
Pandas中的Series对象详解(含Python代码)
Pandas中的Series对象详解(含Python代码)
1.初识Series对象
Pandas中的Series对象是一个带索引数据构成的一维数组。
可以用一个数组来创建Series对象:
import pandas as pd
data=pd.Series([1,2,3,4,5])
data
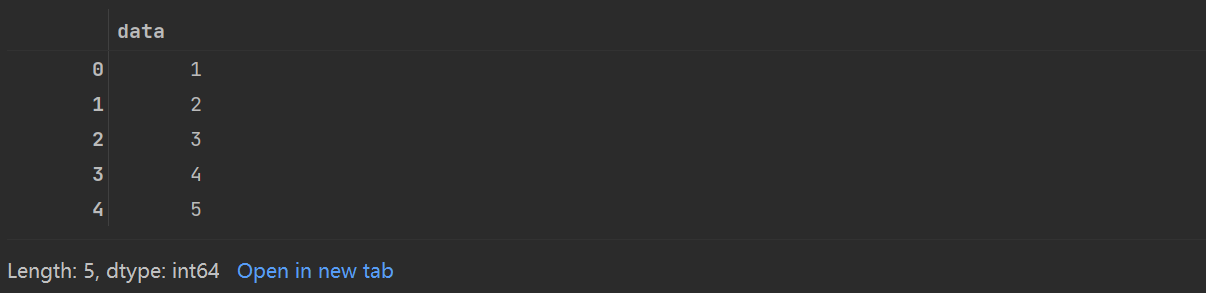
从上面的结果中,不难发现Series对象将一组对象和一组索引绑定在一起,我们可以通过values属性和index属性来获取数据。values属性返回的结果与Numpy数组类似;index属性返回的结果是一个类型为pd.Index的类数组对象。
data.index,data.values
(RangeIndex(start=0, stop=5, step=1), array([1, 2, 3, 4, 5], dtype=int64))
和Numpy数组一样,数据可以通过Python的中括号索引标签获取:
data[3]
4
data[:-3]
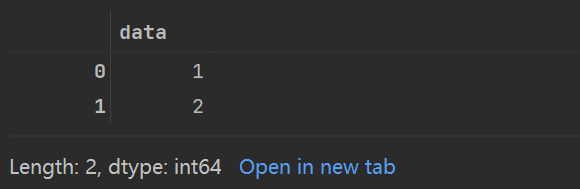
不难看出,Pandas中的Series对象比它模仿的一维Numpy数组更加通用、灵活。
2.Series是通用的Numpy数组
到目前为止,我们可能看上面的解释认为Series对象和一维Numpy数组基本可以等价交换,但两者间的本质差异是索引:
(1)Numpy数组通过隐式定义的整数索引来获取数值;
(2)Series对象用一种显式定义的索引与数值关联。
显式索引的定义让Series对象有了更强的能力。例如,索引不再仅仅是整数,还可以是任意想要的类型。如果需要,完全可以用字符串定义索引:
data_1=pd.Series([0.5,1.0,1.5,2.0],index=['a','b','c','d'])
data_1
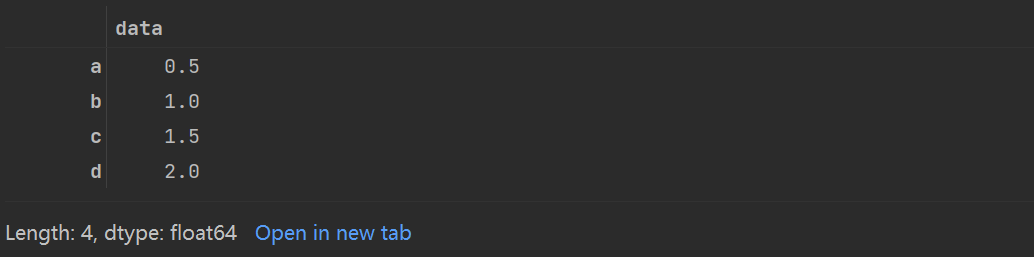
获取数据的方式和之前一样,例如:
data_1['a']
0.5
当然了,也可以使用不连续或者不按顺序的索引:
data_2=pd.Series([1,2,3,4],index=[1,3,5,7])
data_2
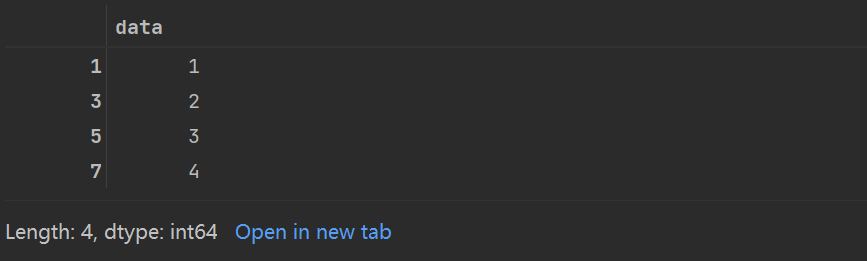
3.Series是特殊的字典
我们可以把Pandas中的Series对象看成一种特殊的Python字典,字典是一种将任意键映射到一组任意值的数据结构,而Series对象其实是一种将类型键映射到一组类型值的数据结构。类型至关重要:就像Numpy数组背后特定类型的经过编译的代码使得它在某些操作上比普通的Python列表更加高效一样,Pandas中的Series对象的类型信息使得它在某些操作上比Python的字典更高效。
可以直接使用Python的字典创建一个Series对象,让Series对象与字典的类比更加清晰:
love_percent={'beijing':85,'shanghai':75,'hangzhou':98,'suzhou':90,'nanjing':91}
love_percent
{'beijing': 85, 'shanghai': 75, 'hangzhou': 98, 'suzhou': 90, 'nanjing': 91}
此时我们得到的是一个字典格式:
love_percent_1=pd.Series(love_percent)
love_percent_1
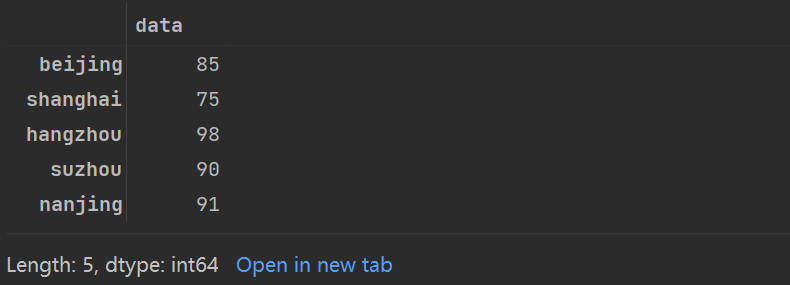
用字典创建Series对象时,其索引默认按照顺序排列。典型的字典数值获取方式依然有效:
love_percent_1['hangzhou']
98
和字典不同,Series对象还支持数组形式的操作,比如切片,具体与上面一致,不再讲述。
4.数据取值与选择
如前面的讲述,Series对象与一维Numpy数组和标准Python字典在许多方面都一样。只要牢记这两个类比,就可以帮助我们更好的理解Series对象的数据索引与选择模式。
1.将Series对象看作字典
和字典一样,Series对象提供了键值对的映射:
love_percent_1['hangzhou']
98
我们还可以用Python字典的表达式和方法来检测键/索引和值:
'changsha' in love_percent_1
False
love_percent_1.keys()
Index(['beijing', 'shanghai', 'hangzhou', 'suzhou', 'nanjing'], dtype='object')
list(love_percent_1.items())
[('beijing', 85),
('shanghai', 75),
('hangzhou', 98),
('suzhou', 90),
('nanjing', 91)]
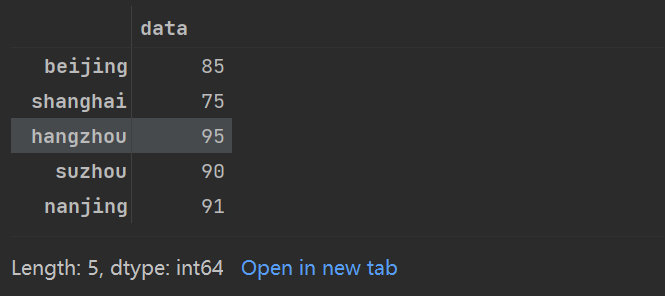
Series对象还可以用字典语法调整数据,就像你可以通过增加新的键扩展字典一样,也可以通过增加新的索引值扩展Series:
love_percent_1['hangzhou']=95
love_percent_1
2.将Series对象看作一维数组
Series不仅有着和字典一样的接口,而且还具备和Numpy数组一样的数组数据选择功能,包括索引、掩码、花哨的索引等操作,具体示例如下所示:
将显式索引作为切片
love_percent_1['beijing':'suzhou']
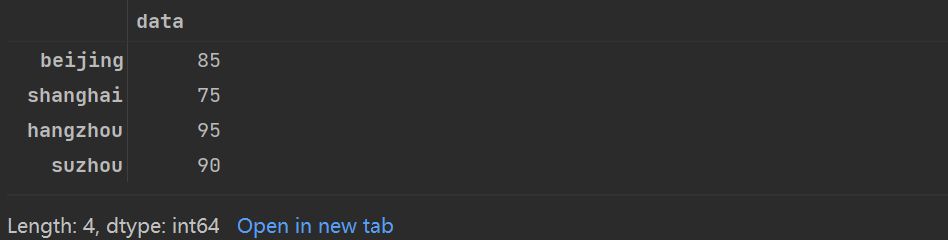
将隐式整数索引作为切片
love_percent_1[1:3]
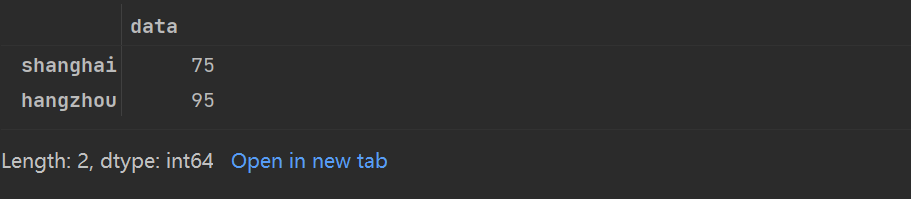
掩码
love_percent_1[love_percent_1>85]
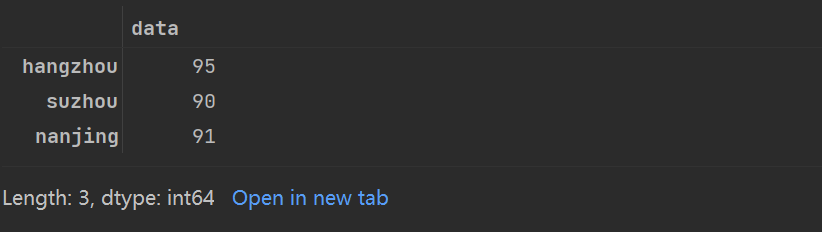
花哨的索引
love_percent_1[['beijing','hangzhou']]
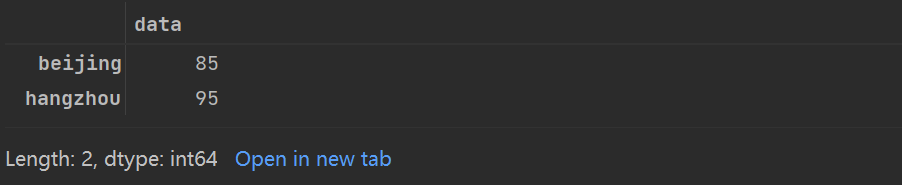
在以上示例中,切片是绝大多数混乱之源。需要注意的是,当使用显式索引做切片时,结果包含最后一个索引,而当使用隐式索引做切片时,结果不包含最后一个索引。
3.索引器:loc、iloc
由于整数索引很容易造成混淆,所以Panda提供了一些索引器(indexer)属性来作为取值的方法。它们不是Series对象的函数方法,而是暴露切片接口的属性。
第一种索引器是loc属性,表示取值和切片都是显式的:
love_percent_1.loc['shanghai']
75
love_percent_1['shanghai':'hangzhou']
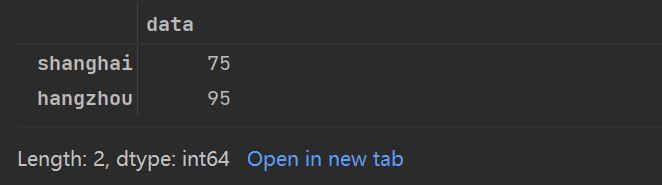
第二种是iloc属性,表示取值和切片都是Python形式的隐式索引:
love_percent_1.iloc[1]
75

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)