Nesterov 加速算法
Nesterov 加速算法的介绍~
Nesterov 加速算法
梯度下降是我们在优化或者深度学习中经常要用到的算法,基于最原始的梯度下降算法,有很多加速算法被提出,今天我们着重介绍Nesterov 加速算法。
Nesterov 加速算法可以在理论上证明有比梯度下降更快的收敛率,本文不会重点介绍收敛率的证明,而是会通过一些推导从几何直观上给出为什么使用Nesterov 的技术可以对原来的算法起到加速的作用。
梯度下降
对于优化目标
min x ∈ R n f ( x ) \min _{x \in \mathbb{R}^n} f(x) x∈Rnminf(x)
原始的梯度下降的方法是随机选取一个初始点 x x x,然后选取合适的步长按以下公式更新 x x x :
x k + 1 = x k − α k ∇ f ( x k ) x^{k+1}=x^k-\alpha_k \nabla f\left(x^k\right) xk+1=xk−αk∇f(xk)
可以证明当 f f f 和 α k \alpha_k αk 满足以下条件时:
- 设函数 f ( x ) f(x) f(x) 为凸的梯度 L L L-利普希茨连续函数
- 极小值 f ∗ = f ( x ∗ ) = inf x f ( x ) f^*=f\left(x^*\right)=\inf _x f(x) f∗=f(x∗)=infxf(x) 存在且可达.
- 如果步长 α k \alpha_k αk 取为常数 α \alpha α 且满足 0 < α < 1 L 0<\alpha<\frac{1}{L} 0<α<L1
点列 { x k } \left\{x^k\right\} {xk} 的函数值收敛到最优值, 且在函数值的意义下收敛速度为 O ( 1 k ) \mathcal{O}\left(\frac{1}{k}\right) O(k1). 这里我们不做证明,具体证明可以参考这个PPT。
动量梯度下降
在梯度下降中添加动量的想法很简单,想想求凸函数最小值的梯度下降法是一个小球在下山的过程,添加动量就是将小球真的看做一个有质量的小球,每次除了向梯度方向移动,还要沿着原有方向移动一点,这样可以让梯度下降更加平稳地到达极小值点。
d k = β k d k − 1 + ∇ f ( x k ) x k + 1 = x k − α k d k \begin{aligned} &d_k=\beta_k d_{k-1}+ \nabla f\left(x^k\right) \\ &x^{k+1}=x^k-\alpha_k d_k \end{aligned} dk=βkdk−1+∇f(xk)xk+1=xk−αkdk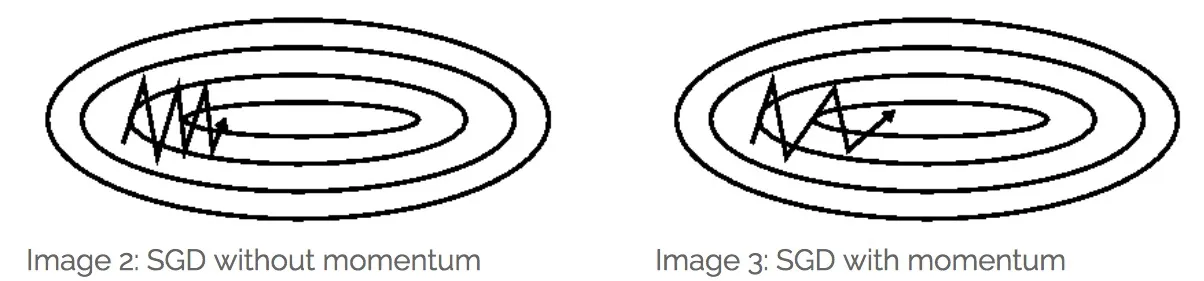
Nesterov 梯度下降
Nesterov 加速算法有很多种不同的表示方式,但基本是等价的,Nesterov算法的想法是在动量算法的基础上, α k β k d k − 1 \alpha_k\beta_k d_{k-1} αkβkdk−1 是无论如何都要走的距离,那我们就直接用走出去以后前方的梯度来代替动量算法中的当前梯度,更新公式如下:
d k = β k d k − 1 + ∇ f ( x k − α k β k d k − 1 ) x k + 1 = x k − α k d k \begin{aligned} &d_k=\beta_k d_{k-1}+ \nabla f\left(x^k-\alpha_k\beta_k d_{k-1}\right) \\ &x^{k+1}=x^k-\alpha_k d_k \end{aligned} dk=βkdk−1+∇f(xk−αkβkdk−1)xk+1=xk−αkdk
这里我们给出另一个版本的Nesterov加加速算法:
y k = ( 1 − γ k ) x k − 1 + γ k v k − 1 v k = v k − 1 − t k γ k ∇ f ( y k ) x k = ( 1 − γ k ) x k − 1 + γ k v k \begin{aligned} y^k &=\left(1-\gamma_k\right) x^{k-1}+\gamma_k v^{k-1} \\ v^k &=v^{k-1}-\frac{t_k}{\gamma_k} \nabla f\left(y^k\right) \\ x^k &=\left(1-\gamma_k\right) x^{k-1}+\gamma_k v^k \end{aligned} ykvkxk=(1−γk)xk−1+γkvk−1=vk−1−γktk∇f(yk)=(1−γk)xk−1+γkvk
整理后不难发现上式等价于:
y k = x k − 1 + γ k ( 1 γ k − 1 − 1 ) ( x k − 1 − x k − 2 ) x k = y k − t k ∇ f ( y k ) \begin{aligned} y^k &=x^{k-1}+\gamma_k\left(\frac{1}{\gamma_{k-1}}-1\right)\left(x^{k-1}-x^{k-2}\right)\\ x^k &= y^k - t_k\nabla f\left(y^k\right) \end{aligned} ykxk=xk−1+γk(γk−11−1)(xk−1−xk−2)=yk−tk∇f(yk)
这与我们最初定义的Nesterov 算法等价,而且我们有当参数满足以下条件时,
f ( x k ) ≤ f ( y k ) + ⟨ ∇ f ( y k ) , x k − y k ⟩ + 1 2 t k ∥ x k − y k ∥ 2 2 , γ 1 = 1 , ( 1 − γ i ) t i γ i 2 ≤ t i − 1 γ i − 1 2 , i > 1 , γ k 2 t k = O ( 1 k 2 ) . \begin{aligned} &f\left(x^k\right) \leq f\left(y^k\right)+\left\langle\nabla f\left(y^k\right), x^k-y^k\right\rangle+\frac{1}{2 t_k}\left\|x^k-y^k\right\|_2^2, \\ &\gamma_1=1, \quad \frac{\left(1-\gamma_i\right) t_i}{\gamma_i^2} \leq \frac{t_{i-1}}{\gamma_{i-1}^2}, \quad i>1, \\ &\frac{\gamma_k^2}{t_k}=\mathcal{O}\left(\frac{1}{k^2}\right) . \end{aligned} f(xk)≤f(yk)+⟨∇f(yk),xk−yk⟩+2tk1∥∥xk−yk∥∥22,γ1=1,γi2(1−γi)ti≤γi−12ti−1,i>1,tkγk2=O(k21).
可以证明点列 { x k } \left\{x^k\right\} {xk} 的函数值收敛到最优值, 且在函数值的意义下收敛速度为 O ( 1 k 2 ) \mathcal{O}\left(\frac{1}{k^2}\right) O(k21)。 这里我们依然不做证明,具体证明细节可以参考Nesterov加加速算法。我们主要想要介绍的是从知觉上解释为什么使用Nesterov之后算法会变快,虽然算法中看到了前方的梯度后再更新参数,但是正常的动量算法走一步之后也可以看到类似的梯度,从直觉上并不能很好的理解为什么快。接下来我们会将算法变换形式,从而理解Nesterov其实是一种用到了梯度的二阶信息的算法,我认为这是一种更好的理解方式。下面分析的灵感来自比Momentum更快:揭开Nesterov Accelerated Gradient的真面目,但是也许比他的适用范围更广。
首先我们令 β k = γ k + 1 ( 1 γ k − 1 ) \beta_k=\gamma_{k+1}\left(\frac{1}{\gamma_{k}}-1\right) βk=γk+1(γk1−1) ,这样我们有:
y k = x k − 1 + β k − 1 ( x k − 1 − x k − 2 ) ( 1 ) x k = y k − t k ∇ f ( y k ) ( 2 ) \begin{aligned} y^k &=x^{k-1}+\beta_{k-1}\left(x^{k-1}-x^{k-2}\right) &(1) \\ x^k &= y^k - t_k\nabla f\left(y^k\right) &(2) \end{aligned} ykxk=xk−1+βk−1(xk−1−xk−2)=yk−tk∇f(yk)(1)(2)
在 ( 2 ) (2) (2) 式左右同时加 β k ( x k − x k − 1 ) \beta_k\left(x^k-x^{k-1}\right) βk(xk−xk−1) 可以得到
y k + 1 = y k − t k ∇ f ( y k ) + β k ( x k − x k − 1 ) y^{k+1}=y^k-t_k \nabla f\left(y^k\right)+\beta_k\left(x^k-x^{k-1}\right) yk+1=yk−tk∇f(yk)+βk(xk−xk−1)
令
d k = ∇ f ( y k ) − β k t k ( x k − x k − 1 ) ( 3 ) d_k=\nabla f\left(y^k\right)-\frac{\beta_k}{t_k}\left(x^k-x^{k-1}\right)\ \quad(3) dk=∇f(yk)−tkβk(xk−xk−1) (3)
这样我们有
y k + 1 = y k − t k d k y^{k+1}=y^k-t_kd_k yk+1=yk−tkdk
由 ( 1 ) ( 2 ) ( 3 ) (1)(2)(3) (1)(2)(3) 我们有
x k − x k − 1 = β k − 1 ( x k − 1 − x k − 2 ) − t k ∇ f ( y k ) = − t k − 1 [ d k − 1 − ∇ f ( y k − 1 ) ] − t k ∇ f ( y k ) ( 4 ) \begin{aligned} x^k-x^{k-1} &=\beta_{k-1}\left(x^{k-1}-x^{k-2}\right)-t_k \nabla f\left(y^k\right) \\ &=-t_{k-1}\left[d_{k-1}-\nabla f\left(y^{k-1}\right)\right]-t_k \nabla f\left(y^k\right)\quad(4) \end{aligned} xk−xk−1=βk−1(xk−1−xk−2)−tk∇f(yk)=−tk−1[dk−1−∇f(yk−1)]−tk∇f(yk)(4)
( 4 ) (4) (4) 带入 ( 3 ) (3) (3) 我们有
d k = β k t k − 1 t k ⋅ d k − 1 + ∇ f ( y k ) + β k t k [ t k ∇ f ( y k ) − t k − 1 ∇ f ( y k − 1 ) ] \begin{aligned} d_k=&\beta_k \frac{t_{k-1}}{t_k} \cdot d_{k-1}+\nabla f\left(y^k\right)+\frac{\beta_k}{t_k}\left[t_k \nabla f\left(y^k\right)-t_{k-1} \nabla f\left(y^{k-1}\right)\right] \end{aligned} dk=βktktk−1⋅dk−1+∇f(yk)+tkβk[tk∇f(yk)−tk−1∇f(yk−1)]
可以看到这里面第一项就是动量,第二项是梯度,最后一项就是梯度的二阶信息。但是更令人困惑的是,虽然我们可以得到这样一个比较好看的形式,但是这确是 y k y^k yk 的更新方式而不是我们得到的 x k x^k xk ,虽然说后期步长比较短, y k y^k yk 和 x k x^k xk 比较接近,但是为什么 y k y^k yk 有这样形式好的更新策略但是要用 x k x^k xk ?
思考
- 迭代公式中 y k y^k yk 是否同样有收敛率的保证,或者修改一些迭代条件后能否让 y k y^k yk 有收敛率的保证?
- 在一些涉及对偶问题的算法中,对原始变量的更新是使用 y k y^k yk 的,只是为了证明方便还是真的 y k y^k yk 效果更好呢?
点赞过三后续继续更新硬核内容!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)