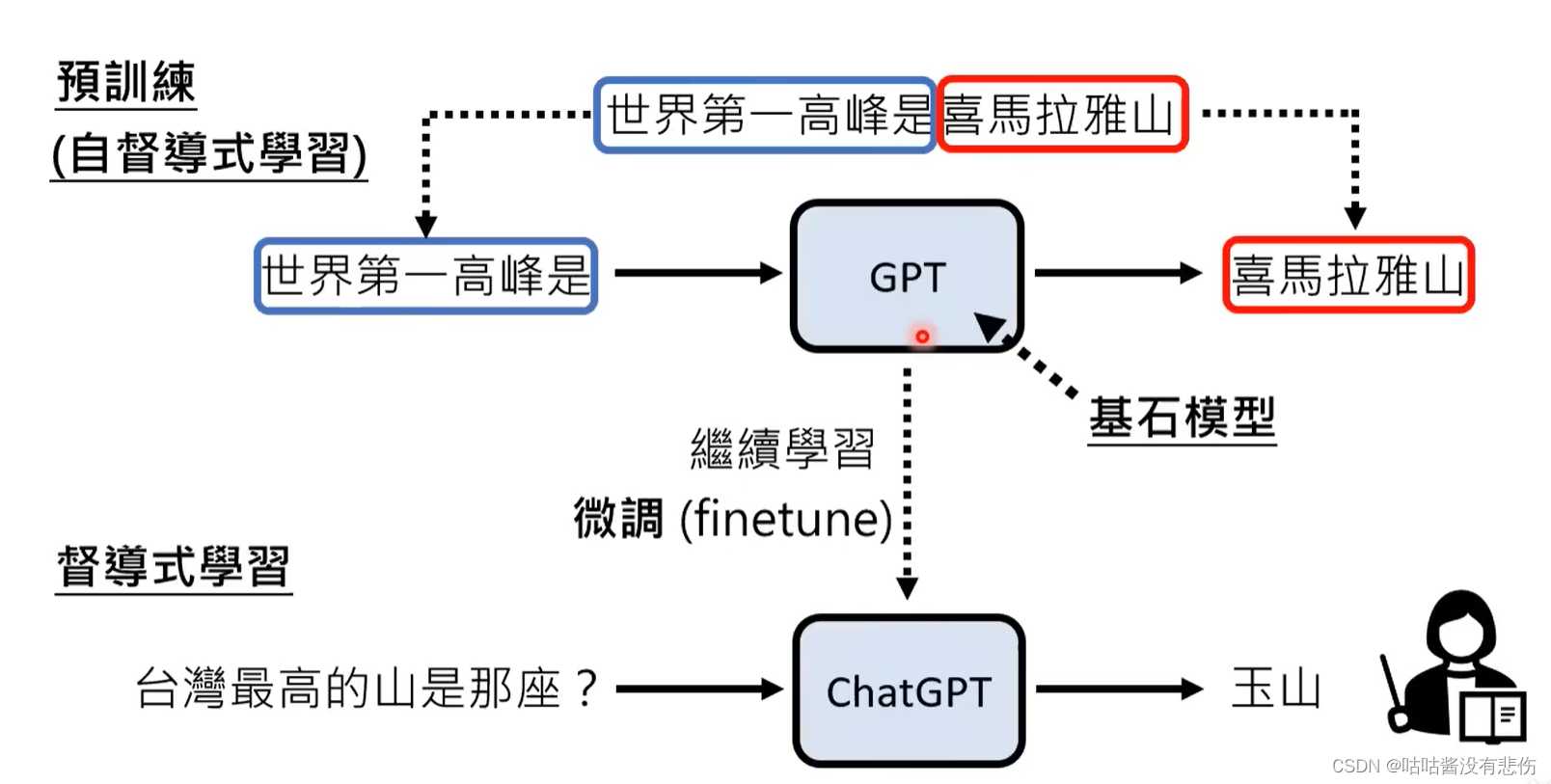
GPT是纯靠预训练而成的基石模型。在GPT的基础上,加上监督学习(ie. 带标签数据)和增强学习(ie. 告诉机器它的输出是√还是×),训练成了ChatGPT(这一过程叫做微调)。
ChatGPT的有趣
网络上有许多调教ChatGPT的教程。
ChatGPT还可以结合midjourney,生成剧情游戏(视频里演示了一个,有一点点点无聊)。

ChatGPT带来的研究问题
- 如何精确提出需求,让ChatGPT精准回答?——使用催眠prompting
- 如何更正ChatGPT的错误/更新2021年之后的信息?——Neural editing
- 如何侦测AI生成的物件?
- ChatGPT不小心泄露秘密怎么办?——machine unlearning

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)