
归因分析计算因子贡献度常见的方法
在归因分析中,我们一般都需要计算出每个因子的贡献度是多少,比如产品DAU上升,对年龄段维度进行拆解,看是不同年龄段的用户对DAU上升的贡献度是多少,一般根据指标的类型,计算贡献度的方法也不一样,下面就列出一些常见的归因分析贡献度的计算方法。
在归因分析中,我们一般都需要计算出每个因子的贡献度是多少,比如产品DAU上升,对年龄段维度进行拆解,看是不同年龄段的用户对DAU上升的贡献度是多少,一般根据指标的类型,计算贡献度的方法也不一样,下面就列出一些常见的归因分析贡献度的计算方法。
目录
2.5、加法-加权占比法:M=A+B+C(纵向对比,分解维度)
2.7、mdrca法:Multi-Dimensional Root Cause Analysis
1、指标类型
指标类型一般可以直接分为两类,原子指标和复合指标,原子指标就是DAU、GMV这种单值,不依赖其他变量独立统计的指标。复合指标是在原子指标上进行数学计算加工,需要通过两个或多个变量做除法计算的指标,比如购买率=购买人数/浏览商品人数。
2、贡献度计算
2.1、替代法:A/B或者A*B*C类型指标
2.1.1、连环替代法
公式定义:
假设核心经营指标及计算公式为:M = a * b *c,
对比周期指标值为 M1 = a1 * b1 * c1,本期指标值为 M2 = a2 * b2 * c2;本期对比上期的偏移量为 M2 - M1
确定先后替换顺序为:a、b、c,找出最大的核心指标影响因子
先替换a,得到Ma = a2 * b1 * c1,那么因子a对核心指标的影响为 Ha = Ma - M1
再替换b,得到Mb = a2 * b2 * c1,那么因子b对核心指标的影响为 Hb = Mb - Ma
再替换c,得到Mc = a2 * b2 * c2,那么因子c对核心指标的影响为 Hc = Mc - Mb
比较影响因子a、b、c对核心指标的影响值Ha、Hb、Hc的大小,其中各因子的差异值之和等于核心指标差异值(Ha + Hb + Hc = M2 - M1),从而找到影响核心指标最大的因素。
进一步Ha / (M2 - M1)可以表示a指标带来的影响比例大小。跟预期相比,M2 - M1这么大差额由于a指标降低(提升)的影响,对实际总指标M造成了Ha大小的损失(提高)
优势&局限性:
优势:通过上面的拆解可以发现,该方法满足所有下级指标的波动之和等于核心指标的波动,使得波动可以用瀑布图完美呈现。
局限:
● 贡献值的大小与替换顺序强相关,甚至会因为替换顺序的改变影响贡献值的排序结果;虽然理论上可以通过数量指标-质量指标-价值指标的顺序来尽量保证结果的可靠性,但对于大部分产品用户而言并不一定清楚了解内在逻辑并如此配置,会导致结论严谨性受损。
● 无法保证下级指标的贡献度在[-100%,100%]的范围,业务解释性较差
2.1.2、控制替代法
公式定义
控制其他指标不变,替换a指标,得到Ma = a2*b1*c1,那么因子a对核心指标的影响为 Ha = Ma - M1
控制其他指标不变,替换b指标,得到Mb = a1*b2*c1,那么因子b对核心指标的影响为 Hb = Mb - M1
控制其他指标不变,替换c指标,得到Mc = a1*b1*c2,那么因子c对核心指标的影响为 Hc = Mc - M1a指标的贡献度可以计算为:Contri_a = Ha/|Ha|+|Hb|+|Hc|
b指标的贡献度可以计算为:Contri_b = Hb/|Ha|+|Hb|+|Hc|
c指标的贡献度可以计算为:Contri_c = Hc/|Ha|+|Hb|+|Hc|
优势&局限性:
● 替换顺序的影响被消除,无论先替换哪个指标,因子贡献值的组合唯一。
● 每个因子的贡献值均落在[-100%,100%]的范围,业务解释性更强。
● 无法保证各指标影响之和为指标本身偏差。
2.2、加法-直接拆解:M=A+B+C
公式定义
1、基期
,本期
,差额=
2、计算不同因素单独变动带来的影响数:如因素带来的变动
3、总变动
4、确定每个因素的影响占比:
| GMV异动诊断 | 总GMV | 商品1 | 商品2 |
| 当前 (A) | 20000 | 10000 | 10000 |
| 基期 (B) | 18000 | 9500 | 8500 |
| DIFF(A-B) | 2000 | 500 | 1500 |
| 贡献度 | / | 25% | 75% |
2.3、乘法-log转化:M=A*B*C
公式定义:
1、基期
,本期
,其中
2、对
3、因为
,所以上述公式抵消后可得:
4、
推导确定每个因素影响占比:
;
;
2.4、超均贡献计算法:原子指标
超均贡献度的提出是为解决原子指标单看变化的绝对量级(偏移量、偏移量占比)和变化的相对快慢(波动率)导致的不准确问题:
-
用变化的绝对量级进行根因定位:会导致量级较大的维度因子长期排在前列,可能无法识别非头部因子带来的影响。
-
用变化的相对快慢进行根因定位:会导致量级较小但波动剧烈的因子排在前列,忽略了量级影响。
超均贡献度提供了一个综合变化量和波动率的量化依据,用于衡量维度因子对指标整体波动的贡献占比,较单独查看波动率和偏移量数值而言,综合两方面因素更为科学准确。
贡献度详细解释如下:
当前按超均法判断超过指标大盘的因子:
(1)计算超均贡献值=(因子波动率-指标波动率)* 因子本期值
(2)因子贡献度 = 因子贡献值/维度下所有因子贡献值绝对值之和
即将维度下所有因子的贡献值,进行归一化,量化为100%以下的百分数,作为贡献度
举个例子:

1、超均贡献值:
2、超均贡献度:
超均贡献度的解释性
超均贡献度可以理解为“因子波动与指标值(均值)波动差异的相对大小”,超均贡献度越大,说明因子的变化偏离均值变化越大,越有可能是根因。
指标波动有上升或下降,因此贡献度也有正和负之分,全部维度因子贡献度加总约为0%。在查看原因时,更关注与指标值同向变化的维度因子。
-
当指标波动上涨时,例如指标波动率为 +20%,正向贡献较大的因子将会排在头部,如TOP1影响因子很可能为贡献度>30%的某因子。
-
当指标波动下降时,例如指标波动率为 -20%,负向贡献较大的因子将会排在头部,如TOP1维度因子很可能为贡献度<-30%的某因子。
但是,超均贡献度主要的意义还是在于(排序)定位因子,数字本身实际的解释性还有待加强。
2.5、加法-加权占比法:M=A+B+C(纵向对比,分解维度)
基本逻辑:逻辑与绝对值指标归因类似,但是要考虑维度权重。
1、基本逻辑:逻辑与绝对值指标归因类似,但是要考虑维度权重
2、计算每个子维度的加权本期和加权基期:如子维度
,加权基期=子维度
权重
权重
3、计算每个子维度下的变动,
=加权本期-加权基期
4、总变动
5、确定每个因素的影响占比:
| CTR异动诊断 | 整体 | 页面1 | 页面2 | 页面3 | |
| 本期 | 曝光占比 | 100% | 14.2% | 32.3% | 53.5% |
| ctr | 13.0% | 4.4% | 17.9% | 12.3% | |
| 加权本期(A) | 13.0% | 0.63% | 5.78% | 6.59% | |
| 基期 | 曝光占比 | 100% | 15.0% | 35.5% | 49.5% |
| ctr | 15.2% | 5.1% | 18.7% | 15.8% | |
| 加权基期(B) | 15.2% | 0.76% | 6.63% | 7.8% | |
| DIFF(A-B) | -2.2% | -0.13% | -0.85% | -1.22% | |
| 贡献度 | / | 6% | 39% | 55% | |
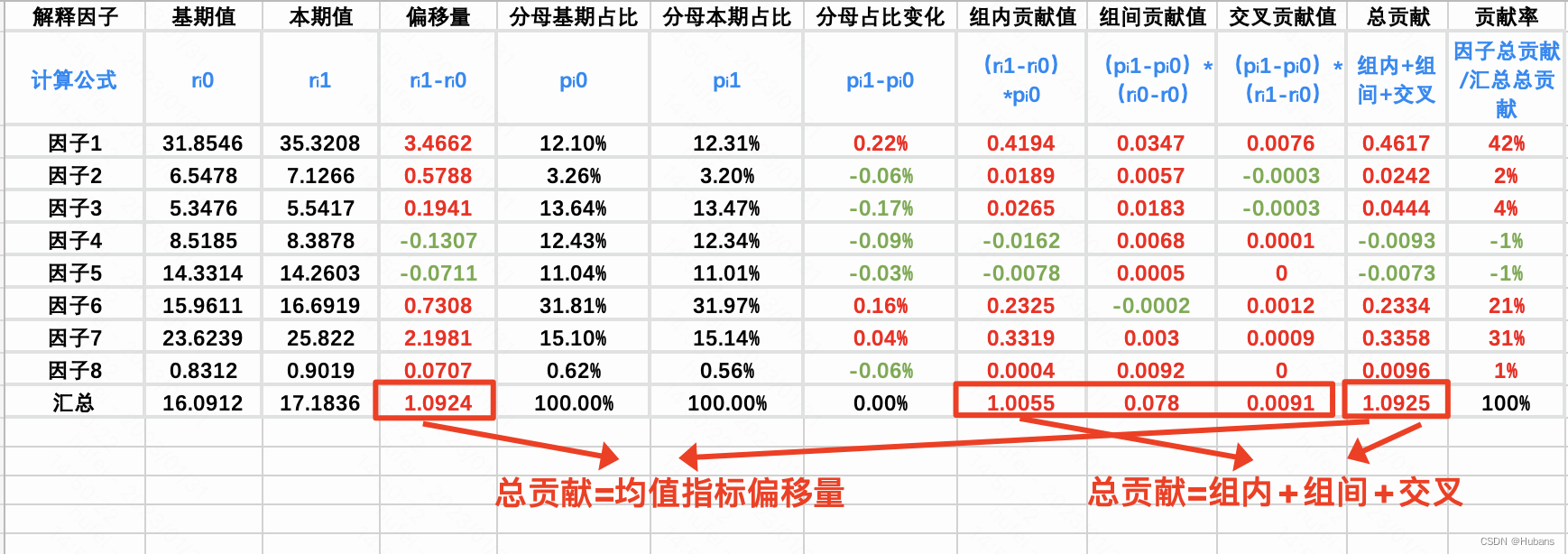
2.6、综合贡献计算法:均值指标,A/B指标
提出用综合贡献来度量维度因子对均值指标的影响大小的出发点有二:
-
由于均值指标在不同维度上的不可加和性(比如各商品类目的客单价加和不等于总的客单价),无论是使用偏移量还是超均贡献度,均无法准确度量不同因子对均值指标的影响程度
-
均值指标的波动分析往往存在“辛普森悖论”问题,比如指标整体下降但维度下各细分因子均上升,因此需要区分结构内和结构外两种变动的影响。

计算公式:

可以发现,均值指标本身的变化可以拆解为三部分:
-
组间贡献值:衡量结构变化(因子分母占比变化)对指标变化的影响。
-
组内贡献值:衡量因子量级变化对指标变化的影响。
-
交叉贡献值:衡量组间和组内交叉效应对指标带来的变化影响,属于高阶项,一般可忽略。
上述拆解方式存在以下优点:
-
可同时衡量结构内和结构外的变动,避免分析均值指标波动时产生“辛普森悖论”。
-
不同贡献值之间完全可加和,加和等于指标本身的变动,可量化为0-100%的贡献度,易于理解。
-
无需单独查看分子和分母的变动影响,通过不同贡献值即可对均值指标进行维度拆解。
举个例子
2.7、mdrca法:Multi-Dimensional Root Cause Analysis
随着业务扩展,业务模块间的关系愈加复杂。通过单一对象的指标反映的状态已不能满足业务监控需求。业务异常往往体现在多个对象的指标异常,用户收到告警后需要在大量指标数据中剥丝抽茧般地分析异常原因。
由于该归因分析方法属于算法范畴,原理较为复杂且实现难度较高,感兴趣的同学可以去网上找相关的文章阅读。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)