
prometheus监控
Prometheus是一个监控服务器,也是一个时序数据库TSDB。有专门的PQL,即Prometheus查询语言,采用go语言编写,主要用于监控容器数据,也可以监控常规主机—是一个框架,可以与其他组建完美结合—官方网站:https://prometheus.io/被监控端根据自身运行的服务,可以运行不同的exporter(被监控端安装的、可以与Prometheus通信,实现数据传递的软件):htt
1、prometheus监控介绍
—是一个监控服务器,也是一个时序数据库TSDB。
—有专门的PQL,即Prometheus查询语言
—采用go语言编写
—主要用于监控容器数据,也可以监控常规主机
—是一个框架,可以与其他组建完美结合
—官方网站:https://prometheus.io/
被监控端根据自身运行的服务,可以运行不同的exporter(被监控端安装的、可以与Prometheus通信,实现数据传递的软件):https://prometheus.io/docs/instrumenting/exporters/
1.1、监控原理
Prometheus Server负责定时在目标上抓取metrics(指标)数据,每个抓取目标[主机、服务]都需要暴露一个HTTP服务接口用于Prometheus定时抓取。也就是说prometheus会将获取到的监控数据打包成一个可访问的web页面,通过访问指定的url来确定主机的状态。
Pull方式的优势是能够自动进行上游监控和水平监控,配置更少,更容易扩展,更灵活,更容易实现高可用。简单来说就是Pull方式可以降低耦合。由于在推送系统中很容易出现因为向监控系统推送数据失败而导致被监控系统瘫痪的问题。因为如果同一时间有很多被监控主机都把数据推送给监控主机的话,就很可能导致监控主机处理不过来,所以通过Pull方式,被采集端无需感知监控系统的存在,完全独立于监控系统之外,这样数据的采集完全由监控系统控制。
2、监控平台部署
2.1、环境准备
- prometheus-server :192.168.4.10(监控服务器)
- node01:192.168.4.80(被监控业务机)
- grafana:192.168.4.20(监控展示)
- 关闭防火墙、selinux
2.2、prometheus-server监控服务器部署
2.2.1、主程序包下载与安装
[root@prometheus-server ~]# wget https://github.com/prometheus/prometheus/releases/download/v2.37.0/prometheus-2.37.0.linux-amd64.tar.gz
[root@prometheus-server ~]# tar xf prometheus-2.37.0.linux-amd64.tar.gz
[root@prometheus-server ~]# mv prometheus-2.37.0.linux-amd64 /usr/local/prometheus2.2.2、启动方式一
[root@prometheus-server ~]# cd /usr/local/prometheus/
[root@prometheus-server ~]# ./prometheus --config.file=./prometheus.yml &
[root@prometheus-server ~]# ss -ntulp | grep 9090
tcp LISTEN 0 128 :::9090 :::* users:(("prometheus",pid=21785,fd=8))
# 重启服务
[root@node1 prometheus-2.11.1.linux-amd64]# pkill prometheus
[root@node1 prometheus-2.11.1.linux-amd64]# ./prometheus --config.file=prometheus.yml &
2.2.3、启动方式二:创建prometheus的systemd文件
- 注意:prometheus启动报错“lock DB directory: resource temporarily unavailable”
- 原因:prometheus没有正常关闭,锁文件存在 rm $prometheus_dir/data/lock
2.2.2、登录192.168.4.10:9090 浏览页面
2.2.3、从localhost:9090/metrics查看监控数据
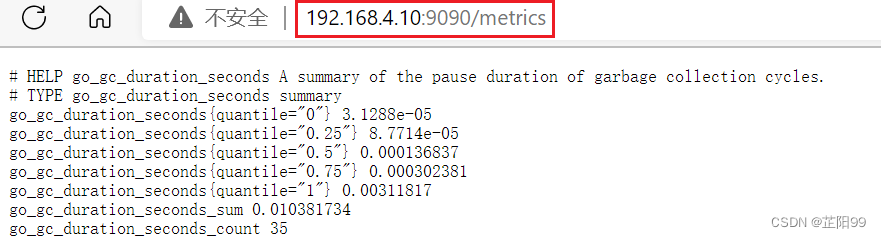
如果能看到这些信息就说明监控拿到了数据,拿到数据就可以正常显示了。通过这个URL我们可以知道prometheus把监控的数据都统一存放在一起,然后生成一个web页面,用户可以通过web页面查看相关的数据,这些数据遵循了时序数据库的格式,也就是key=value的形式。这些数据就是我们的监控指标,只不过现在我们还没有办法分析,借助图形展示才会更方便阅读。
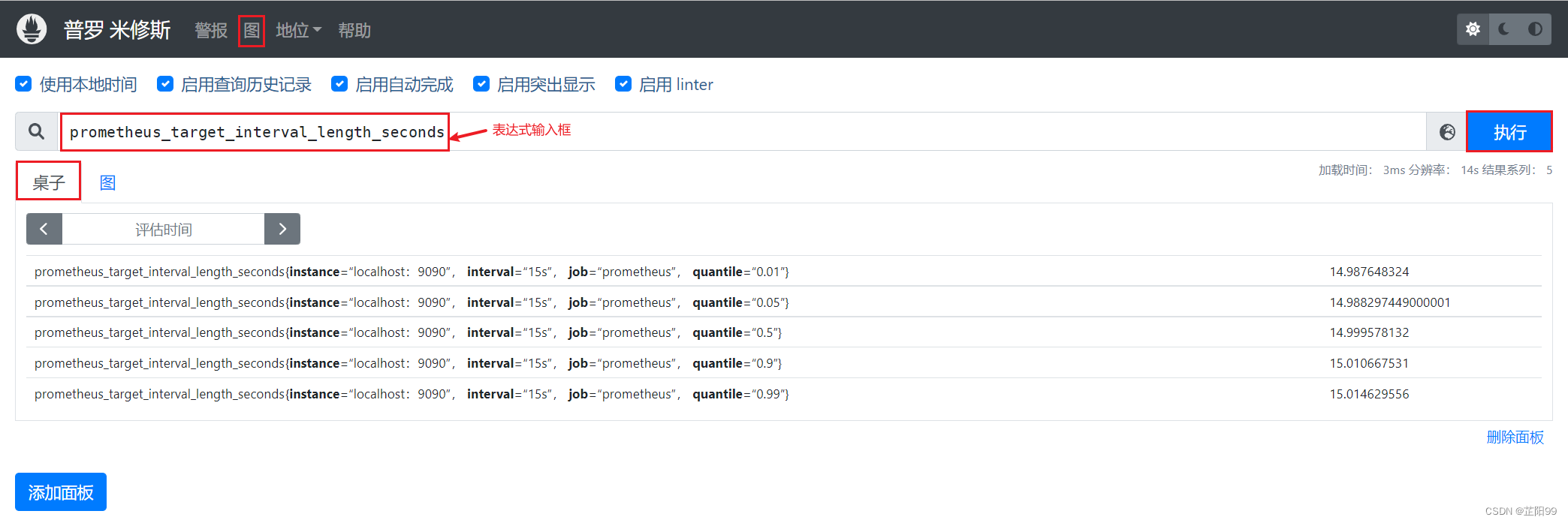
2.2.4、使用表达式浏览器
- 搜索栏中输入关键字可以匹配出你想看的监控项
2.3、添加监控端
被监控端根据自身运行的服务,可以运行不同的exporter(被监控端安装的、可以与Prometheus通信,实现数据传递的软件)
2.3.1、部署通用的监控exporter
[root@node01 ~]# wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0-rc.0/node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
[root@node01 ~]# tar xf node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
[root@node01 ~]# mv node_exporter-1.4.0-rc.0.linux-amd64 /usr/local/node_exporter
[root@node01 ~]# cd /usr/local/node_exporter/
[root@node01 node_exporter]# ls
LICENSE node_exporter NOTICE2.3.2、创建node_exporter的systemd文件
- exporter运行于被监控的主机,以服务形式存在,查看的端口需要查看其官方的文档。
[root@node01 ~]# vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
alter=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target2.3.3、启动node_exporter服务
[root@node01 ~]# systemctl enable node_exporter.service --now
[root@node01 ~]# ss -tlnp | grep node浏览器访问:http://192.168.4.80:9100/metrics,现在这台机器上的数据被打包成了一个可以访问的页面,所以可以使用浏览器去访问这个页面,看下能否获取到相关的数据,如果能够获取的话就表示没有问题了。
2.3.4、在prometheus-server添加监控信息
[root@prometheus-server ~]# vim /usr/local/prometheus/prometheus.yml
- job_name: "node01" # 监控节点的主机名,注意缩进
static_configs: # 定义具体配置
- targets: ["192.168.4.80:9100"] # 定义具体目标2.3.5、测试验证
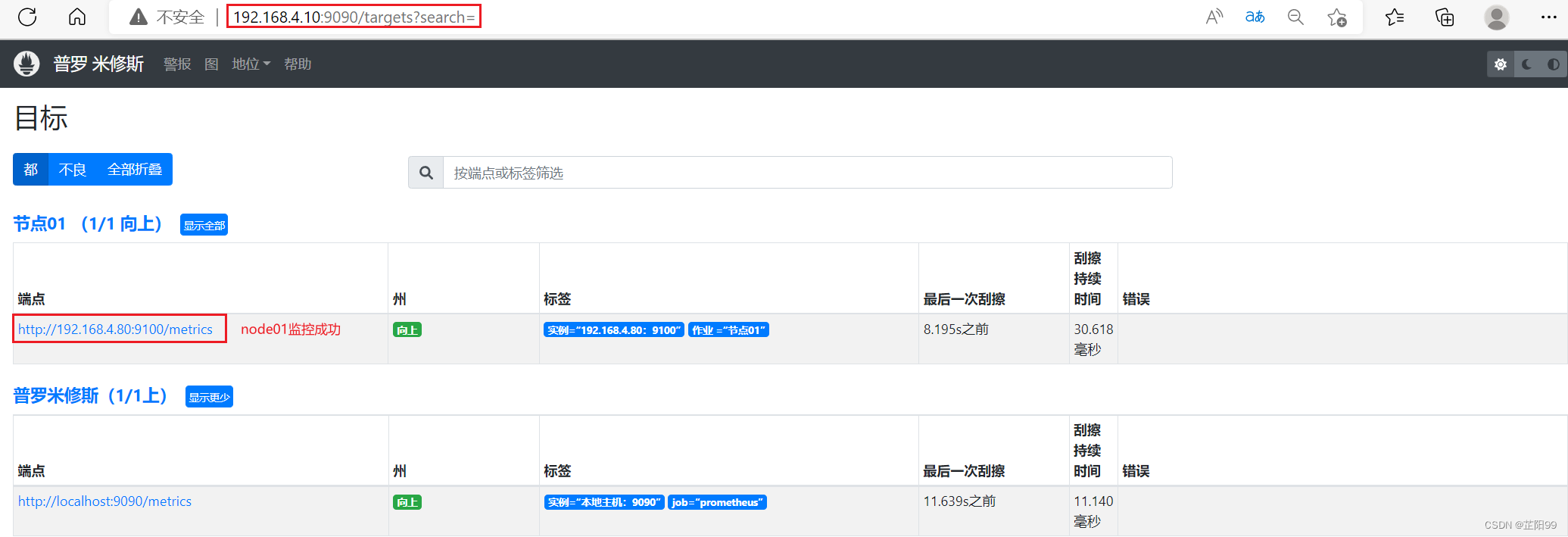
- 浏览器中输入 http://192.168.4.80:9100/metrics 既可以看到数据了
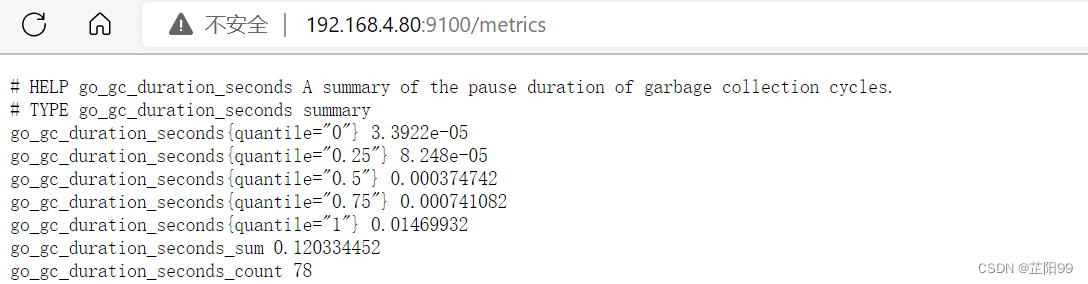
2.4、添加监控业务
通过prometheus监控MariaDB业务,要监控mysql需要两个条件,一个是系统中有mysql,另一个是要有监控插件,现在监控插件我已经下载好了,所以我们要先安装mysql,然后进行相应的授权,让插件可以获取到所需要的信息,然后再设置相关插件,修改prometheus配置文件。
2.4.1、部署mysql业务
[root@node01 ~]# yum -y install mariadb-server mariadb
[root@node01 ~]# systemctl enable mariadb.service
Created symlink from /etc/systemd/system/multi-user.target.wants/mariadb.service to /usr/lib/systemd/system/mariadb.service.
[root@node01 ~]# systemctl start mariadb.service
[root@node01 ~]# ss -utnlp | grep 3306
tcp LISTEN 0 50 *:3306 *:* users:(("mysqld",pid=12018,fd=14))2.4.1.1、创建监控用户
[root@node01 ~]# mysql -uroot -p
MariaDB [(none)]> grant select,replication client,process on *.* to jy@"localhost" identified by '123456';
Query OK, 0 rows affected (0.01 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)2.4.2、部署监控插件
[root@node01 ~]# wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz
[root@node01 ~]# tar xf mysqld_exporter-0.14.0.linux-amd64.tar.gz
[root@node01 ~]# mv mysqld_exporter-0.14.0.linux-amd64 /usr/local/mysqld_exporter
2.4.2.1、启动监控插件服务
[root@node01 ~]# vim /usr/lib/systemd/system/mysqld_exporter.service
[Unit]
Description=mysqld_exporter
After=network.target
[Service]
Type=simple
User=mysql
# jy对应授权账号,123456对应授权密码,localhost对应授权账号密码所在的地址
Environment=DATA_SOURCE_NAME=jy:123456@(localhost:3306)/
ExecStart=/usr/local/mysqld_exporter/mysqld_exporter --web.listen-address=0.0.0.0:9104
--config.my-cnf /etc/my.cnf \
--collect.slave_status \
--collect.slave_hosts \
--log.level=error \
--collect.info_schema.processlist \
--collect.info_schema.innodb_metrics \
--collect.info_schema.innodb_tablespaces \
--collect.info_schema.innodb_cmp \
--collect.info_schema.innodb_cmpmem
Restart=on-failure
[Install]
WantedBy=multi-user.targe
[root@node01 ~]# systemctl start mysqld_exporter.service
[root@node01 ~]# ss -ntulp | grep 91042.4.3、在prometheus-server添加监控信息,并重启
[root@prometheus-server ~]# vim /usr/local/prometheus/prometheus.yml
- job_name: "mariadb"
static_configs:
- targets: ["192.168.4.80:9104"]
[root@prometheus-server ~]# systemctl restart prometheus.service 2.4.4、通过监控页面查看服务
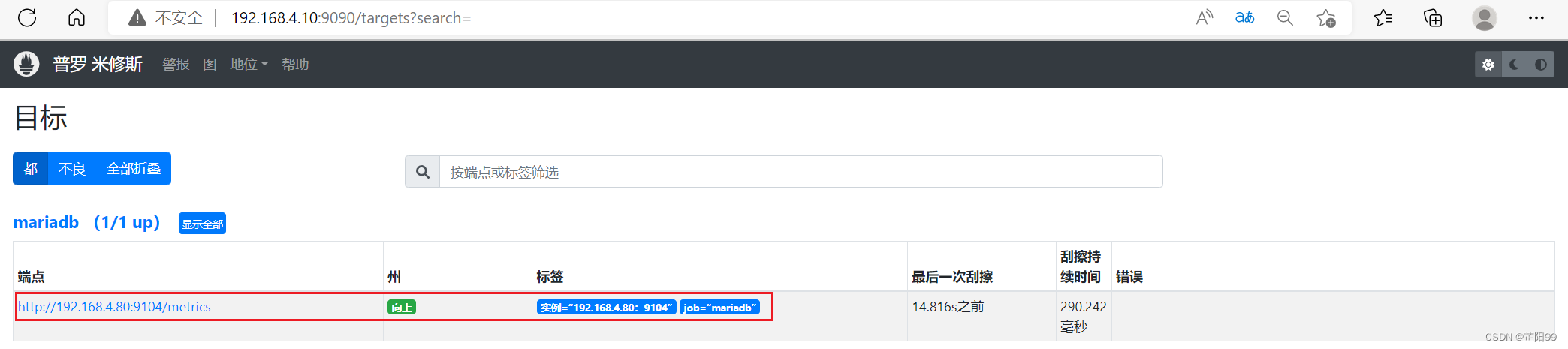
2.5、监控报警系统 AlertManager 之邮件告警
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,例如邮件、微信、钉钉、Slack 等常用沟通工具,而且很容易做到告警信息进行去重,降噪,分组等,是一款很好用的告警通知系统。
2.5.1、AlertManager插件的安装部署
[root@prometheus-server ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
[root@prometheus-server ~]# tar xf alertmanager-0.24.0.linux-amd64.tar.gz
[root@prometheus-server ~]# mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager
[root@prometheus-server ~]# cd /usr/local/alertmanager2.5.2、创建启动文件
[root@prometheus-server ~]# vim /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
After=local-fs.target network-online.target network.target
Wants=local-fs.target network-online.target network.target
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
[root@prometheus-server ~]# systemctl daemon-reload
[root@prometheus-server ~]# systemctl start alertmanager.service
2.5.3、配置alertmanager.yml文件
Alertmanager 安装目录下默认有 alertmanager.yml 配置文件,可以创建新的配置文件,在启动时指定即可。
[root@prometheus-server ~]# vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: ******@163.com
smtp_auth_username: ******@163.com
smtp_auth_password: ******
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1m
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: ******@163.com配置文件说明:
全局配置 global:用于定义一些全局配置;
resolve_timeout:当告警的状态有firing变为resolve的以后还要呆多长时间,才宣布告警解除。这个主要是解决某些监控指标在阀值边缘上波动,一会儿好一会儿不好。
smtp_smarthost:是用于发送邮件的邮箱的 SMTP 服务器地址+端口【smtp.exmail.qq.com:25】;
smtp_from:
smtp_auth_username:
- smtp_auth_password:是发送邮箱的授权码而不是登录密码;
- smtp_require_tls:不设置的话默认为 true,当为 true 时会有 starttls 错误,为了简单这里设置为 false;
- 模板 templates:告警时的通知模板(如果没有配置,将自动使用默认的模板)
- 告警路由 route:通过标签匹配的方式,确定当前告警应当如何处理;
- group_by:采用哪个标签来作为分组依据;
- group_wait:组告警等待时间。也就是告警产生后等待10s,同组告警一起发出;
- group_interval:两组告警的间隔时间;
- repeat_interval:重复告警的间隔时间,减少相同邮件的发送频率
- receiver:设置默认接收人
- 接收人 receivers:配合告警路由使用,定义了接收人的通信方式;
- name:就是个代称方便后面用
- 抑制规则 inhibit_rules:合理设置抑制规则可以减少垃圾告警的产生;
2.5.4、配置告警规则
- 在 Prometheus服务器上添加 Alertmanager的配置
[root@prometheus-server ~]# vim /usr/local/prometheus/prometheus.yml
rule_files: # 告警规则的配置文件
- "rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node01"
static_configs:
- targets: ["192.168.4.80:9100"]
- job_name: "mariadb"
static_configs:
- targets: ["192.168.4.80:9104"]
- job_name: "alertmanager" # 追加alertmanager服务器的信息
static_configs:
- targets: ["192.168.4.10:9093"]
- 在 prometheus添加告警规则
[root@prometheus-server ~]# cat /usr/local/prometheus/rules/node.yml
groups:
- name: Linux
rules:
- alert: "-内存报警"
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 60
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 内存资源利用率大于 60%"
value: "当前内存占用率{{ $value }}%"
- alert: "-CPU报警"
expr: 100 * (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) > 60
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} CPU报警资源利用率大于 60%"
value: "当前CPU占用率{{ $value }}%"
- alert: "-磁盘报警"
expr: 100 * (node_filesystem_size_bytes{fstype=~"xfs|ext4"} - node_filesystem_avail_bytes) / node_filesystem_size_bytes > 80
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘报警资源利用率大于 80%,请及时扩容!"
value: "当前磁盘占用率{{ $value }}%"
- alert: "-磁盘读取报警"
expr: sum by (instance) (irate(node_disk_read_bytes_total{device=~"dm-*|sda|"}[2m])) > 1024 * 1024 * 100
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘读取大于 100MB/s"
value: "当前磁盘读取{{ $value }}MB/s"
- alert: "-磁盘写入报警"
expr: sum by (instance) (irate(node_disk_written_bytes_total{device=~"dm-*|sda|"}[2m])) > 1024 * 1024 * 100
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘写入大于 100MB/s"
value: "当前磁盘写入{{ $value }}MB/s"
- alert: "-下载网络流量报警"
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[1m])) by (instance)) / 60 / 1024 / 2) > 200
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 最近1分钟使用下载流量每秒超过200Mb/s"
value: "最近1分钟使用下载流量每秒{{ $value }}Mb/s"
- alert: "上传网络流量报警"
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[1m])) by (instance)) / 60 / 1024 / 2) > 200
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 最近1分钟使用上传流量每秒超过 200Mb/s"
value: "最近1分钟使用上传流量每秒{{ $value }}Mb/s"
- name: Windows
rules:
- alert: "-内存报警"
expr: 100 - ((windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes) * 100) > 60
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 内存资源利用率大于 60%"
value: "当前内存占用率{{ $value }}%"
- alert: "-CPU报警"
expr: 100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 30
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} CPU报警资源利用率大于 30%"
value: "当前CPU占用率{{ $value }}%"
- alert: "-磁盘报警"
expr: 100.0 - 100 * ((windows_logical_disk_free_bytes / 1024 / 1024 ) / (windows_logical_disk_size_bytes / 1024 / 1024)) > 85
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘报警资源利用率大于 85%,请及时扩容!"
value: "当前磁盘占用率{{ $value }}%"2.5.5、重启服务
[root@prometheus-server ~]# systemctl restart alertmanager.service
[root@prometheus-server ~]# systemctl restart prometheus.service - 登入web页面,可以看到设置的报警规则
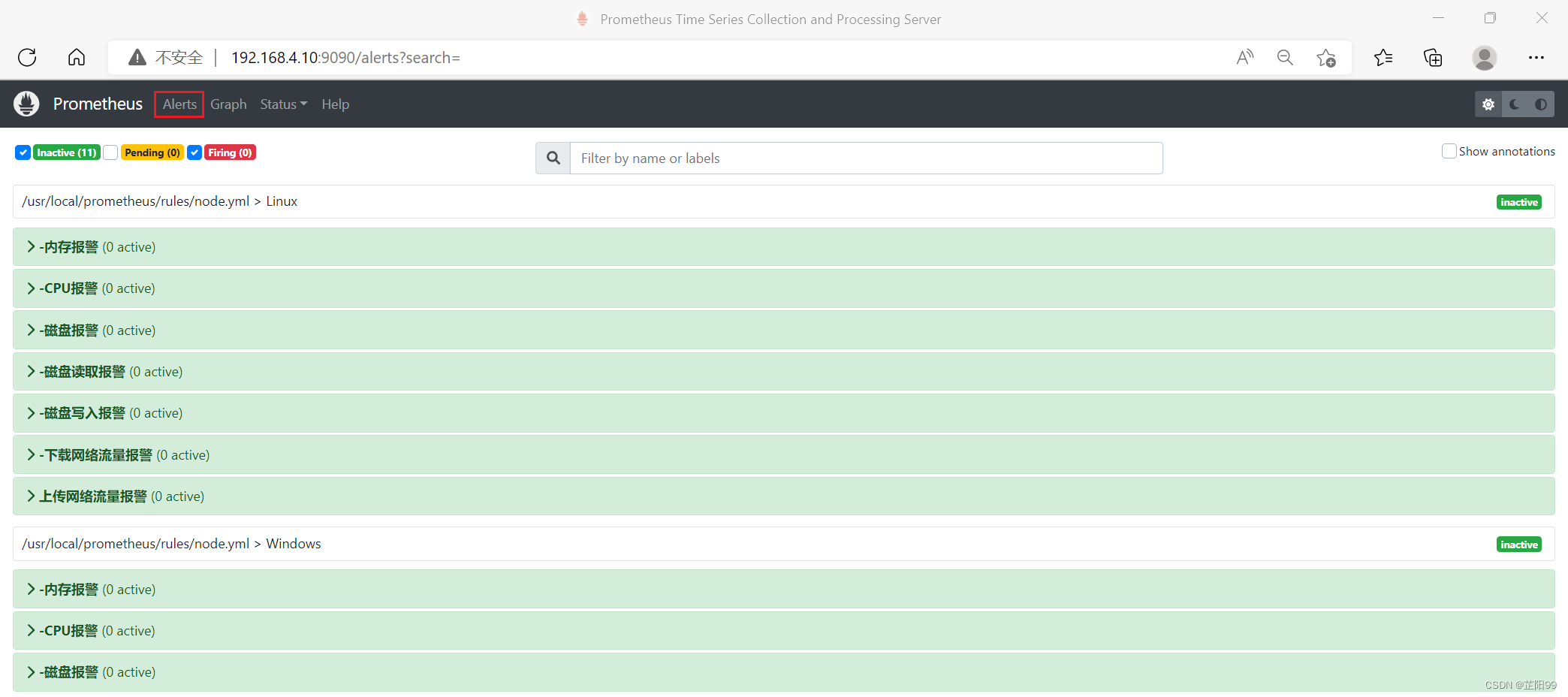
2.5.6、对CPU进行压测
[root@node01 ~]# cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d | gzip -9 | gzip -d | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null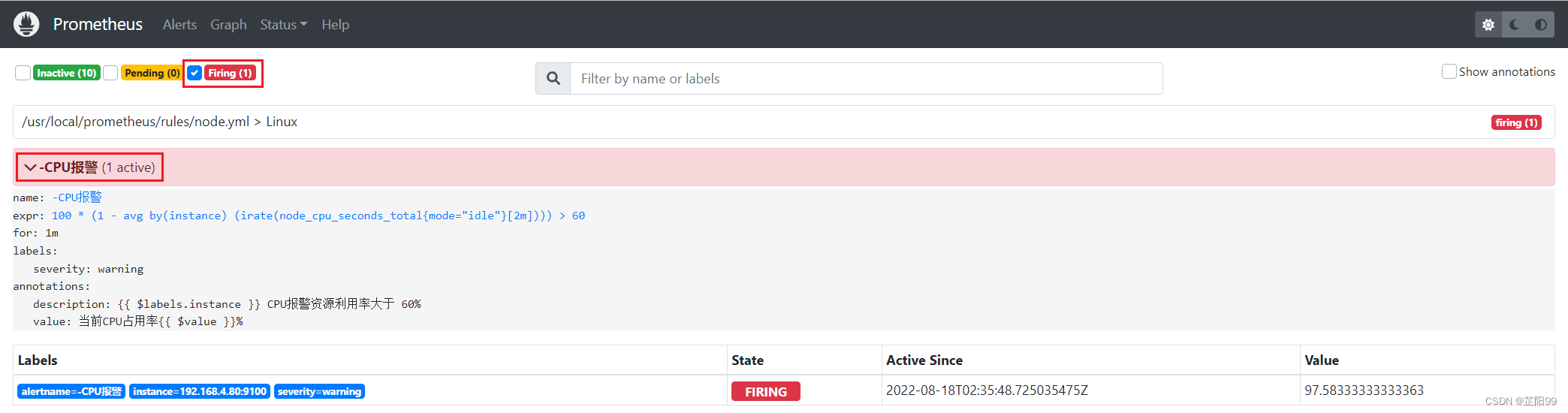

2.6、Grafana+Prometheus监控数据展示
Grafana,是一个开源的度量分析和可视化工具(没有监控功能),可以通过将采集的数据分析,查询,然后进行可视化的展示,并能实现报警。
grafana官方网站:https://grafana.com/
2.6.1、Grafana安装
[root@grafana ~]# wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.0.6-1.x86_64.rpm
[root@grafana ~]# yum -y install grafana-enterprise-9.0.6-1.x86_64.rpm
2.6.2、启动并验证服务
[root@grafana ~]# systemctl start grafana-server.service
[root@grafana ~]# systemctl enable grafana-server.service
[root@grafana ~]# ss -ntulp | grep :3000
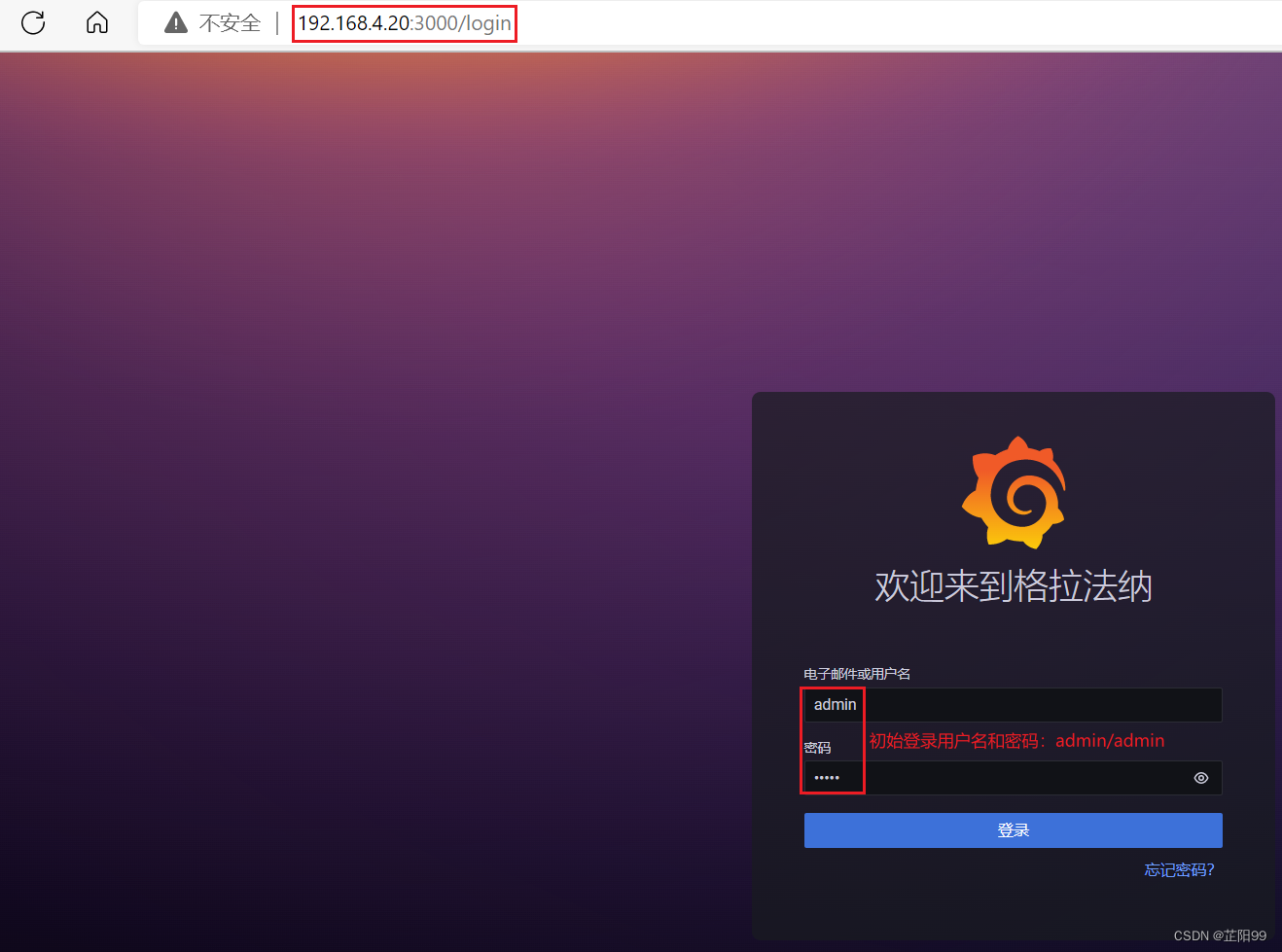
tcp LISTEN 0 128 :::3000 :::* users:(("grafana-server",pid=1866,fd=12))2.6.3、在浏览器中输入http://IP或者域名:3000
- 登录用户名:admin,密码:admin
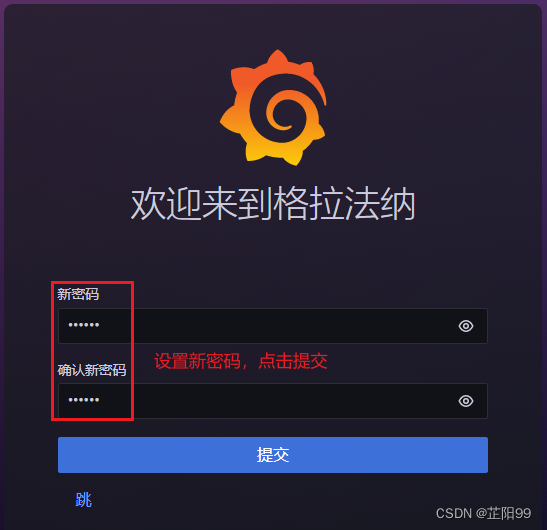
- 设置新密码
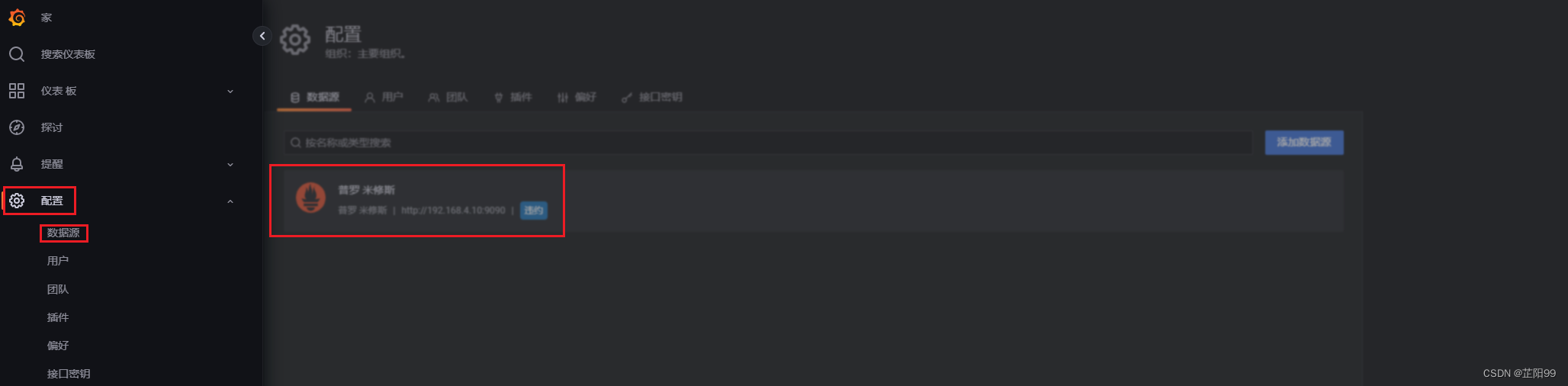
2.4.4、grafana页面设置—添加数据源 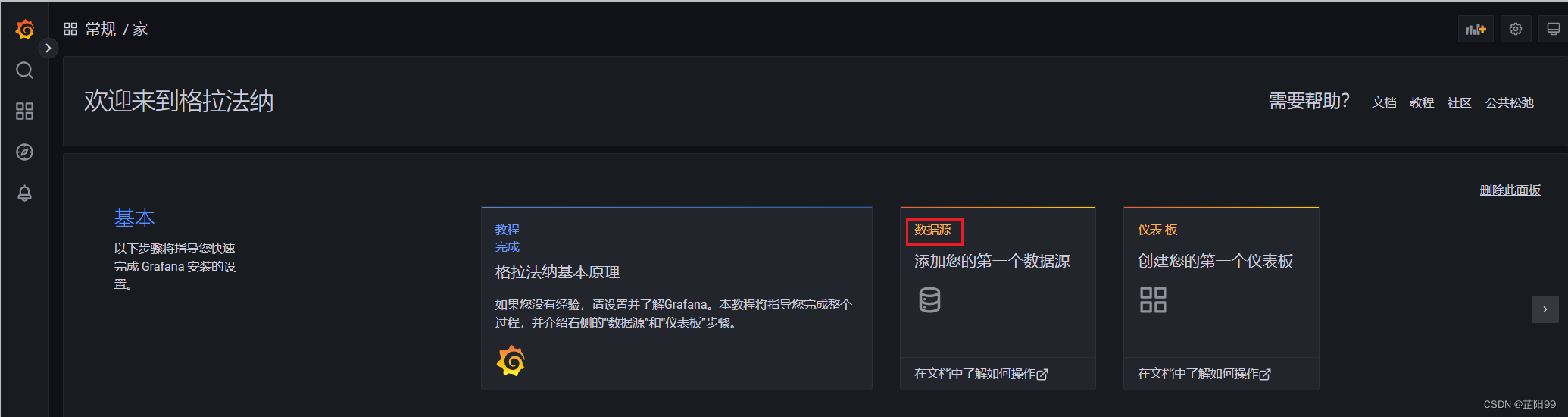
- 点击添加数据源 增加数据源

- 认证部分的设置,主要是与HTTPS配合使用的,如果使用的是https的话就需要证书啊,认证啊这些,需要对此部分内容进行一些配置
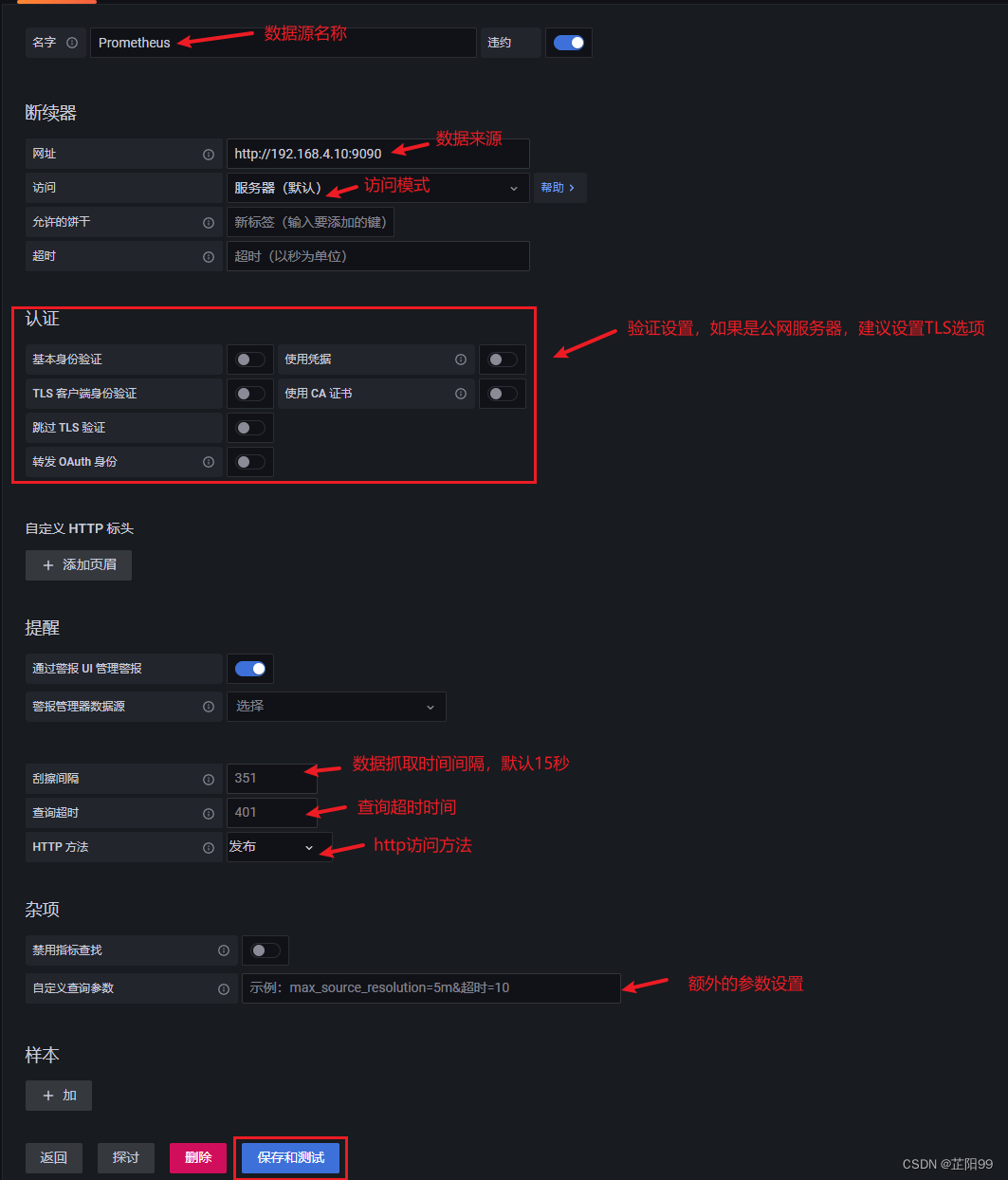
- 通过左侧导航栏中的齿轮图标下拉菜单中的数据源,看到刚才添加的数据源
2.7、图形面板
面板(Panel)是 Grafana 中基本可视化构建块,每个面板都有一个特定于面板中选择数据源的查询编辑器,每个面板都有各种各样的样式和格式选项,面板可以在仪表板上拖放和重新排列,它们也可以调整大小,所以要在 Grafana 上创建可视化的图表,面板是我们必须要掌握的知识点。
Panel 是 Grafana 中最基本的可视化单元,每一种类型的面板都提供了相应的查询编辑器(Query Editor),让用户可以从不同的数据源(如 Prometheus)中查询出相应的监控数据,并且以可视化的方式展现,Grafana 中所有的面板均以插件的形式进行使用。
Grafana 提供了各种可视化来支持不同的用例,目前内置支持的面板包括:Time series(时间序列)是默认的也是主要的图形可视化面板、State timeline(状态时间表)状态随时间变化 、Status history(状态历史记录)、Bar chart(条形图)、Histogram(直方图)、Heatmap(热力图)、Pie chart(饼状图)、Stat(统计数据)、Gauge、Bar gauge、Table(表格)、Logs(日志)、Node Graph(节点图)、Dashboard list(仪表板列表)、Alert list(报警列表)、Text panel(文本面板,支持 markdown 和 html)、News Panel(新闻面板,可以显示 RSS 摘要)等,除此之外,我们还可以通过官网的面板插件页面 Grafana Plugins - extend and customize your Grafana | Grafana Labs 获取安装其他面板进行使用。
2.7.1、方式一:自定义设置
- 添加完数据源后,可以继续添加仪表盘了,这样我们就能以图表的方式看到数据了
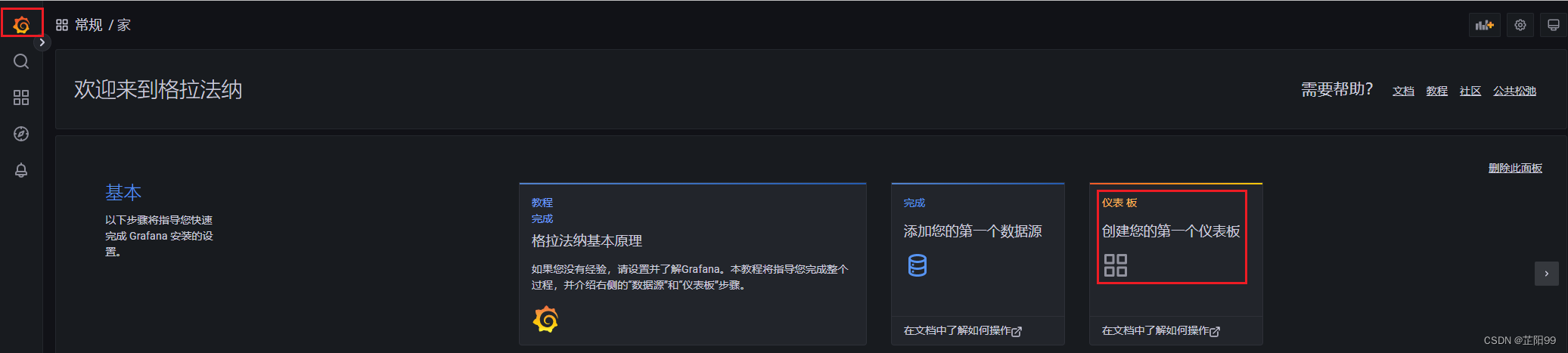
- 这里任选一个都可以,我选择第一个
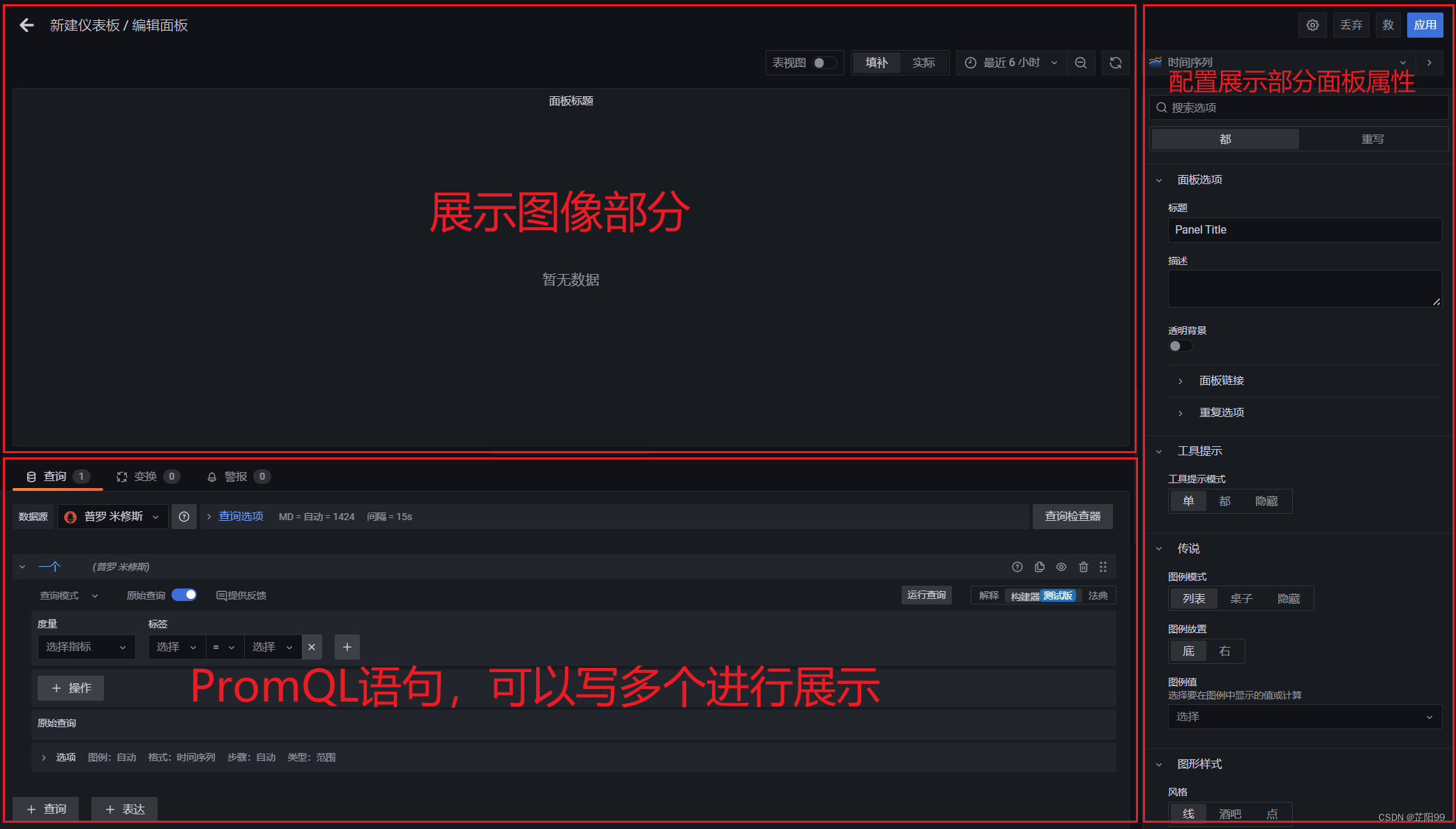
- 面板展示设置
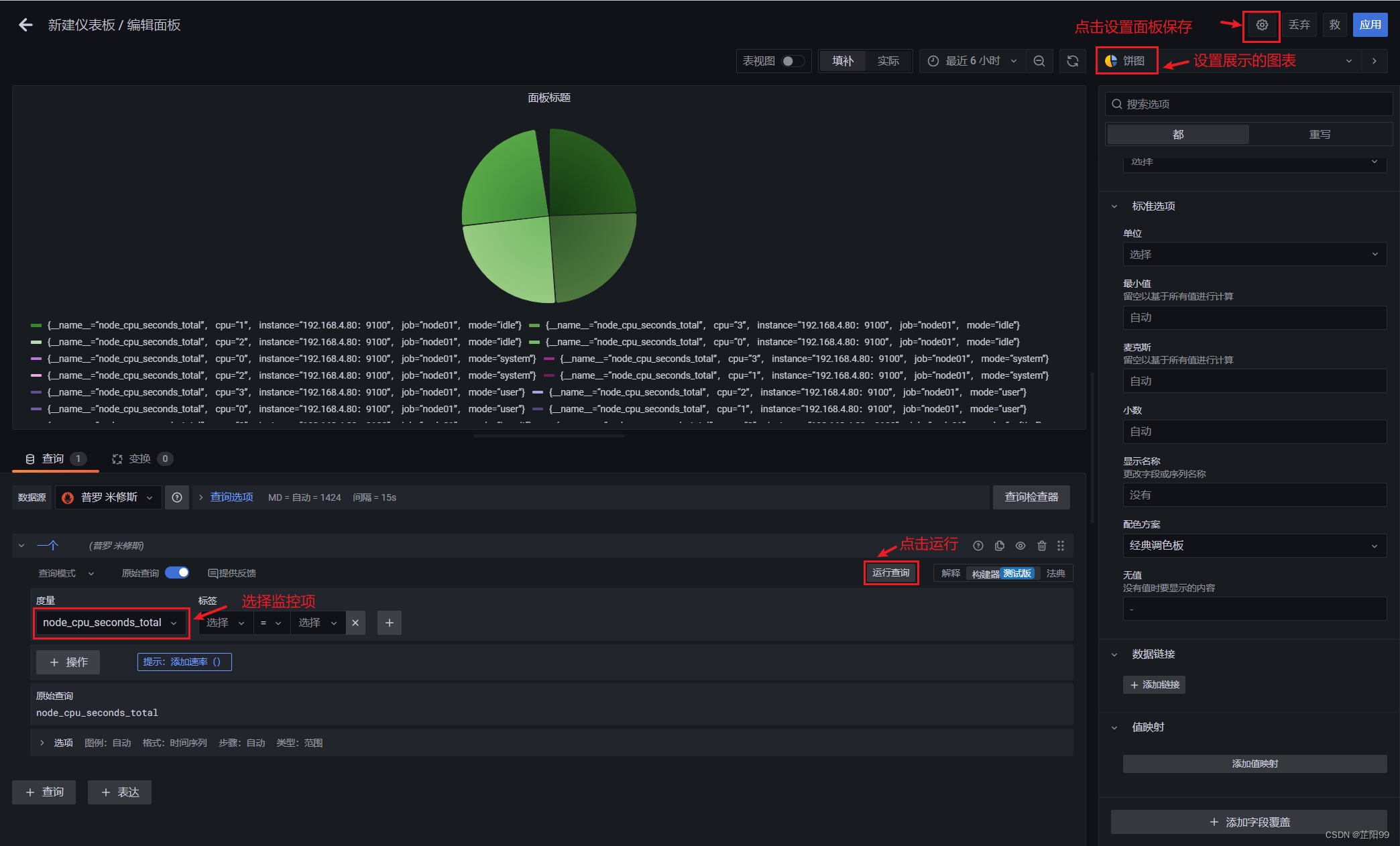
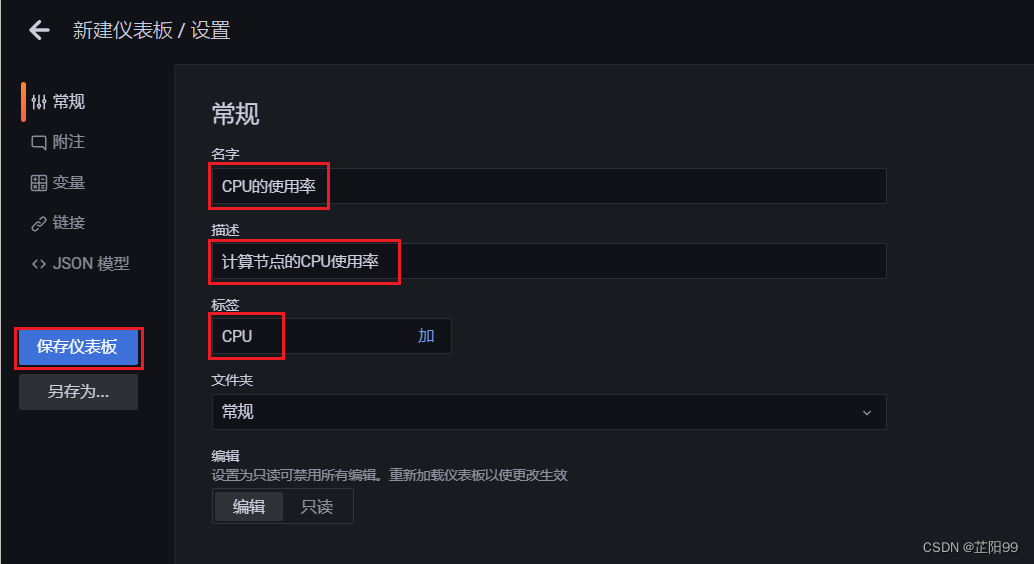
- 保存面板
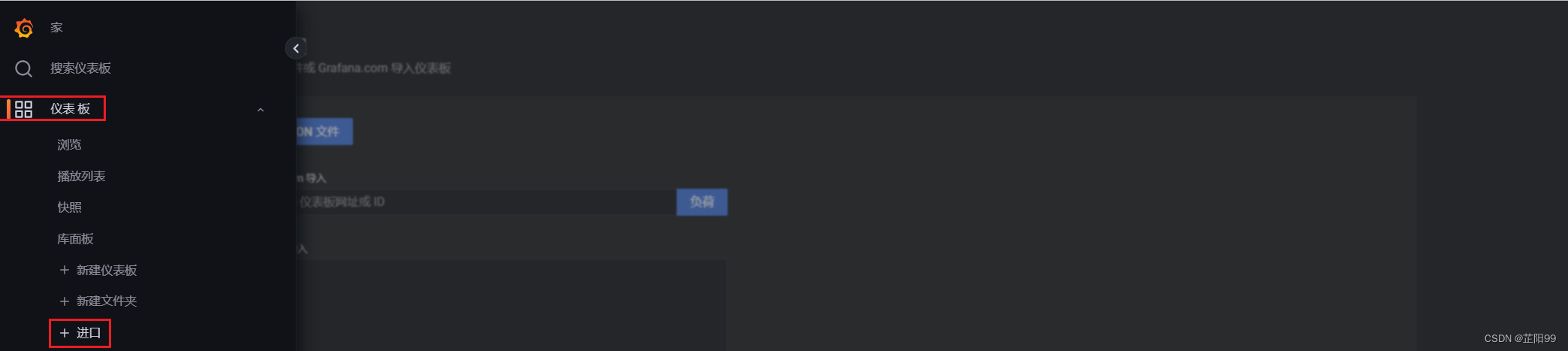
 2.7.2、方式二:web页面导入模板
2.7.2、方式二:web页面导入模板
- 下载网址:https://grafana.com/grafana/dashboards/?plcmt=footer
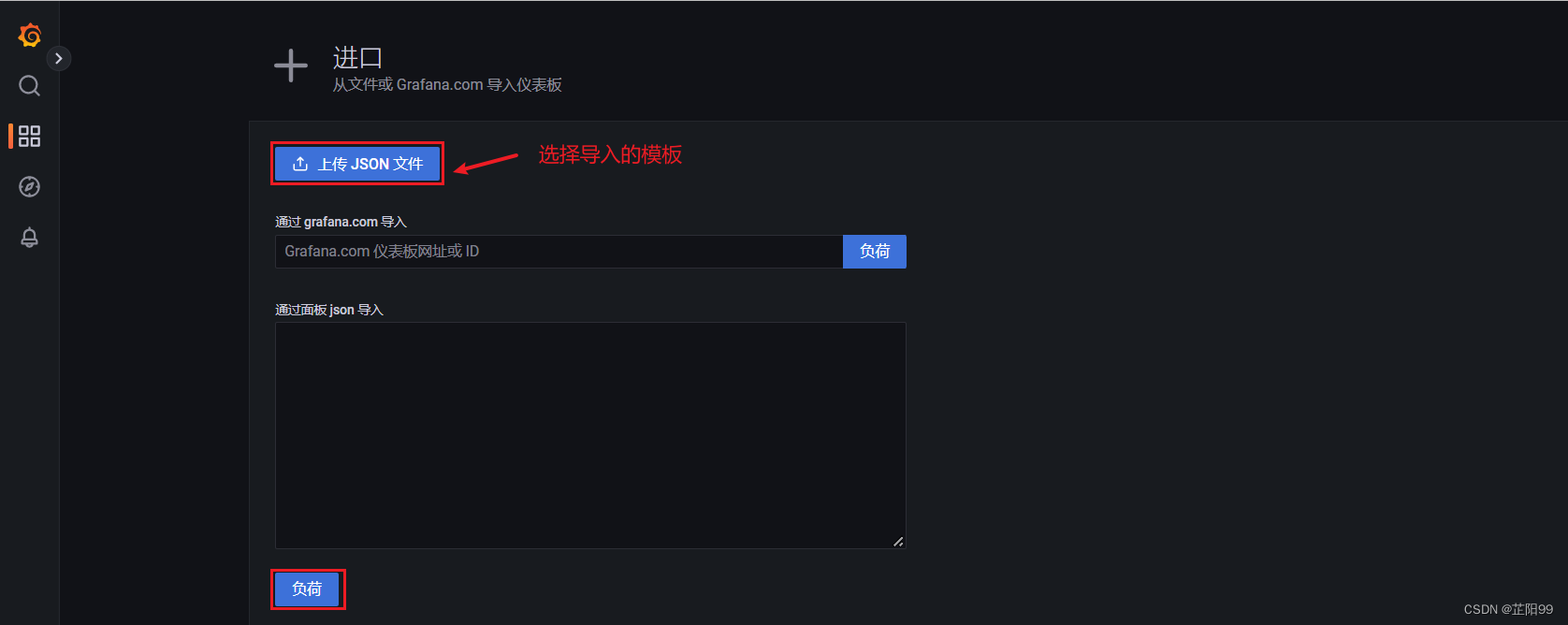
- 将下载到本地的json文件上传
- 仪表板的定义
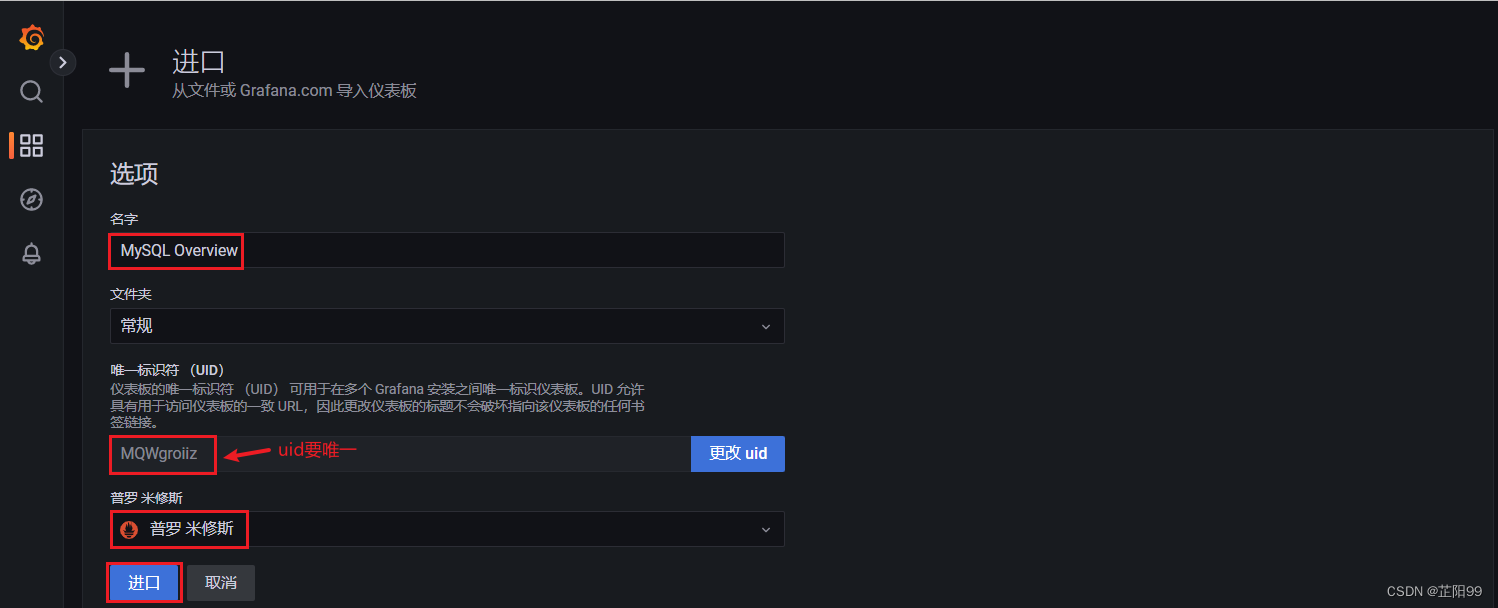
- 导入成功后,就可以看到图表
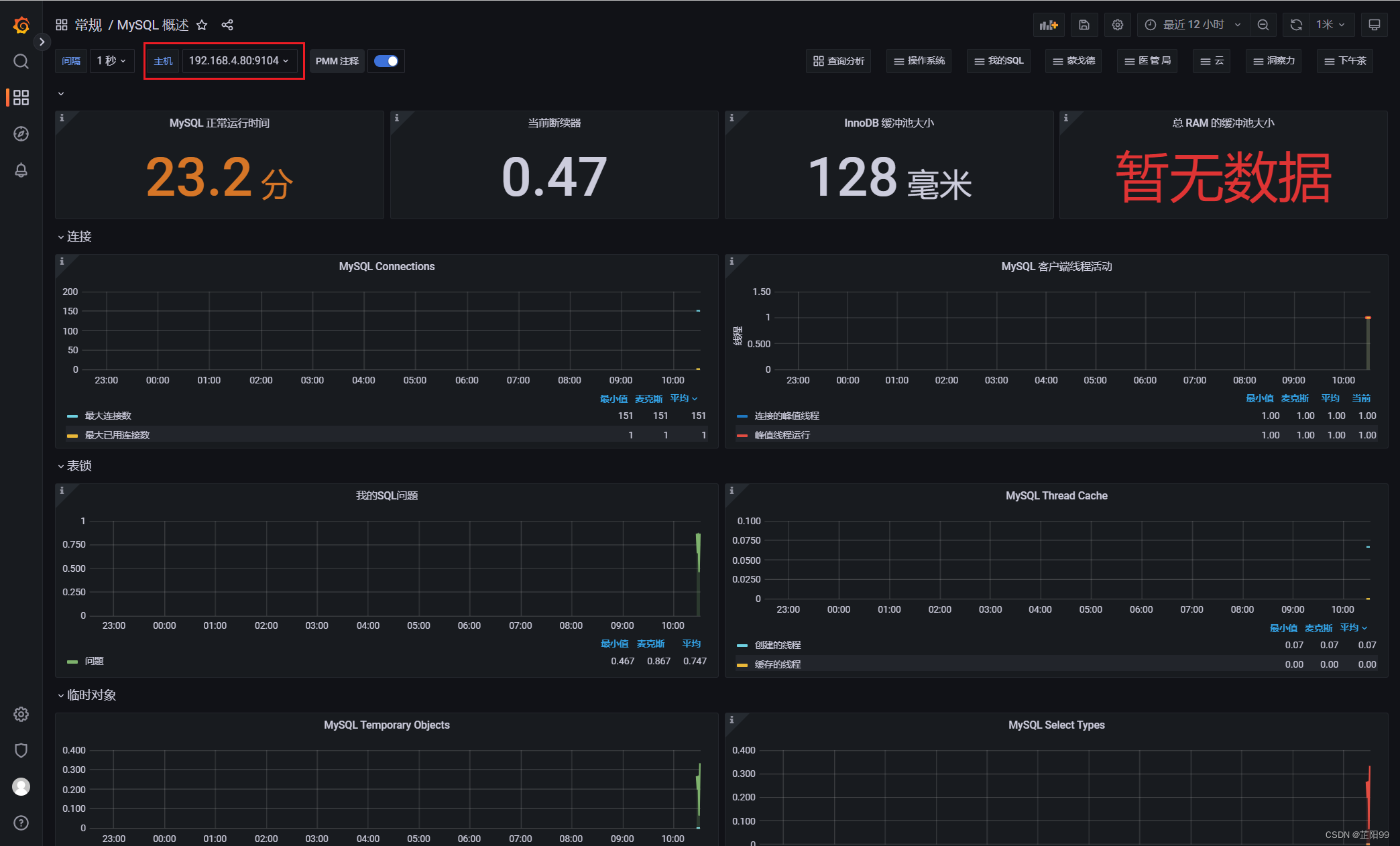
2.8、Grafana告警配置
2.8.1、创建Grafana报警规则
- 单击“警报”(铃铛)图标>“新建警报规则”
- 打开新的警报规则页
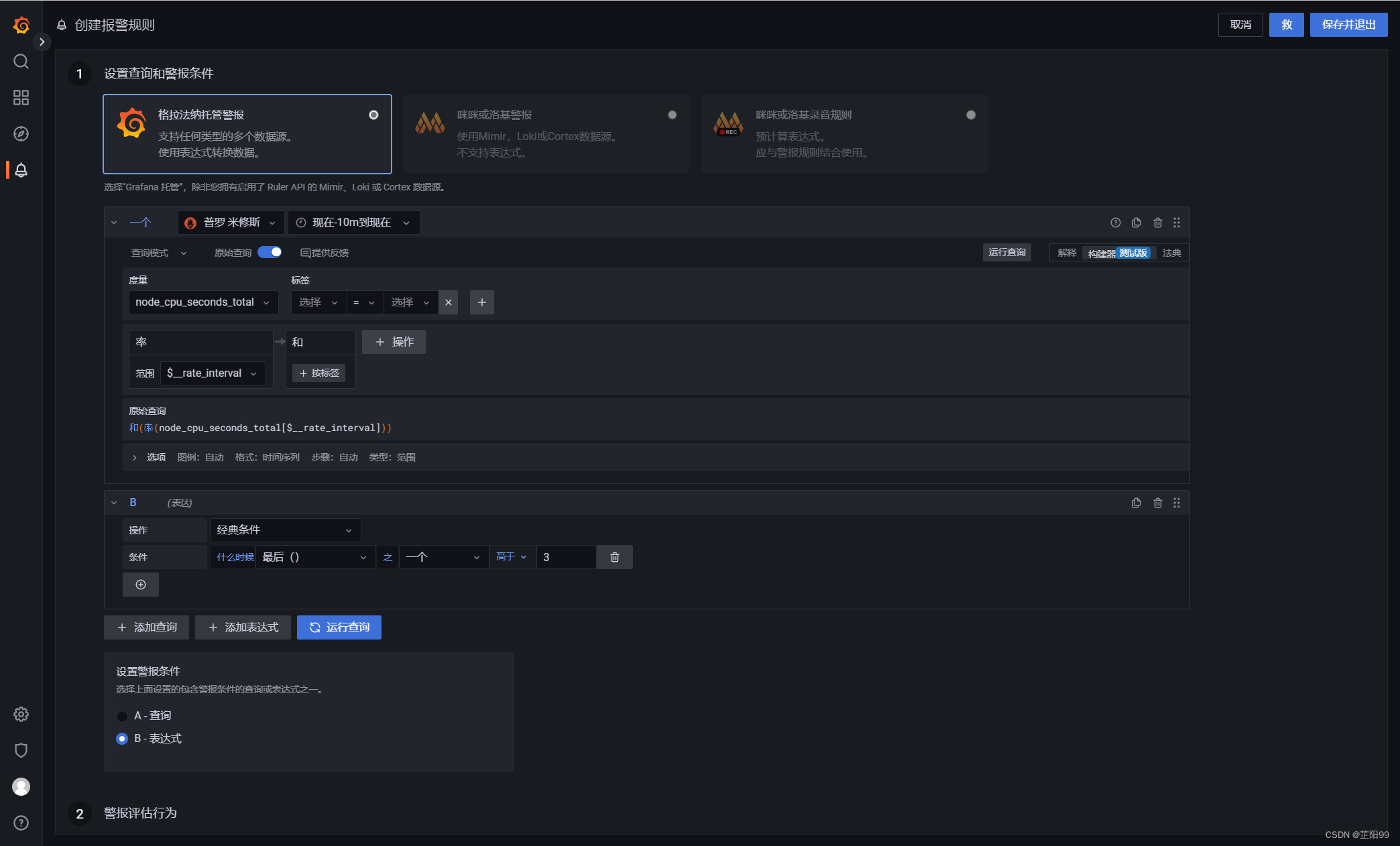
参数说明:默认情况下,该页将在其中选中“Grafana 管理的警报”选项。
- 在步骤 1 中:设置查询和报警条件,先添加要计算的查询和表达式,然后选择警报条件。
- 对于查询,请从下拉列表中选择数据源。
- 添加一个或多个查询或表达式。
- 对于每个表达式,选择“经典条件”以创建单个警报规则,或从“数学”、“减少”、“重新取样”选项中进行选择,为每个系列生成单独的警报。有关这些选项的详细信息,请参阅单维和多维规则。
- 单击“运行查询”以验证查询是否成功。
- 接下来,为警报条件选择查询或表达式。
- 在步骤 2 中:警报评估行为,指定警报评估间隔。
- 从“条件”下拉列表中,选择要触发警报规则的查询或表达式。
- 对于“评估间隔”,请指定评估频率。必须是 10 秒的倍数。例如,、 。
1m30s- 对于“评估对象”,请指定在警报触发之前条件必须为 true 的持续时间。【注意:违反条件后,警报将进入“挂起”状态。如果在指定的持续时间内仍然违反条件,则警报将转换为状态,否则它将恢复到状态。
FiringNormal】- 在“不配置数据和错误处理”中,配置没有数据时的警报行为。使用无数据和错误处理中的准则。
- 单击“预览警报”以检查此时运行查询的结果。预览不排除任何数据和错误处理。
- 在步骤 3 中:添加警报的详细信息,添加规则名称、存储位置、规则组以及与规则关联的其他元数据。
- 在“规则名称”中,添加一个描述性名称。此名称显示在警报规则列表中。它也是从此规则创建的每个警报实例的标签。
alertname- 从“文件夹”下拉列表中,选择要在其中存储规则的文件夹。
- 对于组,指定预定义的组。新创建的规则将追加到组的末尾。组中的规则以固定的时间间隔按顺序运行,评估时间相同。
- 添加说明和摘要以自定义警报消息。使用批注和标签中的准则进行警报。
- 添加 Runbook URL、面板、仪表板和警报 ID。
- 在步骤4中:通知,添加自定义标签。
- 单击“保存”保存规则,或单击“保存并退出”保存规则并返回到“警报”页。
2.8.2、使用Grafana配置邮件告警
[root@grafana ~]# vim /etc/grafana/grafana.ini
…………
…………
################################ SMTP / Emailing ########################
[smtp]
enabled = true
host = smtp.163.com:25
user = 15080663400@163.com # 使用的邮箱
password = ****** # 邮箱的授权码
skip_verify = true
from_address = 15080663400@163.com
from_name = Grafana
#################################### Alerting ############################
[alerting]
enabled = true
execute_alerts = true
…………
…………
[root@grafana ~]# systemctl restart grafana-server.service 2.8.3、创建联系点
- 在左侧导航栏中,选择“提醒 ”> “联系点”,然后单击“新建联系点”。
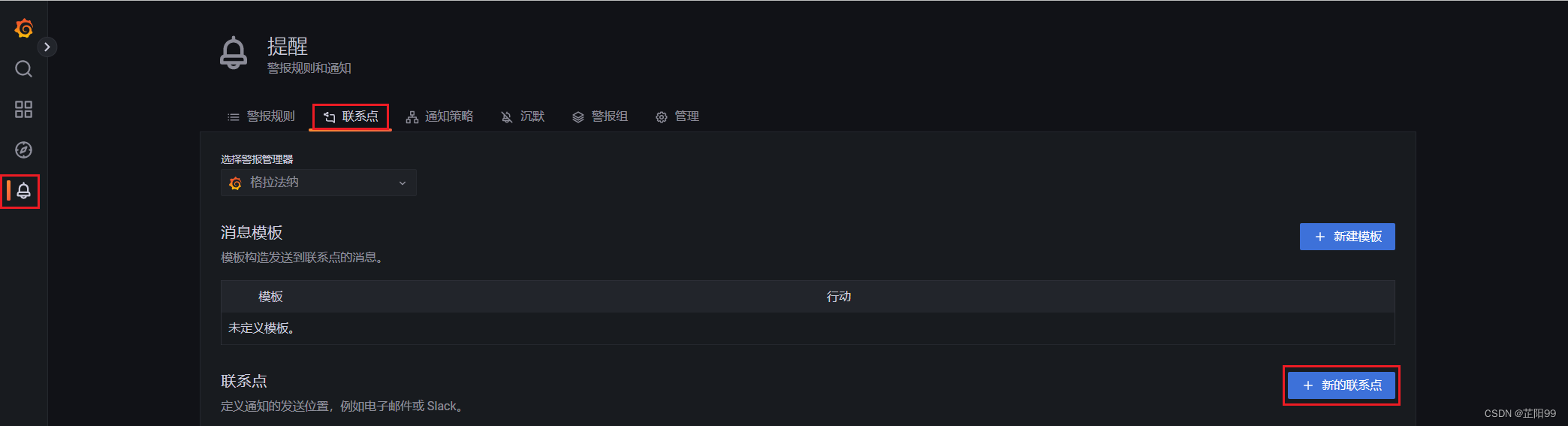
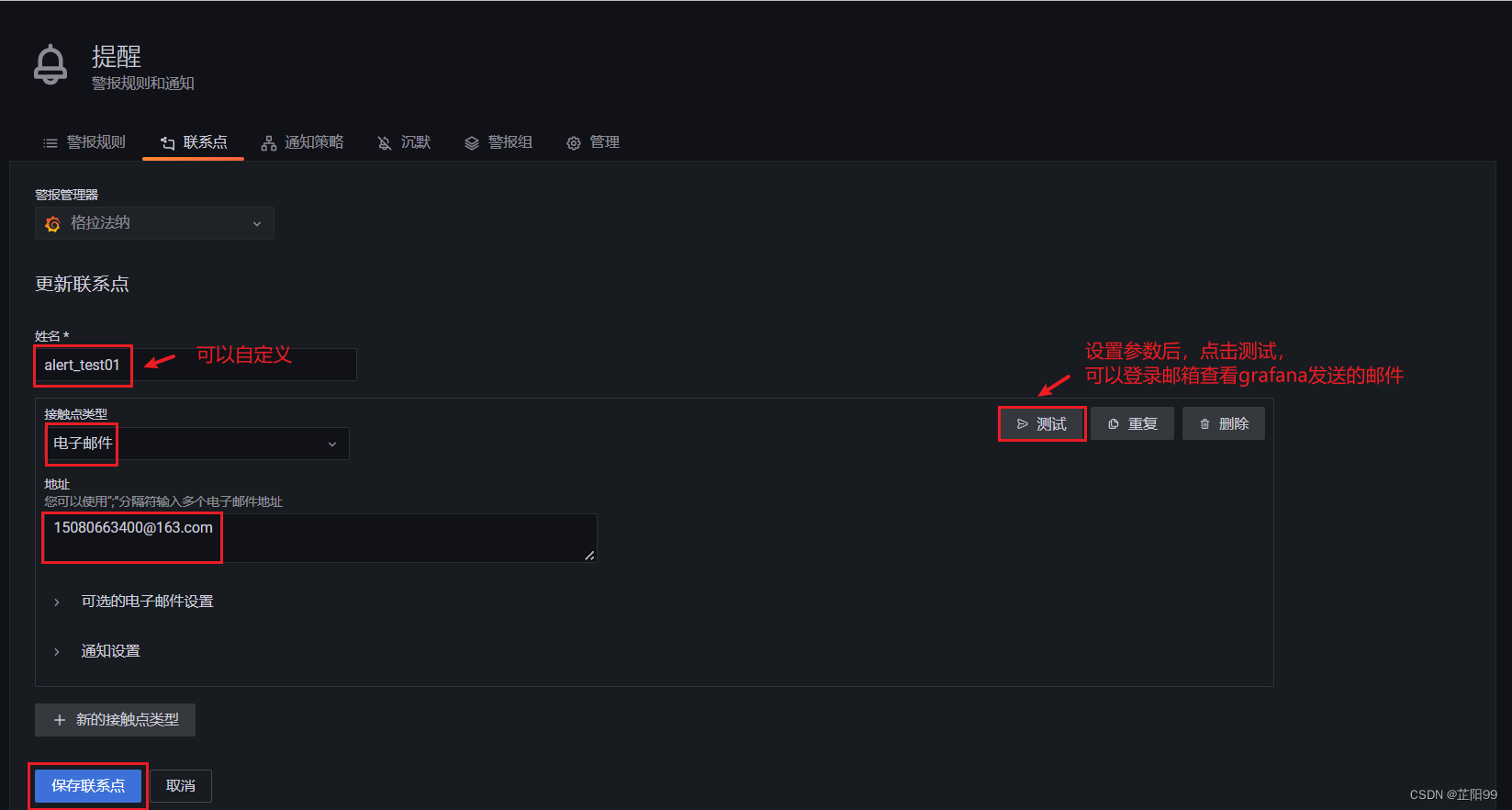
- 在新建联系点的页面中,配置如下参数。邮箱测试成功点击保存联系点。
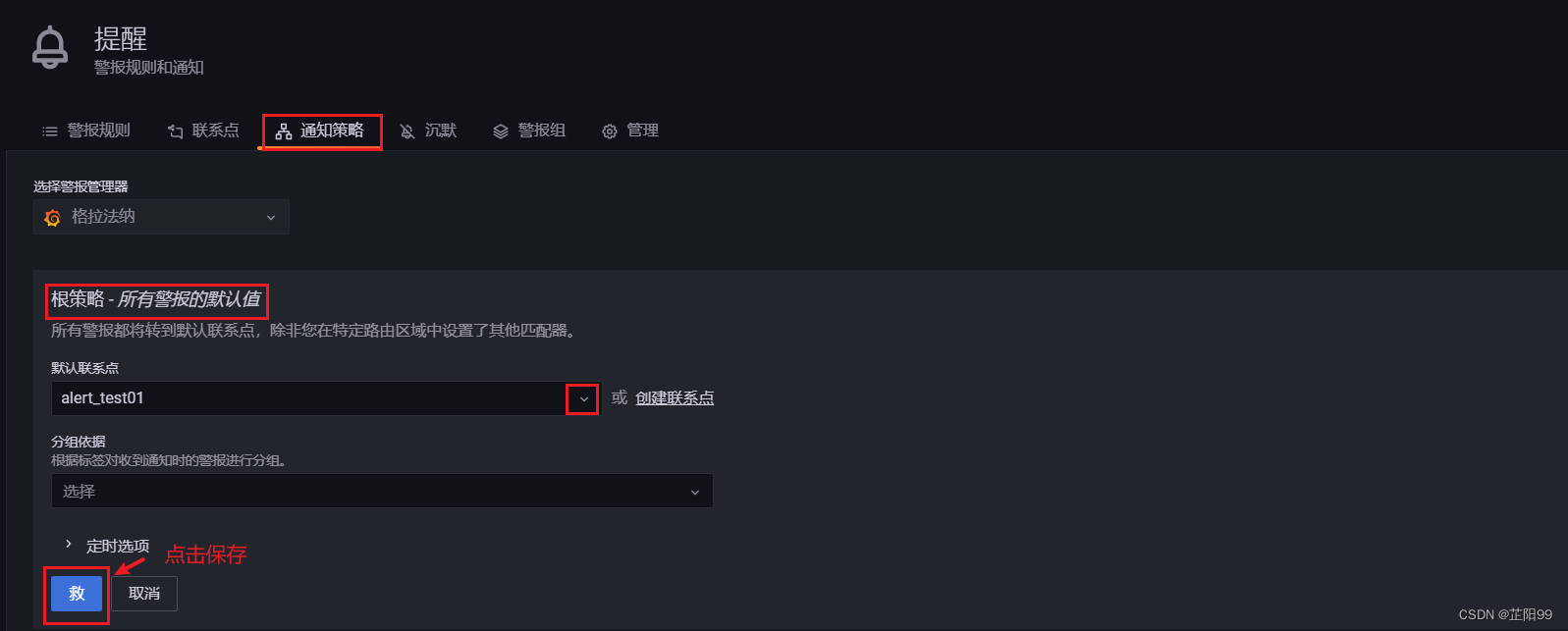
- 为通知策略绑定联系点
- 单击“通知策略”。
- 在“根策略 - 所有警报的默认值”区域,单击“编辑”。
- 在“默认联系点”列表中选择创建的联系点“alert-test01”。

更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)