
Python中groupby函数详解(非常容易懂)
Python中groupby函数详解(非常容易懂)
一键AI生成摘要,助你高效阅读
问答
·
目录:Python中的groupby函数
一、groupby 能做什么?
groupby函数主要的作用是进行数据的分组以及分组后地组内运算!
于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下:
df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式——函数名称)
举例如下:
print(df["评分"].groupby([df["地区"],df["类型"]]).mean())
上面语句的功能是输出表格所有数据中不同地区不同类型的评分数据平均值。
二、单类分组
2.1 创建数据集
lst1 = [['小红', '女', 1, 160], ['大红', '女', 2, 161], ['小明', '男', 1, 180], ['大明', '男', 1, 180], ['小亮', '男', 2, 170]]
lst2 = [['姓名', '性别', '班级', '身高']]
data = pd.DataFrame(lst1, columns = lst2)
data

data.groupby("性别")
结果为:
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000018CD0F0AB90>
首先,我们有一个变量data,数据类型是DataFrame
想要按照【性别】进行分组
得到的结果是一个groupby对象,还没有进行任何的运算。
我们可以描述组内数据的基本统计量:
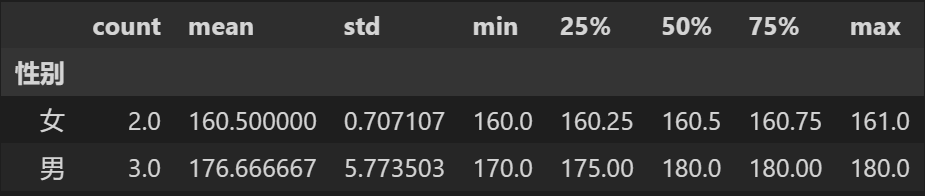
data.groupby('性别').describe()

只有数字类型的列数据才会计算统计;
示例里面数字类型的数据有两列 【班级】和【身高】;
但是,我们并不需要统计班级的均值等信息,只需要【身高】,所以做一下小的改动:
data.groupby('性别')['身高'].describe()
三、多类分组
data.groupby(['班级', '性别'])

data.groupby(['班级', '性别']).mean()
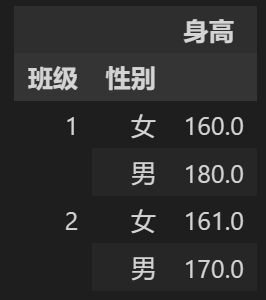
单独用groupby,我们得到的还是一个 Groupby对象。
我们还可以一次运用多个函数计算:
import numpy as np
data.groupby( ["班级","性别"]).agg([np.sum, np.mean, np.std])


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 22
22 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)