
DataX实现mysql全量数据同步到hdfs
DataX是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据 库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高 效的数据同步功能。
·
目录
一:什么是DataX
1.1 DataX的概述:
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据 库(MySQL 、 Oracle 等 ) 、 HDFS 、 Hive 、 ODPS 、 HBase 、 FTP 等各种异构数据源之间稳定高 效的数据同步功能。
1.2 DataX的设计:
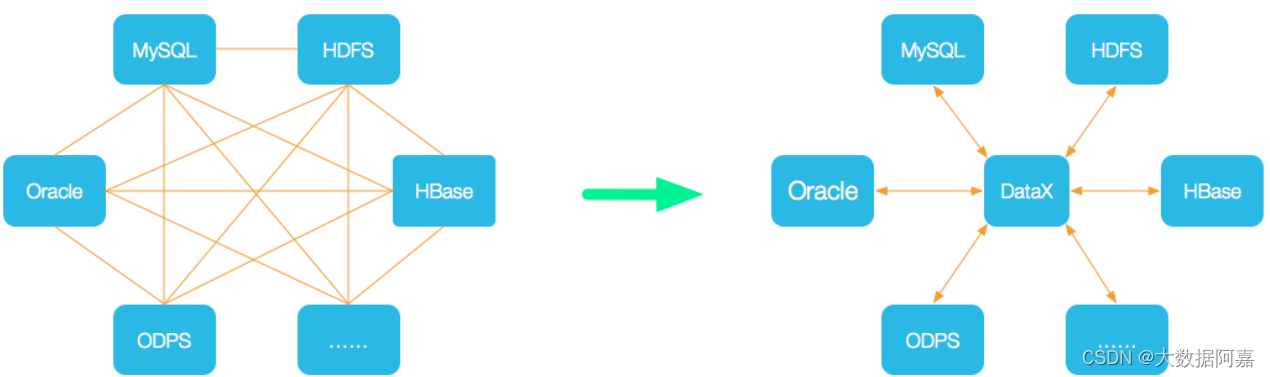
为了解决异构数据源同步问题, DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX ,便能跟已有的数据源做到无缝数据同步。
1.3 支持的数据库

1.4 框架设计:

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.5 运行原理:
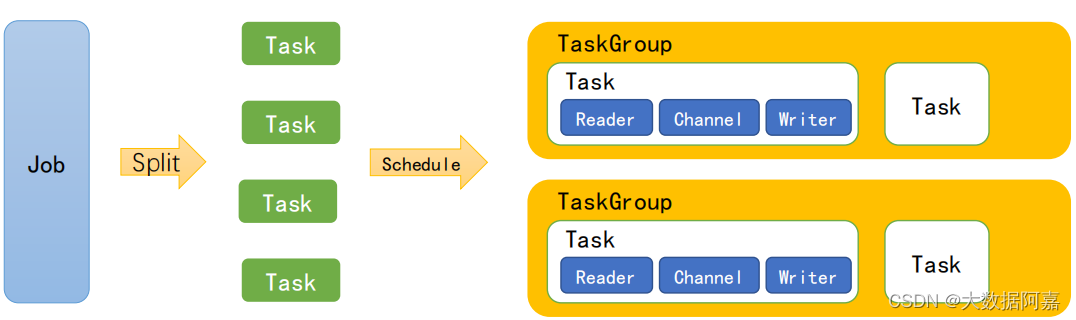
- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
举例来说,用户提交了一个
DataX
作业,并且配置了
20
个并发,目的是将一个
100
张分表的mysql
数据同步到
odps
里面。
DataX
的调度决策思路是:
1 ) DataXJob 根据分库分表切分成了 100 个 Task 。2 )根据 20 个并发, DataX 计算共需要分配 4 个 TaskGroup 。3 ) 4 个 TaskGroup 平分切分好的 100 个 Task ,每一个 TaskGroup 负责以 5 个并发共计运行25 个 Task 。
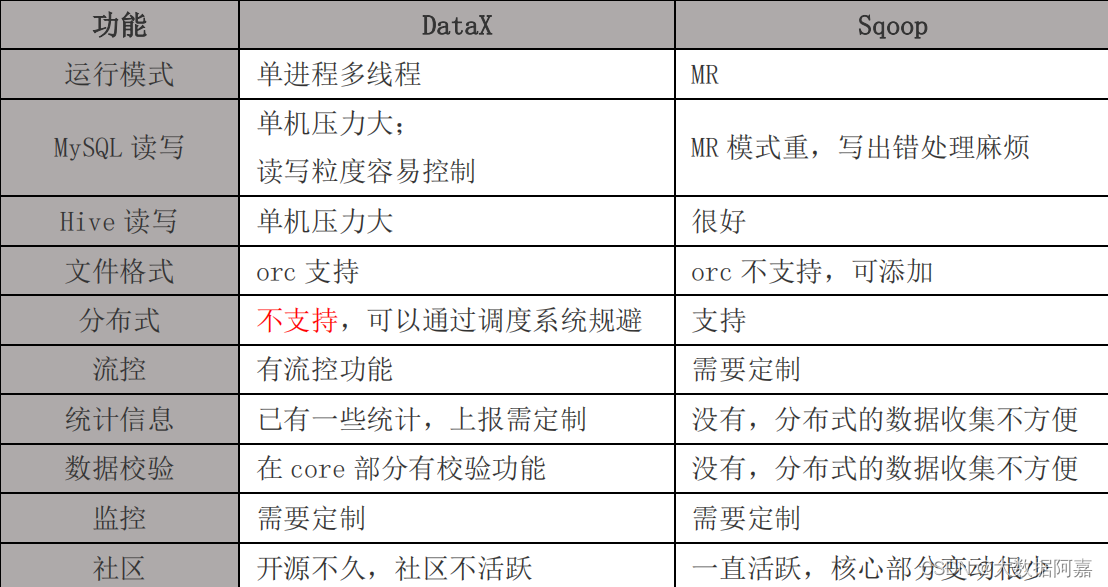
1.6 与 Sqoop 的对比
二:安装DataX
1 )将下载好的 datax.tar.gz 上传到 hadoop102 的 /opt/software2 )解压 datax.tar.gz 到 /opt/module[atguigu@hadoop102 software]$ tar -zxvf datax.tar.gz -C /opt/module/3 )运行自检脚本[atguigu@hadoop102 bin]$ cd /opt/module/datax/bin/ [atguigu@hadoop102 bin]$ python datax.py /opt/module/datax/job/job.json

出现以上内容说明安装成功。
三: 使用DataX实现mysql全量数据同步至hdfs
3.1 查看官方模板
[atguigu@hadoop102 ~]$ python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter模板如下:
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
],
"connection":[
{
"jdbcUrl":[
],
"table":[
]
}
],
"password":"",
"username":"",
"where":""
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
],
"compress":"",
"defaultFS":"",
"fieldDelimiter":"",
"fileName":"",
"fileType":"",
"path":"",
"writeMode":""
}
}
}
],
"setting":{
"speed":{
"channel":""
}
}
}
}模板解析如下:
(1)mysqlreader参数解析

(2)hdfswriter参数解析

3.2 数据准备
(自己可以生成一张表,以用测试)
1
)创建
student
表
mysql> create database datax;
mysql> use datax;
mysql> create table student(id int,name varchar(20));
2
)插入数据
mysql> insert into student values(1001,'zhangsan'),(1002,'lisi'),(1003,'wangwu');3.3 编写配置文件
[atguigu@hadoop102 datax]$ vim /opt/module/datax/job/mysql2hdfs.json配置文件如下:
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://hadoop102:3306/datax"
],
"table":[
"student"
]
}
],
"username":"root",
"password":"000000"
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"column":[
{
"name":"id",
"type":"int"
},
{
"name":"name",
"type":"string"
}
],
"defaultFS":"hdfs://hadoop102:9000",
"fieldDelimiter":"\t",
"fileName":"student.txt",
"fileType":"text",
"path":"/",
"writeMode":"append"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
}3.4 执行任务
[atguigu@hadoop102 datax]$ bin/datax.py job/mysql2hdfs.json
2019-05-17 16:02:16.581 [job-0] INFO JobContainer -
任务启动时刻 : 2019-05-17 16:02:04
任务结束时刻 : 2019-05-17 16:02:16
任务总计耗时 : 12s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 03.5 检查数据
打开hdfs的web端,查看数据是否生成
![]()
这样,就同步完成了。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)