
LSTM进行时间序列预测——训练,验证,测试
最近一直在忙这个时间序列数据的预测,起初一直搞不清测试集和验证集的作用,最近看了很多资料,稍微有了点理解,基于自己的理解和网上的代码,刚刚基于我的需求跑出了想要的结果,虽然数值上误差还很大,不过老师说预测数据的好坏是比较出来的,所以我现在能跑出个结果还是很大的进步~接下来我就把我的代码放在下面记载一下自己的学习过程。这就好比是数据归一化处理之后,没有反归一化,那么这样预测的数据是没有意义的。这个数
最近一直在忙这个时间序列数据的预测,起初一直搞不清测试集和验证集的作用,最近看了很多资料,稍微有了点理解,基于自己的理解和网上的代码,刚刚基于我的需求跑出了想要的结果,虽然数值上误差还很大,不过老师说预测数据的好坏是比较出来的,所以我现在能跑出个结果还是很大的进步~接下来我就把我的代码放在下面记载一下自己的学习过程。
首先,准备数据集。这个数据集是我从某个电商插件上收集到的,原数据数据波动其实挺大的,最后用小波分析对数据进行了简单的降噪。
(后来导师说这个方法不能同时处理整个数据集,这样会导致原始数据改变,预测结果也会改变,这样的话整个预测就没有意义了。这就好比是数据归一化处理之后,没有反归一化,那么这样预测的数据是没有意义的。因为我只是想记录下整个预测过程,对数据的要求不大。所以我的这个实验直接用小波分析后的数据)
数据如下
链接:https://pan.baidu.com/s/1FY2YWZt-LuMQ3tbgNTC-GQ
提取码:zxt1
由于我找的这份代码是单步预测,意思是一次只预测一个未来值,所以我在整个数据下面增加了一个预测数据——2022/10/1,其对应的销量我设置成0,这个不写的话会报错,而且这个0本来就是未知的,我们最终会预测出来2022/10/1对应的预测值

下面是相关代码——代码是基于Jupyter notebook来编写的。
1、导入相关库
import numpy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import pandas as pd
import os
from keras.models import Sequential, load_model
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from math import sqrt2、数据处理,划分训练集、验证集、测试集
dataframe = pd.read_csv(r"D:\桌面文件夹哦\数据统计\悠度数据\2特征.CSV", usecols=[1], engine='python')
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
# 归一化
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * 0.8)
trainlist = dataset[:-40]
validlist = dataset[-40:-3]
testlist = dataset[-3:]这里面validlist表示验证集,testlist表示测试集,因为代码中是用两个值预测下一个值,所以“testlist = dataset[-3:]”表示以第“-3”行和第“-2”行这两个数据来预测最后那个数据,即2022/10/1日的数据。
3、定义数据集处理函数
def create_dataset(dataset, look_back):
# 这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX), numpy.array(dataY)4、设置训练、验证、测试数据
# 训练数据太少 look_back并不能过大
look_back = 1
trainX, trainY = create_dataset(trainlist, look_back)
validX, validY = create_dataset(validlist, look_back)
testX, testY = create_dataset(testlist, look_back)
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
validX = numpy.reshape(validX, (validX.shape[0], validX.shape[1], 1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1], 1))5、设置并训练LSTM函数
model = Sequential()
model.add(LSTM(100, input_shape=(None, 1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=10, verbose=2)
model.save("D:\桌面文件夹哦\预测模型保存")这里的“model.save("D:\桌面文件夹哦\预测模型保存")”可以保证随时调用训练好的模型,而不用每次都重新训练;此外,对于这个模型的保存,有的是采用OS模块,保存为后缀为.h5格式,但是我试了很久都没有成功,最后采用我的土方法保存了下来,这个只需要在桌面新建一个文件夹,然后把文件夹的地址放在上面即可,后来就可以随时调用~
6、做验证、预测
# 做验证和预测
model = load_model(r"D:\桌面文件夹哦\预测模型保存")
trainPredict = model.predict(trainX)
validPredict = model.predict(validX)
testPredict = model.predict(testX)
# 反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
validPredict = scaler.inverse_transform(validPredict)
validY = scaler.inverse_transform(validY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
print(testPredict)7、做图,评估
因为本文我增加了验证集,所以就根据验证集的预测结果来进行预测结果衡量~
plt.plot(trainY)
plt.plot(trainPredict[1:])
plt.show()
plt.plot(validY)
plt.plot(validPredict[1:])
plt.show()
r_2 = r2_score(validY, validPredict)
print('Test r_2: %.3f' % r_2)
# 计算MAE
mae = mean_absolute_error(validY, validPredict)
print('Test MAE: %.3f' % mae)
# 计算RMSE
rmse = sqrt(mean_squared_error(validY, validPredict))
print('Test RMSE: %.3f' % rmse)最后的结果如下
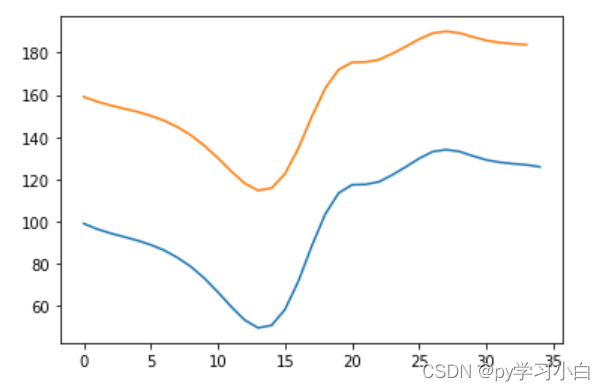
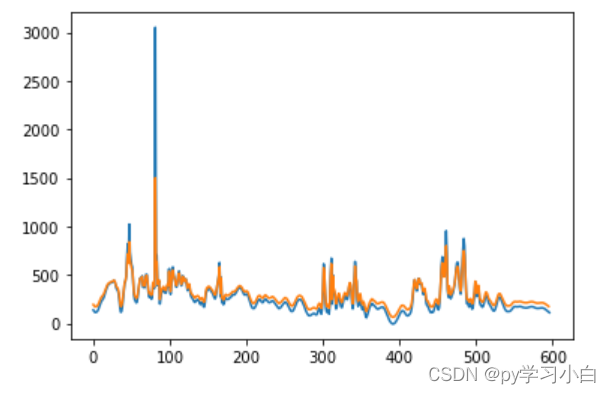


其实结果不是很好,r_2的值是负的,说明预测效果还不如直接用平均值代替预测值。但是这个思路还行,我好歹是出结果了。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)