数据系统架构-9.统一查询服务one-service
至此通过该系统基本上解决了数据查询服务统一的问题,在统一的指标管理、数据集管理的体系下,保证了数据出口逻辑的一致性。并且该系统可以支持横向扩展来适应更多的查询请求。完成支持各类数据存储的数据查询服务,提供统一、稳定、便捷、安全、可扩展的数据查询出口的系统任务。
统一查询服务one-service
1.背景
在日常的数据开发过程中,我们会把数据结果存储在各类数据库中或者导入到OLAP查询引擎中供上层应用使用。对于不同的数据库和OLAP引擎上层应用都要自行构建查询服务处理各自的数据逻辑,存在大量重复的开发工作,因此为了提升数据使用效率、减少重复性开发工作、降低开发成本,我们在各类存储引擎的基础上需要开发一套统一的数据查询服务。
2.系统目标
目标:打造支持各类数据存储的数据查询服务,提供统一、稳定、便捷、安全、可扩展的数据查询出口。
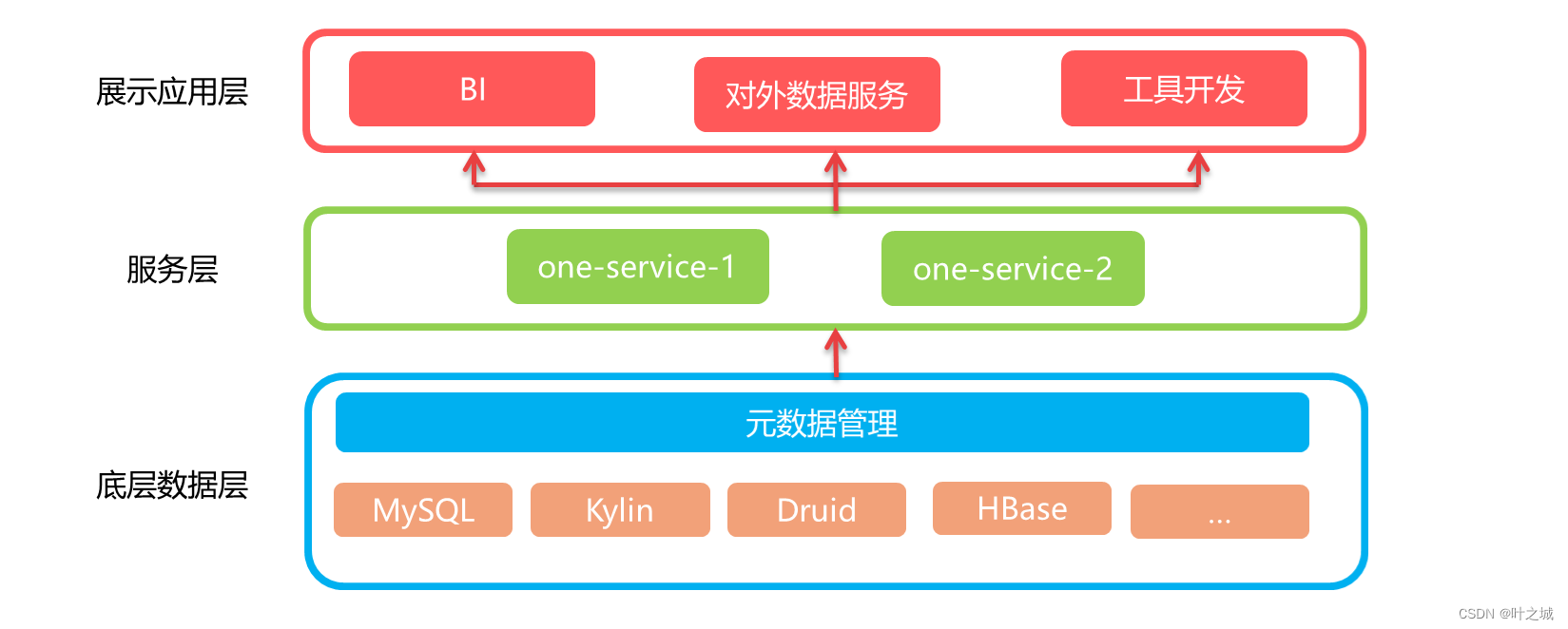
3.整体架构

- 基础数据平台:根据基础数据平台维护的各类表与指标的元信息,通过配置生成不同业务的数据集;
- 管理后台:包括数据源管理、数据集管理、数据权限管理。数据集管理是把不同的数据源的数据抽象成一个数据集合,根据存储引擎的不同采用对应的组合与配置方式,比如支持sql的存储引擎,可以通过sql来生成对应不同业务的各类数据集;
- 权限管理中台:通过话权限管理平台,用来对用的数据集权限进行管理,查询平台权限管理粒度为数据集;
- 查询服务:包括查询接口服务、后台管理服务、存储引擎查询器,以及其他辅助功能。针对不同的存储引擎会有与之对应点查询器进行数据查询支持。
4.查询引擎设计
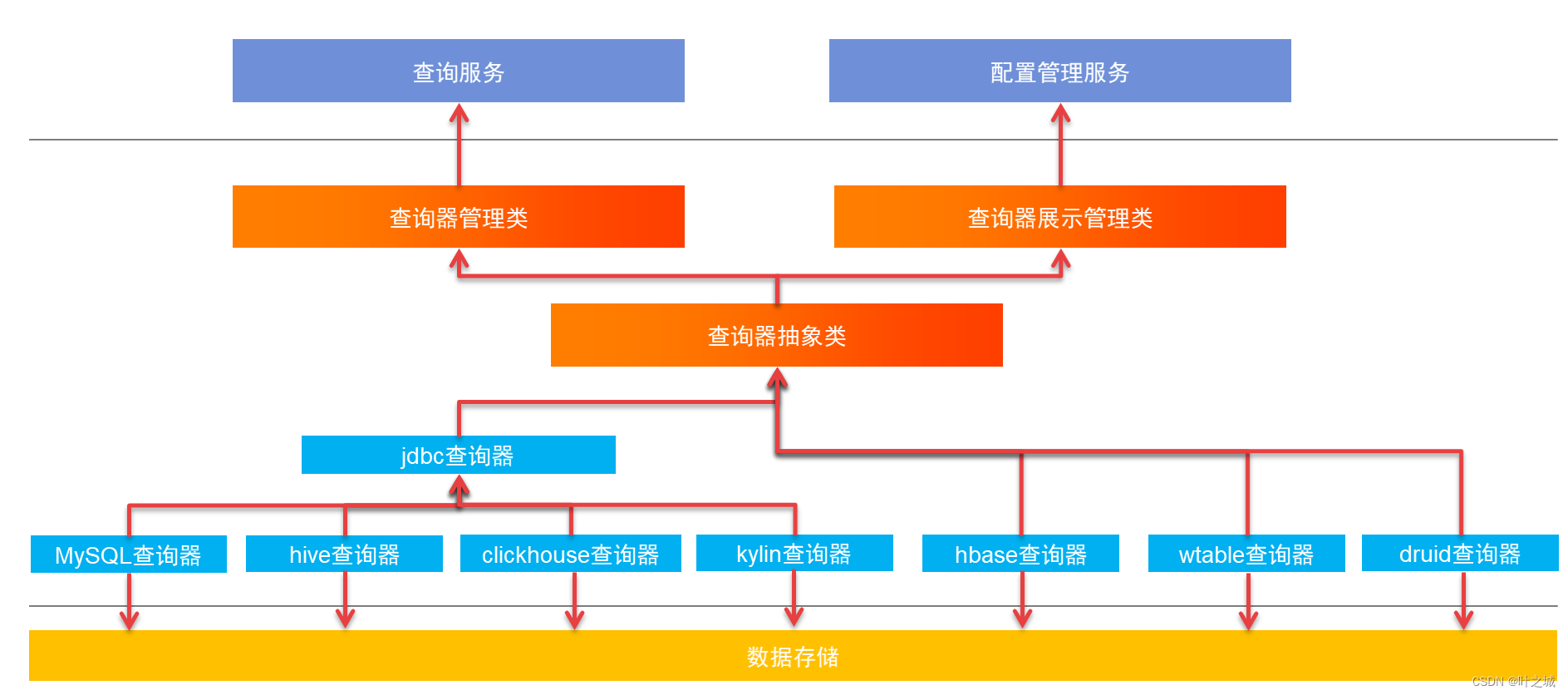
通过继承查询器抽象类的方式实现各类存储引擎的查询器,可以方便的对查询器进行管理、扩展与功能开发。同时针对不同的查询引擎可以做定制化的查询控制与优化。查询器抽象类抽象方法大致如下:
- getSchemas 获取库信息
- getTables 获取表信息
- getSetData 查询数据集数据
- queryDimVals 查询维度信息
- queryAggData 查询聚合数据
统一查询参数:上层应用通过数据集元信息,生成json格式的查询参数,包括维度、过滤、聚合、指标查询信息。后端收到对应数据集与查询信息组装对应查询逻辑,然后调用查询接口对数据进行查询与结果返回。
5.数据安全
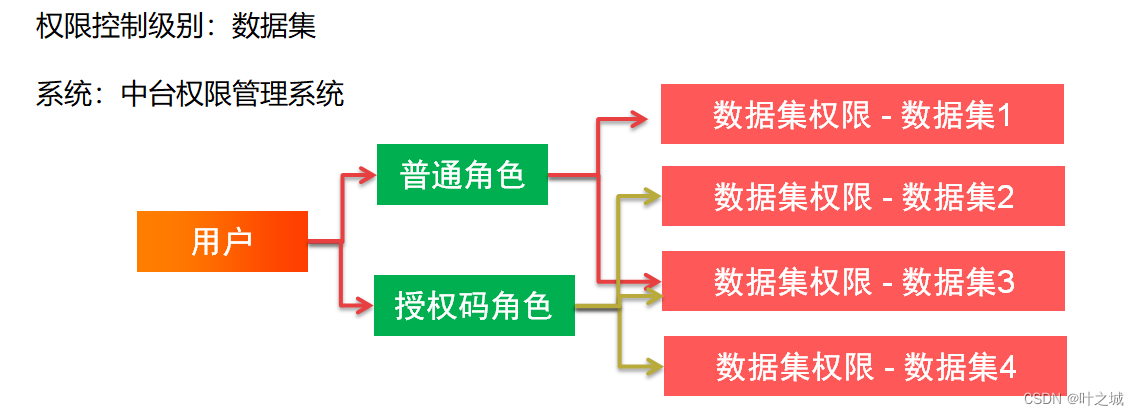
关于数据安全方面,暂时只控制到数据集粒度。通过两种方式来区分,一个种是能正常登陆认证的系统或用户,通过普通角色来管理;另一种没有用户认证的情况,采用授权码的方式来控制用户数据集的访问权限。
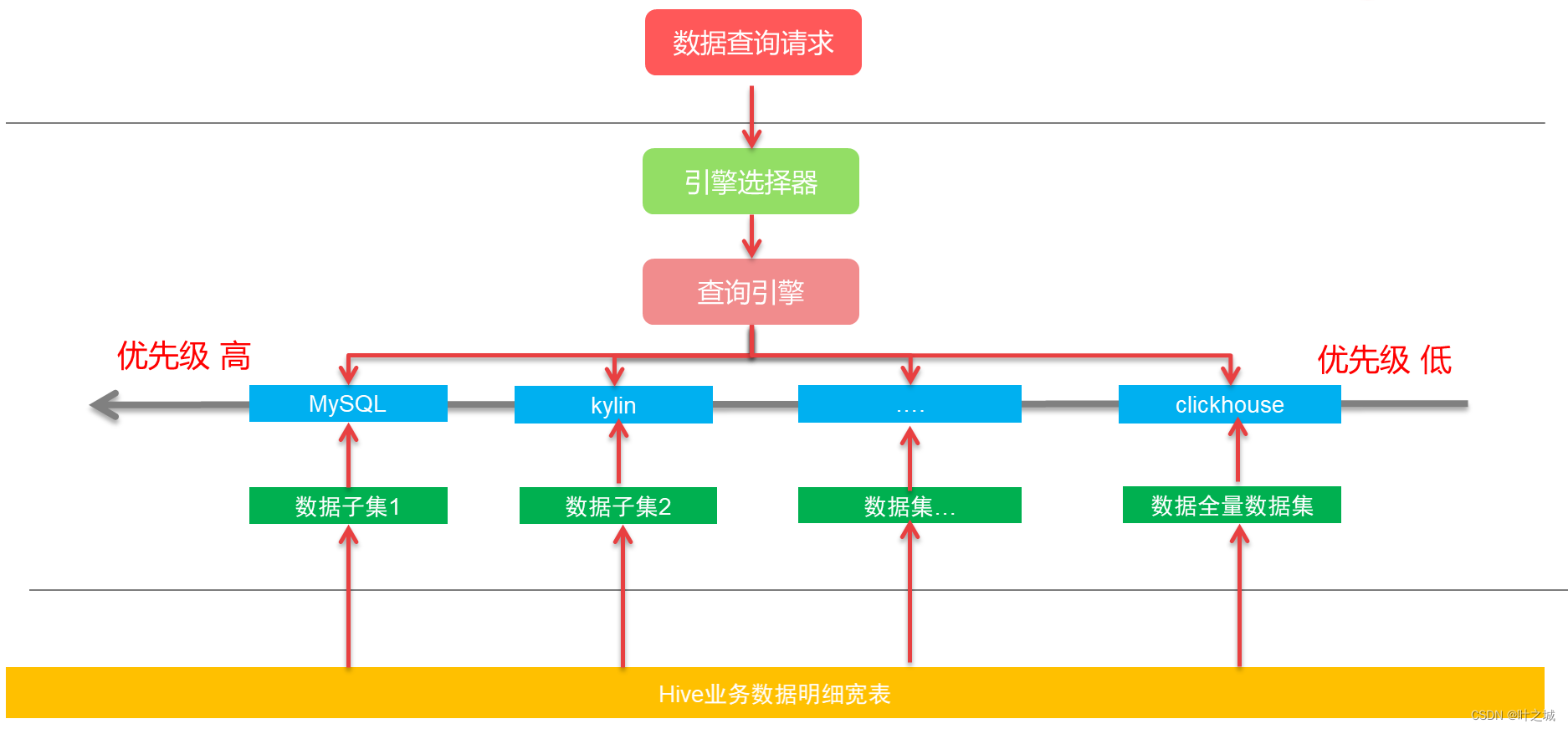
6.智能查询
各种数据库或者OLAP引擎都有着各自适用的场景,目前针对大数据并没有一个完美引擎,因此在这套查询体系里为了最大化用户体验,提升查询效率,设计根据数据集优先级,以及查询条件自动选择最适合的查询引擎来进行数据查询与加载。
- 底层宽表:比如我们在hive当中有订单主题的宽表,我们会按照业务分析场景,把宽表拆成最常用分析维度数据集,较常用维度数据集,全量数据集等数据集;
- 数据子集:根据宽表与分析场景的情况,我们会配置定义出各类数据分析子集,分析场景下的全量数据集会存储在clickhouse当中进行最后命中查询,不同维度的子集与存储引擎可以多对一进行任意优先配置与组合;
- 优先级:根据分析场景与数据量级大小,把最常用的数据集按照引擎特性分别存储在不同的数据库或者OLAP引擎当中,根据查询性能、数据量级的不同常规优先级 MySQL(高)<- kylin(中) <- clickhouse(低);
- 引擎选择器:当我们查询某一个数据集的时候,会去判断该数据集所属数据集组,在改组下有各种维度不同存储引擎下的数据集,再根据查询条件按照配置好的优先级顺序,进行匹配查询。追求最好的查询效率。
7.总结
至此通过该系统基本上解决了数据查询服务统一的问题,在统一的指标管理、数据集管理的体系下,保证了数据出口逻辑的一致性。并且该系统可以支持横向扩展来适应更多的查询请求。完成支持各类数据存储的数据查询服务,提供统一、稳定、便捷、安全、可扩展的数据查询出口的系统任务。

开源、云原生的融合云平台
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)