
SQL Server中row_number函数用法介绍
> - PARTITION BY子句将结果集划分为分区。 ROW_NUMBER()函数分别应用于每个分区,并重新初始化每个分区的行号。> - PARTITION BY子句是可选的。如果未指定,ROW_NUMBER()函数会将整个结果集视为单个分区。> - ORDER BY子句定义结果集的每个分区中的行的逻辑顺序。 **ORDER BY子句是必需的**,因为ROW_NUMBER()函数对顺序敏感
一、SQL Server Row_number函数简介
ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数。 行号以每个分区中第一行的行号开头。
语法实例:
select *,row_number() over(partition by column1 order by column2) as n
from tablename
在上面语法中:
- PARTITION BY子句将结果集划分为分区。 ROW_NUMBER()函数分别应用于每个分区,并重新初始化每个分区的行号。
- PARTITION BY子句是可选的。如果未指定,ROW_NUMBER()函数会将整个结果集视为单个分区。
- ORDER BY子句定义结果集的每个分区中的行的逻辑顺序。 ORDER BY子句是必需的,因为ROW_NUMBER()函数对顺序敏感
二、Row_number函数的具体用法
1.使用row_number()函数对结果集进行编号
示例:
对test_user表的查询结果标记行号,并新增 “编号”列返回
-- 使用 ROW_NUMBER()函数对结果进行编号
select ROW_NUMBER() over(order by id) as 编号,*
from test_user;
运行结果:
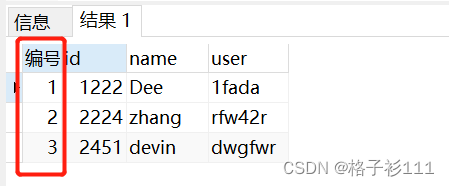
可以看到,查询结果新增了一列,专门用来标记行号。
有了编号,我们就可以方便地进行分页查询了,如何操作,可参考另外篇文章:sqlServer如何实现分页查询
2.对结果集按照指定列进行分组,并在组内按照指定列排序
示例:
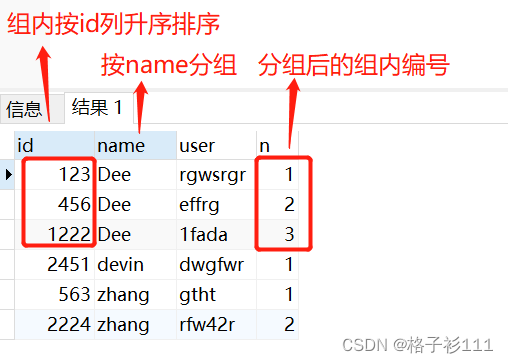
把test_user表的name按照小组进行分组显示,分组后在组内进行从低到高id排序
-- 使用partition by对结果集进行分组
select *,row_number() over(partition by name order by id) as n
from test_user;
运行结果:
3.对结果集按照指定列去重
示例:
对 test_user表按name进行分组显示,结果集中只显示每组中一条 id最小的数据
select a.* from (
select *,row_number() over(partition by name order by id) as row_id from test_user
) as a
-- 只查询组内编号为1的数据
where a.row_id<2;
运行结果:

查询结果先是经过name分组,然后组内进行id升序排序,组内编号为1的第1条数据,自然就是id最小的数据。
注意:
当我们按成绩分数查询名次等需求时,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果。这个时候就要用到另外一个函数,rank()和dense_rank()。
rank()和dense_rank()区别:
1、RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,4······
2、DENSE_RANK()
这就是题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,2······

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 17
17 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)