
Kubernetes(K8S)集群搭建基础入门教程
K8s操作命令还有很多,这里我转载了一位博主的文章,对于K8s操作命令讲解的很全面,看这篇文章就足够了linkhttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttpshttps
上一篇文章讲了 K8s 相关组件知识点,这篇文章主要是搭建一个 Master 节点和多个 Node 节点的集群环境。
Kubernetes(K8s) 基本概念
前期准备
1、准备 3 台 centos 7 或者更高版本的虚拟机,主要用来安装 K8s 集群,下面是 3 台虚拟机的配置情况:
| IP | 操作系统 | 主机名称 | 配置 | 网络 |
|---|---|---|---|---|
| 192.168.2.124 | centos7.9 | k8s-master | 4vCPU/8G内存/20G硬盘 | NAT或者桥接模式 |
| 192.168.2.125 | centos7.9 | k8s-node01 | 4vCPU/8G内存/20G硬盘 | NAT或者桥接模式 |
| 192.168.2.126 | centos7.9 | k8s-node02 | 4vCPU/8G内存/20G硬盘 | NAT或者桥接模式 |
2、配置静态 IP
把虚拟机或者物理机配置成静态 IP 地址,这样是为了机器重新启动之后 IP 地址不会发生改变
命令:cat /etc/sysconfig/network-scripts/ifcfg-ens33
k8s-master
BOOTPROTO=static
IPADDR=192.168.2.124
GATEWAY=192.168.2.1
BROADCAST=192.168.2.255
DNS1=114.114.114.114
DNS2=8.8.8.8
k8s-node01
BOOTPROTO=static
IPADDR=192.168.2.125
GATEWAY=192.168.2.1
BROADCAST=192.168.2.255
DNS1=114.114.114.114
DNS2=8.8.8.8
k8s-node02
BOOTPROTO=static
IPADDR=192.168.2.126
GATEWAY=192.168.2.1
BROADCAST=192.168.2.255
DNS1=114.114.114.114
DNS2=8.8.8.8
修改配置文件以后重启网络服务才能使配置生效,重启网络服务命令如下:
systemctl restart network
如果对网络配置还不熟悉的小伙伴可以看我这篇文章进行配置:Linux 环境搭建一步到位,看这篇就够了!
3、设置系统主机名称
# 设置 192.168.2.124 主机名
hostnamectl set-hostname k8s-master
# 设置 192.168.2.125 主机名
hostnamectl set-hostname k8s-node01
# 设置 192.168.2.126 主机名
# hostnamectl set-hostname k8s-node02
4、配置 hosts 文件(三台主机都执行)
cat >> /etc/hosts << EOF
192.168.2.124 k8s-master
192.168.2.125 k8s-node01
192.168.2.126 k8s-node02
EOF
5、修改 yum 源
在 K8s 的 3 个主机节点上都执行
5.1、备份原来的 yum 源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
5.2、下载阿里的 yum 源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
5.3、配置安装 K8s 需要的 yum 源
cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
5.4、清理 yum 源
yum clean all
5.5、生成新的 yum 缓存
yum makecache fast
5.6、更新 yum 源
yum -y update
5.7、安装软件包
yum -y update
6、关闭防火墙并关闭防火墙自启
关闭防火墙,在 K8s 的各个节点都要关闭
systemctl stop firewalld && systemctl disable firewalld
7、时间同步
在 K8s 的各个节点执行命令
yum install ntpdate -y
ntpdate time.windows.com
8、关闭 selinux
在 K8s 的各个节点执行命令
# 永久
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 临时
setenforce 0
# 查看状态
sestatus
selinux 需要重启才可以生效
9、关闭 swap
在 K8s 的各个节点执行命令
# 临时
swapoff -a
# 永久
vi /etc/fstab
//注释或删除swap的行
#/dev/mapper/cs-swap none swap defaults 0 0
# 查看是否关闭
free -h
10、修改内核参数
在 K8s 的各个节点执行命令
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
11、服务器免密码登录
# 生成秘钥
ssh-keygen -t rsa
进行三次回车
# 通过 scp 把生成的 id_rsa.pub(公钥)内容复制到目标主机中的 /root/.ssh/authorized_keys 文件下
scp -p ~/.ssh/id_rsa.pub root@192.168.2.125:/root/.ssh/authorized_keys
scp -p ~/.ssh/id_rsa.pub root@192.168.2.126:/root/.ssh/authorized_keys
# 服务器上进行免密连接测试
ssh root@192.168.2.125
安装 Docker
在 K8s 的各个主机都需要安装 Docker,如果本机已装 Docker 可以直接忽略了。
# 获取 Docker yum源
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 查看 Docker 版本
yum list docker-ce --showduplicates | sort -r
# 安装 Docker
yum -y install docker-ce-18.06.3.ce-3.el7
# 修改 docker 配置文件
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
# 重启docker服务
systemctl daemon-reload && systemctl enable docker && systemctl restart docker
开启 bridge 模式
在 K8s 的各个节点执行命令
# 临时
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 1 > /proc/sys/net/bridge/bridge-nf-call-ip6tables
# 永久
echo """
vm.swappiness = 0
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
""" > /etc/sysctl.conf
# 配置生效
sysctl -p
开启 ipvs
启用 ipvs 而不使用 iptables 的原因,因为我们在用到 K8s 的时候,会用到数据包转发,如果不开启 ipvs 将会使用 iptables,但是效率低,所以官网推荐需要开通 ipvs 内核,在 K8s 的各个节点都需要开启
# 配置
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in \${ipvs_modules}; do
/sbin/modinfo -F filename \${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe \${kernel_module}
fi
done
EOF
# 变成可执行文件,让这个配置生效
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
部署 K8s 集群
1、目前生产部署 Kubernetes 集群主要有两种方式:
- Kubeadm:Kubeadm 是一个 K8s 部署工具,提供 kubeadm init 和 kubeadm join,用于快速部署 Kubernetes 集群。
- 二进制:从 github下 载发行版的二进制包,手动部署每个组件,组成 Kubernetes 集群。
官方地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
本次使用 Kubeadm 的方式搭建集群,建议在生产中部署 Kubernetes 集群使用二进制方式,Kubeadm 快速帮我们搭建好不容易发现问题,比如配置问题。
2、所有主机安装 Kubeadm,Kubelet 和 Kubectl
由于版本更新频繁,这里指定版本号部署
# 安装
yum install -y kubelet-1.23.0 kubeadm-1.23.0 kubectl-1.23.0
# 安装完成以后不要启动,设置开机自启动即可
systemctl enable kubelet
3、初始化 K8s 集群,在 K8s 的 master 节点操作
注意 api-server 的 IP 必须指定为 master 的 IP
kubeadm init \
--apiserver-advertise-address=192.168.2.124 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16\
--ignore-preflight-errors=all
- apiserver-advertise-address:指定 Maste r的那个 IP 地址与其他节点通信
- image-repository:由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址
- kubernetes-version :K8s 版本,与上面安装的一致,使用命令查看:rpm -q kubeadm
- service-cidr:集群内部虚拟网络,Pod 统一访问入口
- pod-network-cidr:Pod 网络,与下面部署的 CNI 网络组件 yaml 中保持一致
- ignore-preflight-errors:忽视告警错误,加上 --ignore-preflight-errors=all 参数即可
初始化过程我们看一下打印的日志做了那些操作
- [init]:指定版本进行初始化操作
- [preflight] :初始化前的检查和下载所需要的 Docker 镜像文件
- [kubelet-start] :生成 kubelet 配置文件 ”/var/lib/kubelet/config.yaml” 没有这个文件 kubelet 无法启动,所以初始化之前的 kubelet 实际上启动失败。
- [certificates]:生成 Kubernetes 使用的证书,存放在 /etc/kubernetes/pki 目录中。
- [kubeconfig] :生成 KubeConfig 文件,存放在 /etc/kubernetes 目录中,组件之间通信需要使用对应文件。
- [control-plane]:使用 /etc/kubernetes/manifest 目录下的 YAML 文件,安装 Master 组件。
- [etcd]:使用 /etc/kubernetes/manifest/etcd.yaml 安装 Etcd 服务。
- [wait-control-plane]:等待 control-plan 部署的 Maste r组件启动。
- [apiclient]:检查 Master 组件服务状态。
- [uploadconfig]:更新配置
- [kubelet]:使用 configMap 配置 kubelet。
- [patchnode]:更新 CNI 信息到 Node 上,通过注释的方式记录。
- [mark-control-plane]:为当前节点打标签,打了角色 Master,和不可调度标签,这样默认就不会使用 Master 节点来运行 Pod。
- [bootstrap-token]:生成 token 记录下来,后边使用 kubeadm join 往集群中添加节点时会用到
- [addons]:安装附加组件 CoreDNS 和 kube-proxy
我们需要把初始化成功后输出的信息手动执行,如下所示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.124:6443 --token wo6cdc.7xfvjypi59nt6vmc \
--discovery-token-ca-cert-hash sha256:b0ab38b8588422527ba80a2b51ab98154400ff3fac93108129bb2a45a01d61f6
3.1、创建 kube 目录,添加 kubectl 配置
因为非生产环境,所以我使用 root 用户操作,建议用普通用户运行以下三个命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
3.2、配置 Pod 网络插件
使用命令 kubectl get nodes 查看 master 的状态是未就绪,出现 NotReady
之所以是这种状态是因为还缺少一个附件 flannel 或者 Calico,没有网络各 Pod 是无法通信的,所以执行以下命令下载 kube-flannel.yml 文件
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

可以看到很多东西被创建了出来,还需要查看 flannel 是否处于正常启动并运行的状态,才算正在的部署完成
查看 flannel 镜像是否有被拉取下来

可以看到 flannel 镜像已经下载下来了
这里注意下载成功以后 master 状态还是 NotReady 说明还没有就绪,需要等一会儿,然后节点就就绪了;
出来以下图所示,可以看到 master 状态变成了 Ready

3.3、将 k8s-node01 和 k8s-node02 加入到集群
接下来把 node 节点加入 Kubernetes master 中,在 Node 主机上执行
向集群添加新节点,执行的命令就是 kubeadm init 最后输出的 kubeadm join 命令
kubeadm join 192.168.2.124:6443 --token wo6cdc.7xfvjypi59nt6vmc \
--discovery-token-ca-cert-hash sha256:b0ab38b8588422527ba80a2b51ab98154400ff3fac93108129bb2a45a01d61f6
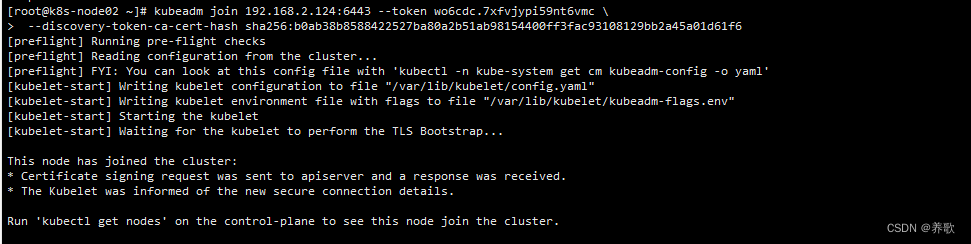
提示 This node has joined the cluster,意味着 node 节点初始化完成。
默认的 token 有效期为 24 小时,当过期之后,该 token 就不能用了,这时可以使用如下的命令创建 token
kubeadm token create --print-join-command
创建一个永不过期的 token
kubeadm token create --ttl 0
3.4、验证集群
3.4.1、使用 kubectl get nodes 命令查看

3.4.2、查看所有命名空间的所有 pod
kubectl get pods --all-namespaces -o wide

3.4.3、查看集群健康状态
kubectl get cs

至此我们的 K8s 环境就搭建好了。
安装 K8s-Dashboard
这是 K8S 的可视化工具,用来查看集群信息。如果不需要,可以不用执行这一步
1、下载 yaml 文件
GitHub - kubernetes/dashboard: General-purpose web UI for Kubernetes clusters
使用如下命令下载 recommended.yaml
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.4/aio/deploy/recommended.yaml
2、修改默认配置
默认 Dashboard 只能集群内部访问,为了能够从集群外部也能访问 Dashboard,修改其中 kubernetes-dashboard 的 service ,指定 nodePort 端口为 50001,新增 type 类型为 nodePort
vi recommended.yaml
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort //新增
ports:
- port: 443
targetPort: 8443
nodePort: 30218 //新增
selector:
k8s-app: kubernetes-dashboard
上面配置项的解释:
- apiVersion:指定api版本,此值必须在kubectl api-versions中
- Kind:指定创建资源的角色/类型
- metadata:资源的元数据/属性
- name:资源 Service 类型的名称,在同一个 namespace 中必须唯一
- namespace:资源 Service 所属的命名空间
- spec:资源规范字段
- selector:标签选择器,用于确定当前 Service 代理哪些 Pod,仅适用于 ClusterIP、NodePort 和 LoadBalancer 类型。如果类型为 ExternalName,则忽略。
- type:NodePort 类型可以对外暴露,让外部访问这个集群,主要有 ClusterIP、NodePort、LoadBalancer 和 ExternalName,默认ClusterIP
- ports:Service 对外暴露的端口列表
- port:Service 服务监听的端口,Service 在集群内部暴露的端口
- targetPort:Pod 端口容器暴露的端口
- nodePort:对外暴露的端口号,如果不指定则随机生成一个端口号
3、部署 Dashboard
kubectl apply -f recommended.yaml
kubectl apply 命令是一种申明式的 API 调用办法,通过将 Pod 的配置编写在一份 yaml 文件中,再调用 API,进行 Pod 部署的形式

4、查看 pod,svc 状态:
kubectl get pod,svc -n kubernetes-dashboard

5、如果配置有问题需要删除 Dashboard 执行以下命令就可以
# 查询 Pod
kubectl get pods --all-namespaces | grep "dashboard"
# 删除 Pod
kubectl delete deployment kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete deployment dashboard-metrics-scraper --namespace=kubernetes-dashboard
# 查询 service
kubectl get service -A
# 删除 service
kubectl delete service kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete service dashboard-metrics-scraper --namespace=kubernetes-dashboard
# 删除账户和密钥
kubectl delete sa kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete secret kubernetes-dashboard-certs --namespace=kubernetes-dashboard
kubectl delete secret kubernetes-dashboard-key-holder --namespace=kubernetes-dashboard
6、访问 Web
访问指定的 30218 端口,master 节点 IP 为 192.168.2.124,通过 chrome 浏览器访问地址: https://192.168.2.124:30218
如果因为证书问题,解决 k8s 自签名 SSL 验证不通过的问题,以下是 chrome 浏览器的解决方案:
Chrome 地址栏输入:chrome://flags/#allow-insecure-localhost
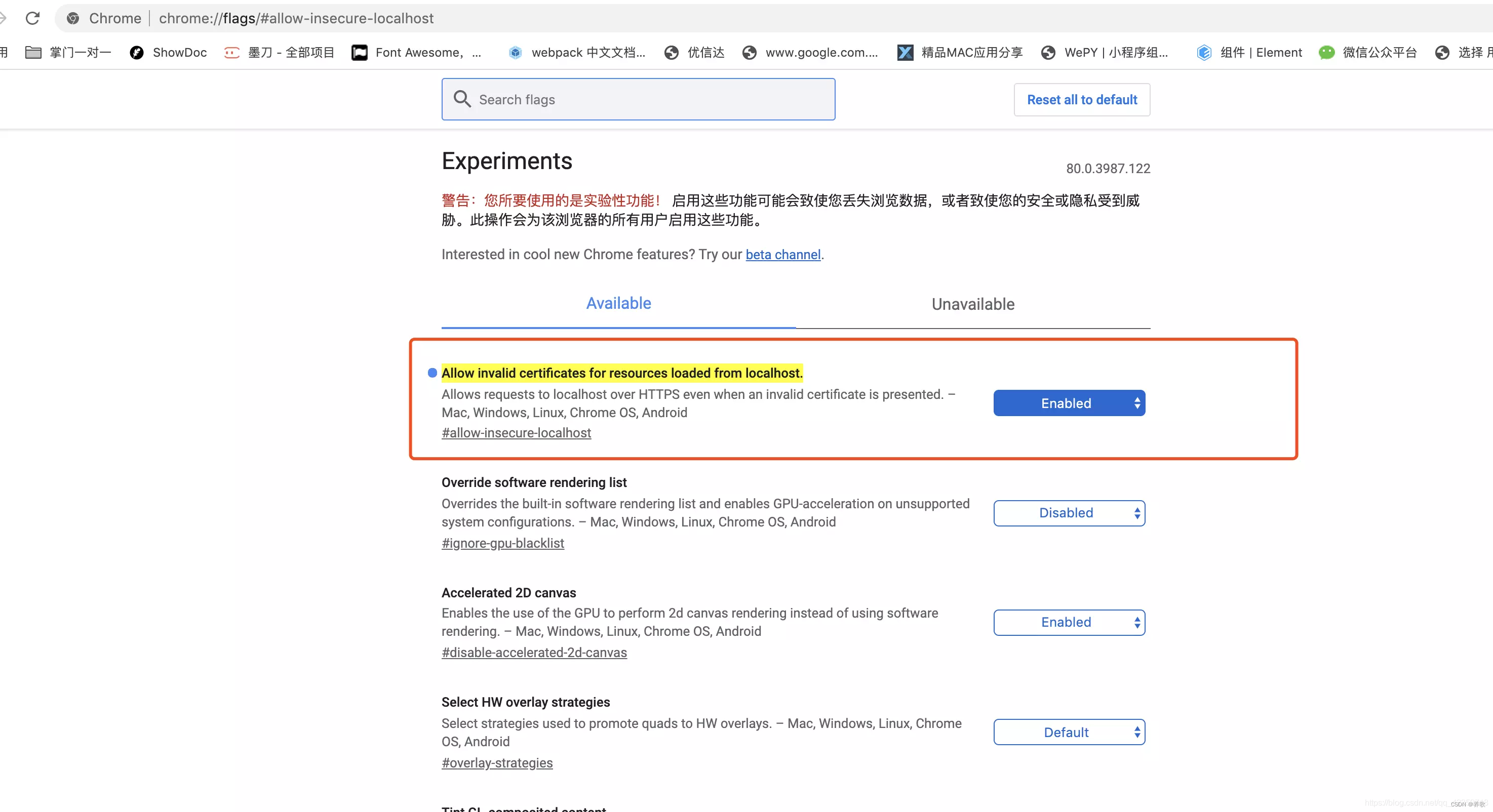
选择 Allow invalid certificates for resources loaded from localhost 的选项即可。
7、创建访问账户,获取 token
7.1、创建账号
kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
7.2、用户授权
kubectl create clusterrolebinding dashboard-admin-rb --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
7.3、获取登录 Dashboard 需要的 token
kubectl describe secrets -n kubernetes-dashboard $(kubectl -n kubernetes-dashboard get secret | awk '/dashboard-admin/{print $1}')

7.4、使用 token 登录
在登录页面上输入上面的 token 后进入
关于这些功能这里就不讲解了,这不是主要的,大家可以自己去操作一遍。
使用 Deployment 构建部署 nginx 服务
这里主要是让大家熟悉在 K8s 中,如何快速部署一个应用的大致流程,以 nginx 为例来进行操作。
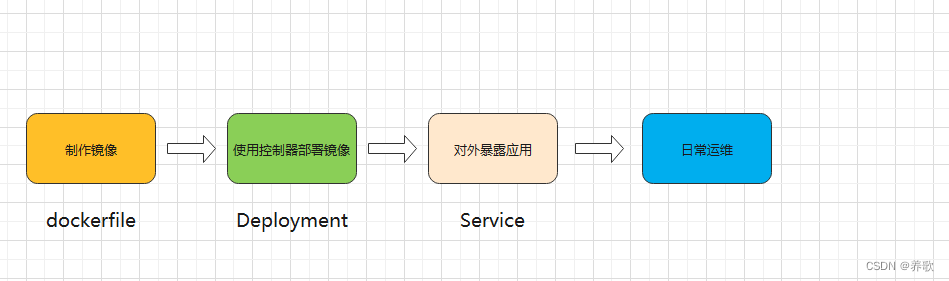
首先使用 dockerfile 构建镜像,然后可以传到镜像仓库,再使用 K8s 控制器(Deployment)去部署镜像,然后再使用 Service 去对外暴露应用,最后对应用进行监控、收集日志等等。
1、在 master 节点上使用 Deployment 控制器部署镜像:
# 基于 nginx 镜像,创建一个 Deployment,并将 nginx 应用启动起来。这里 Deployment 后面的 nginx 是自定义的一个 Deployment名称,可以是任何名字。image 参数指定的是镜像名称,这里表示 nginx 镜像 ,replicas 参数是副本数,可以理解为容器,需要创建几个容器的意思
kubectl create deployment nginx --image=nginx --replicas=3
2、查看 Pod
kubectl get pods

因为上面我们指定了 3 个副本,所以这里创建了 3 个容器,如果状态为 ContainerCreating 是因为还在启动中
3、查看 nginx-85b98978db-gcvtk 详细情况
kubectl describe pod nginx-85b98978db-gcvtk
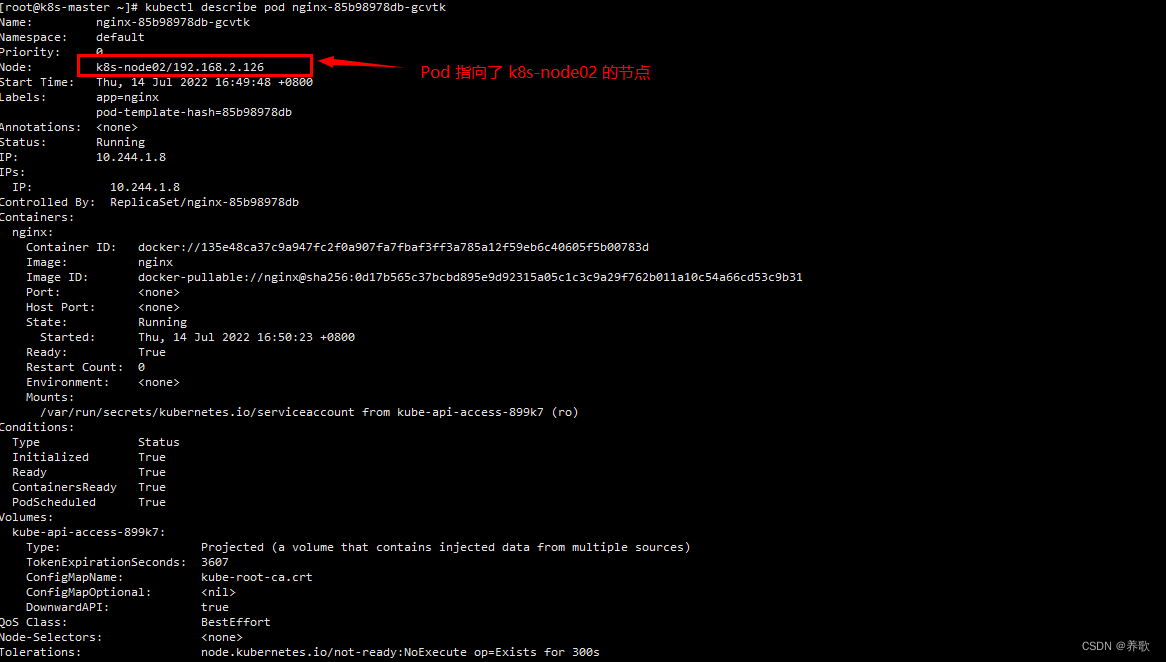
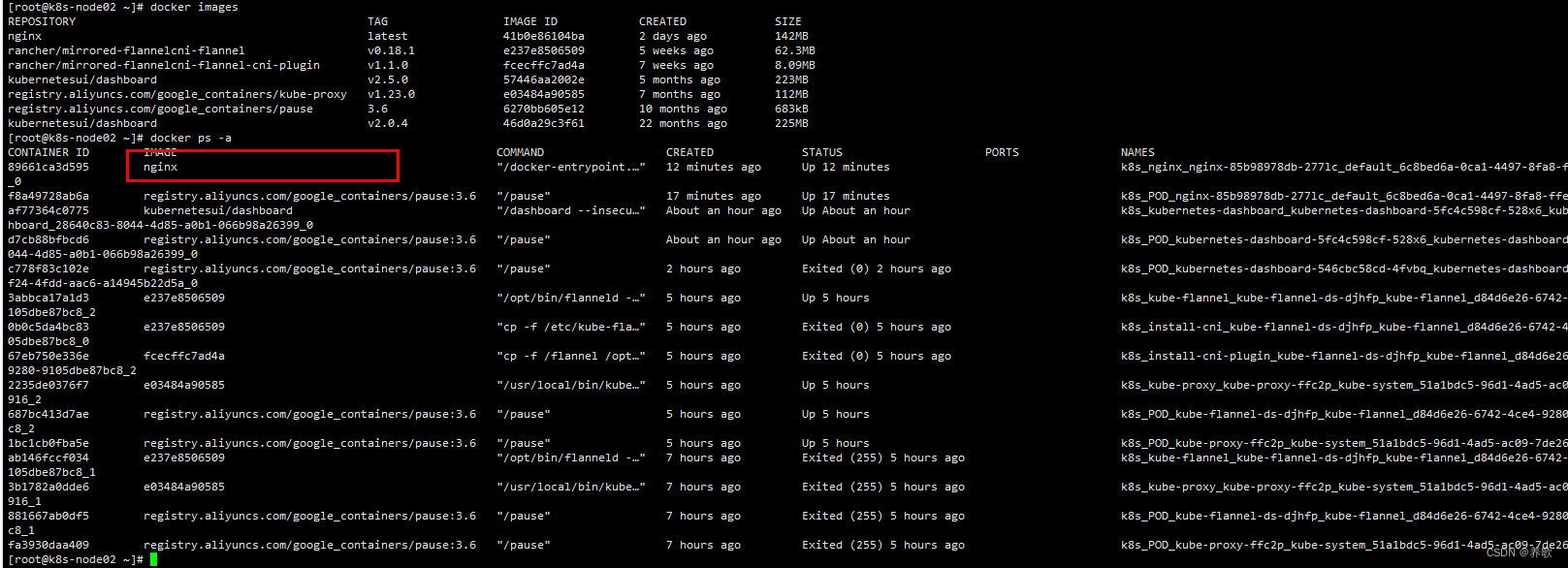
我们可以在 node 节点中查看镜像已经拉取成功

而且在 node 节点中可以看到已经有了 nginx 容器
这里我们查看一下 replicas 状态
kubectl get replicaset

定义容器 3 个,只运行了 2 个,剩一个没有使用
下一步就是把容器暴露出去
4、使用 Service 将 Pod 暴露出去
在 master 节点执行
# --port 这个端口是 K8s 集群内部使用的,这里我们还用不到,但是必须指定的。--target-port是镜像中服务运行的端口,比如 nginx 默认端口是 80,这里就写 80 端口,--type=NodePort 是通过 NodePort 类型,在 Pod 所在的节点进行绑定端口,让外部客户端访问 Pod
kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort
# 查看 Service
kubectl get service

80(容器内部端口访问):32210 (外部端口)
这里的 80 是用于 node 之间通信的端口,比如说当前有多个 node 节点时,node 之间对该 nginx 应用进行访问的时候使用 80 端口。而冒号后面的 32210 这个端口是用于外部对 nginx 的访问,比如我们通过浏览器对 nginx 服务进行访问时,通过 80 端口是访问不到的,必须通过 32210 这个端口,这个端口是随机生成。
5、访问 nginx
下面我们通过 32210 端口访问 nginx 服务 :http://192.168.2.124:32210/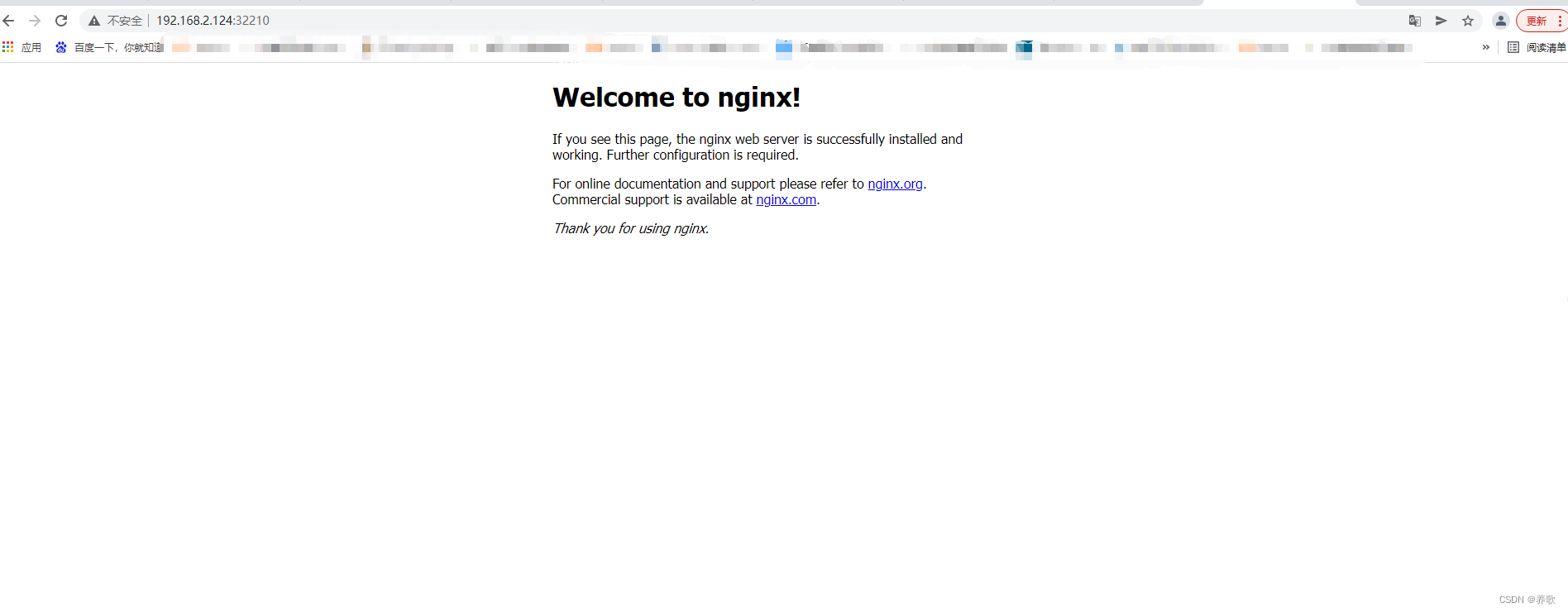
出来 nginx 页面说明部署成功了
6、删除 nginx 命令
# 删除 service
kubectl delete service nginx
# 删除 nginx 的控制器
kubectl delete deployment nginx
# 删除 Pod
kubectl delete pod nginx-85b98978db-w87hr(Pod 的名字)
使用 Deployment 升级 nginx 版本
当集群中的某个服务需要升级时,需要停止目前与该服务相关的所有 Pod,然后下载新版本镜像并创建新的 Pod。集群规模比较大,需要先全部停止然后逐步升级的方式会导致较长时间的服务不可用。K8s提供了滚动升级功能来解决上述问题。
滚动升级:K8s 对 Pod 升级的默认策略,通过使用新版本 Pod 逐步更新旧版本 Pod,实现零停机发布,用户感觉不到。
1、创建 Deployment
创建 Deployment 时自动创建 ReplicaSet,Pod 由 ReplicaSet 创建和管理
cat > nginx-deployment.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.16
name: nginx
---
apiVersion: v1
kind: Service
metadata:
name: web
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 31100
type: NodePort
EOF
2、部署 nginx
kubectl apply -f nginx-deployment.yaml
查看当前运行的 Pod,出现以下数据表示已经部署成功

在以上的页面,如果是升级的话,这里会一直滚动更新最终状态变为 Running,大家可以更新以后使用命令看效果
指定版本的 nginx 镜像也已经 pull 下来了
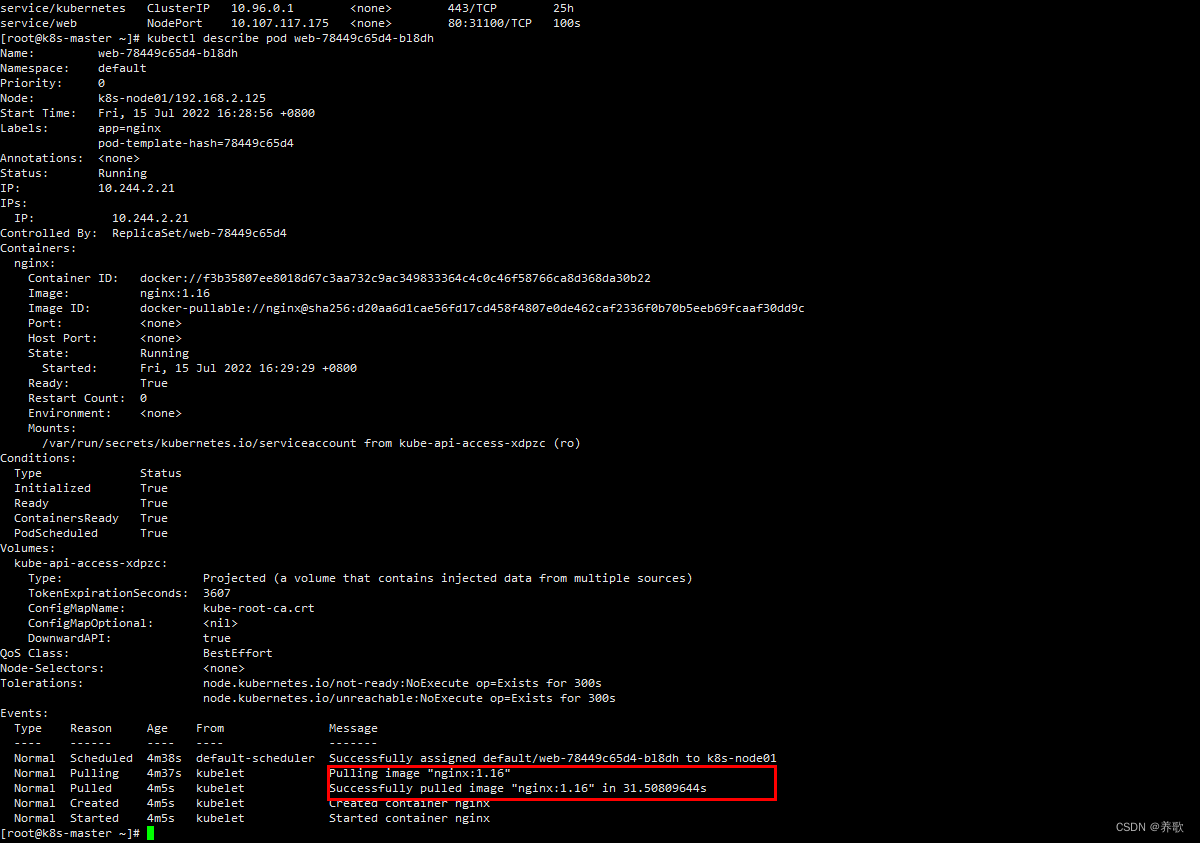
使用如下命令也可以查看详情,看到是指定的版本
kubectl describe pod web-78449c65d4-bl8dh(Pod名称) | tail
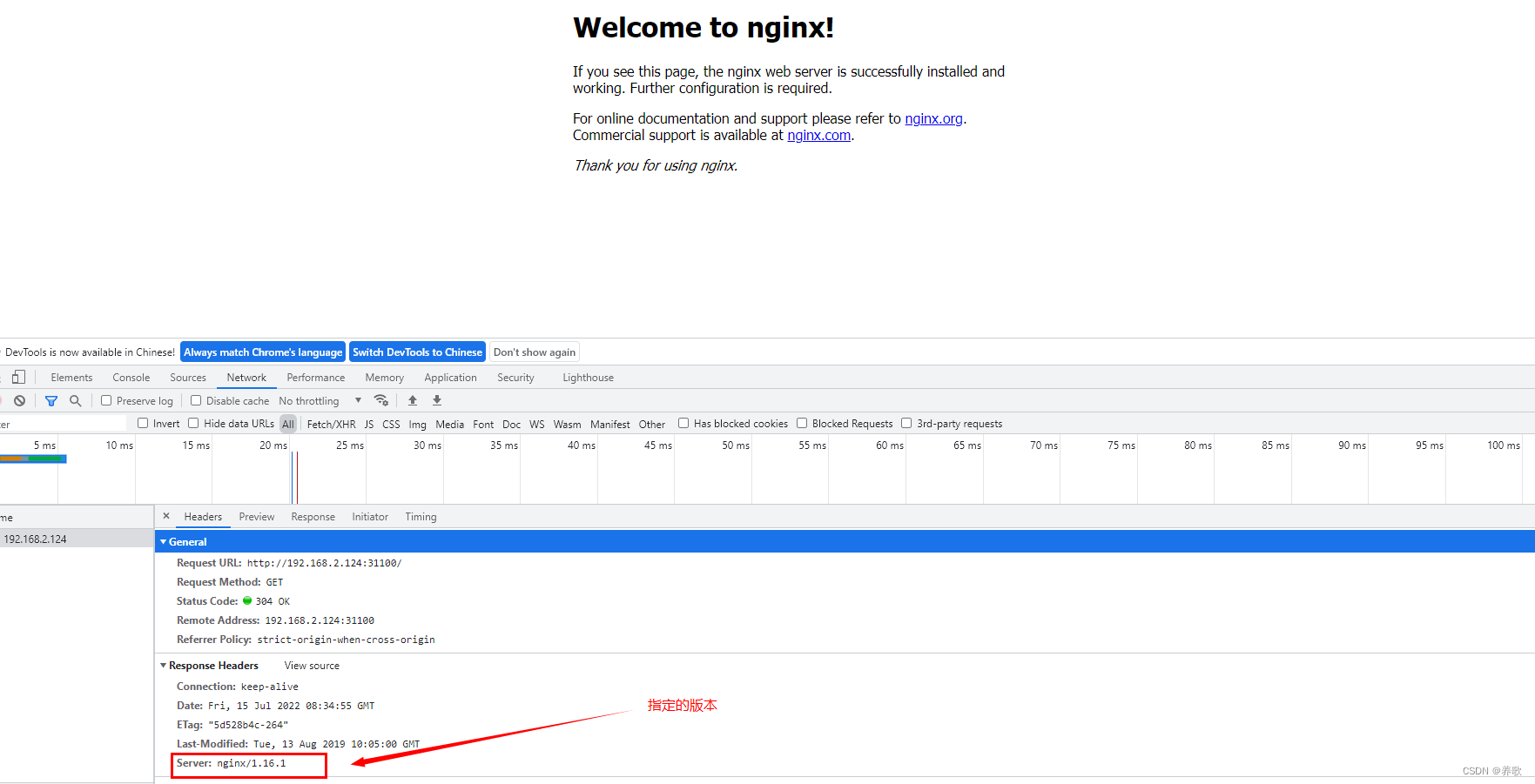
还有一种方式通过 chrome 浏览器访问 nginx ,如下所示:
3、滚动升级 nginx
上面我们通过配置已经成功部署了 nginx,接下来我们把 Pod 镜像需要更新为 nginx:1.17

再次通过以下命令更新为 1.17.1 版本
kubectl apply -f nginx-deployment.yaml
可以看到版本已经更新了
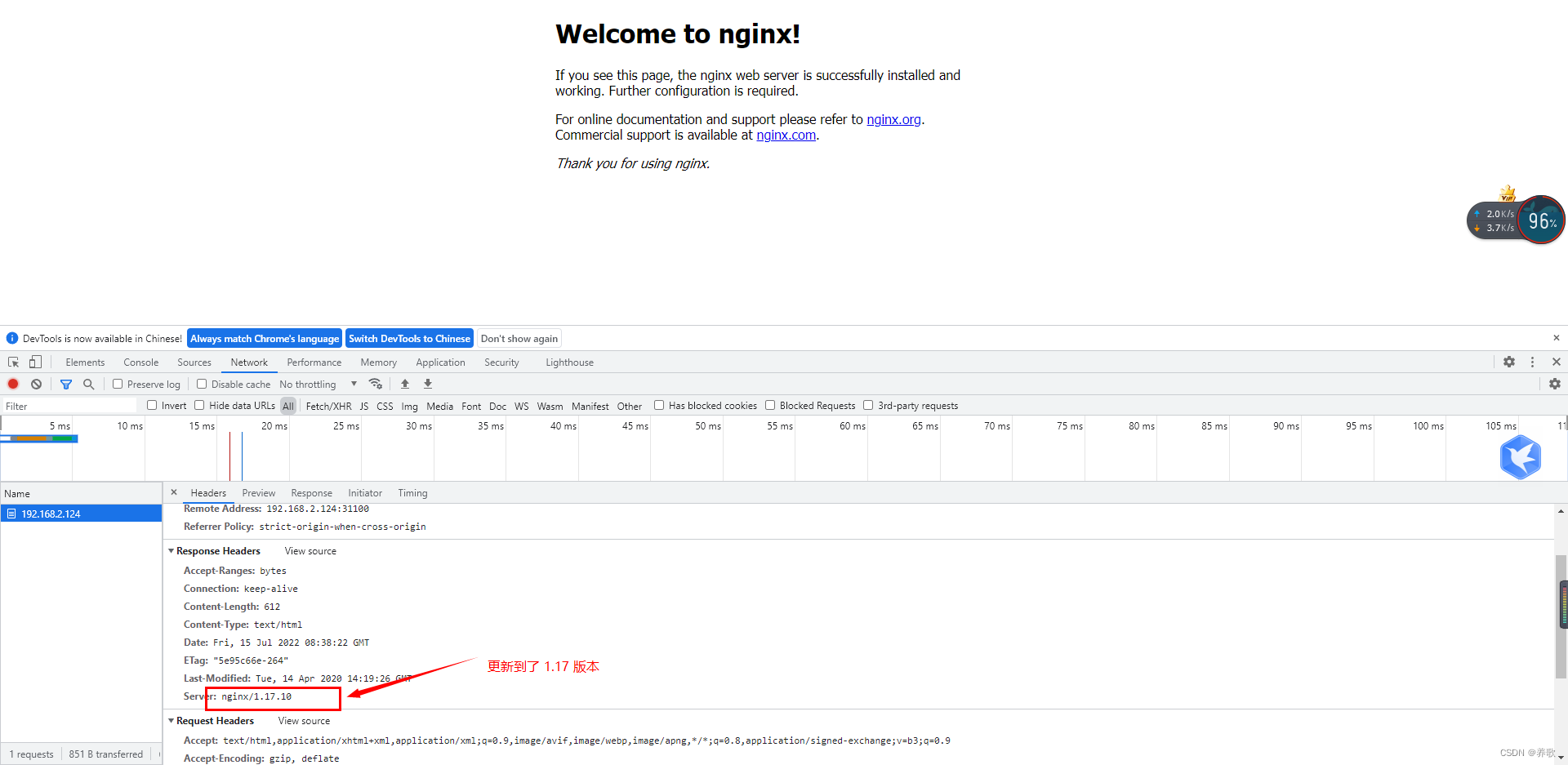
通过以下命令我们可以查看 nginx 更新的过程
kubectl describe deployment web
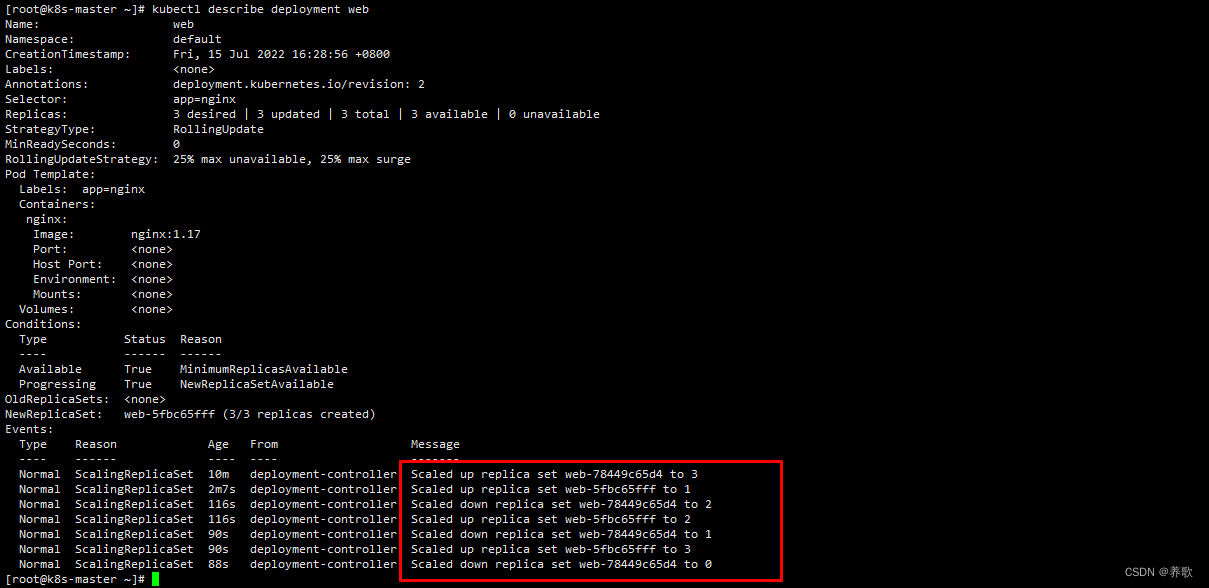
Deployment 升级 Pod 的过程:
- 初始化创建 Deployment 时,创建了一个 ReplicaSet,ReplicaSet 管理 Pod,所以 ReplicaSet 帮我们创建了 3 个 Pod 副本
- 当更新 Deployment 时创建新的 ReplicaSet,将新的副本数设置为 1,然后将旧的 ReplicaSet 副本数设置为 2
- 下面的步骤继续按照相同的更新策略对新旧两个 ReplicaSet 进行逐步调整
- 最后新的 ReplicaSet 运行了 3 个新的 Pod 副本,旧的 ReplicaSet 副本数则缩减为 0
当然,我们还可以不用通过修改配置更新 nginx,通过以下命令实现:
把 nginx 镜像 1.17 版本修改为 1.18 版本
# kubectl set image 资源类型+名字(web)原镜像名=新镜像名:版本号
kubectl set image deployment web nginx=nginx:1.18
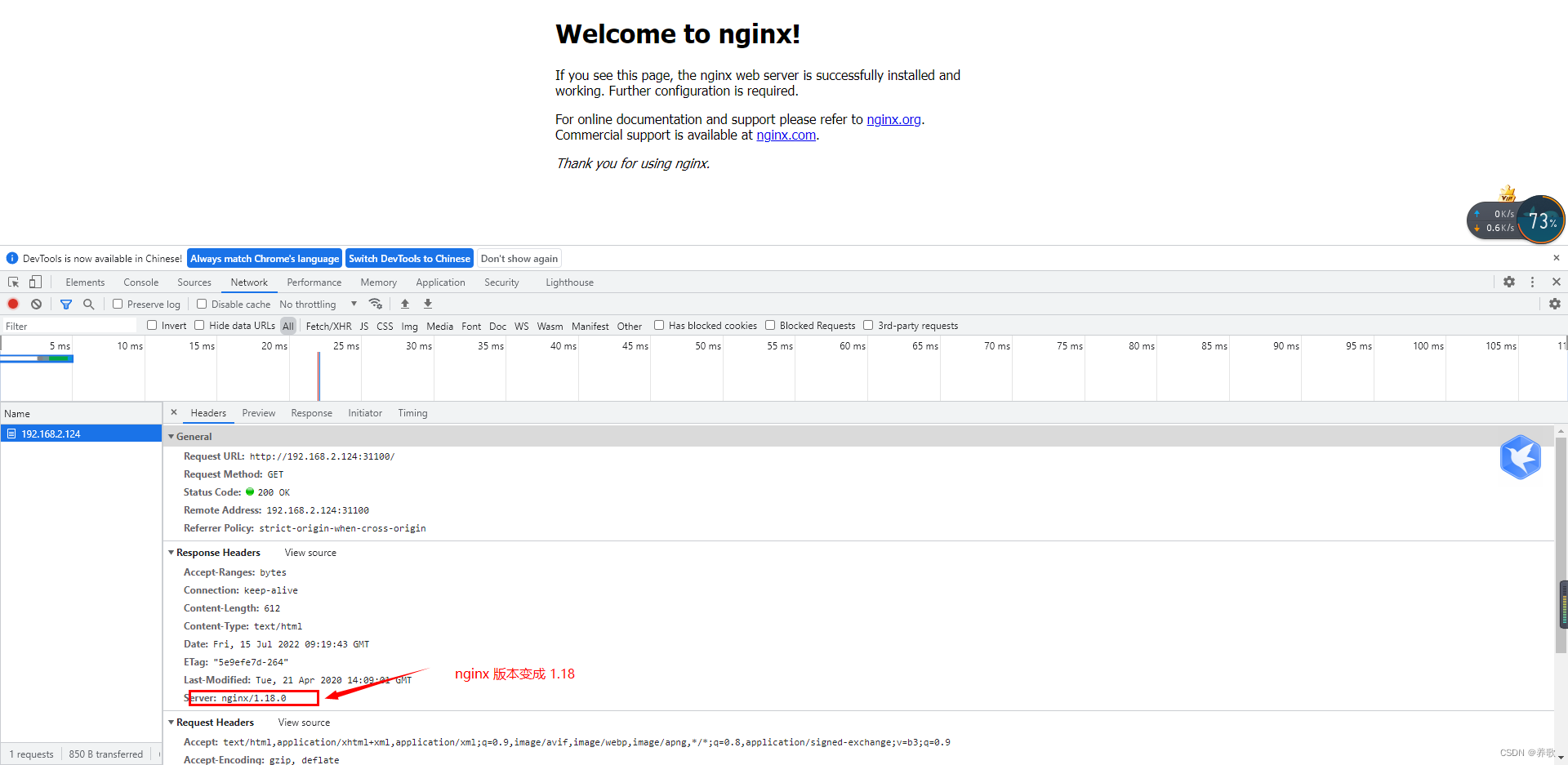
既然能升级 nginx 的版本,必然可以回滚旧版本,下面我们来实现回滚功能
使用 Deployment 回滚 nginx 版本
当我们更新 nginx 为最新版本时,发现最新版本有问题,不稳定,这时我们就需要回滚到上一个版本。
1、查看 nginx 历史版本
kubectl rollout history deployment web

这里有个问题就是 CHANGE-CAUSE 这列 为 none,如果更新很麻烦,我们不知道这些版本到底干了些什么,这里我会在下面实现这个功能。
2、回滚 nginx 历史版本
kubectl rollout undo deployment web
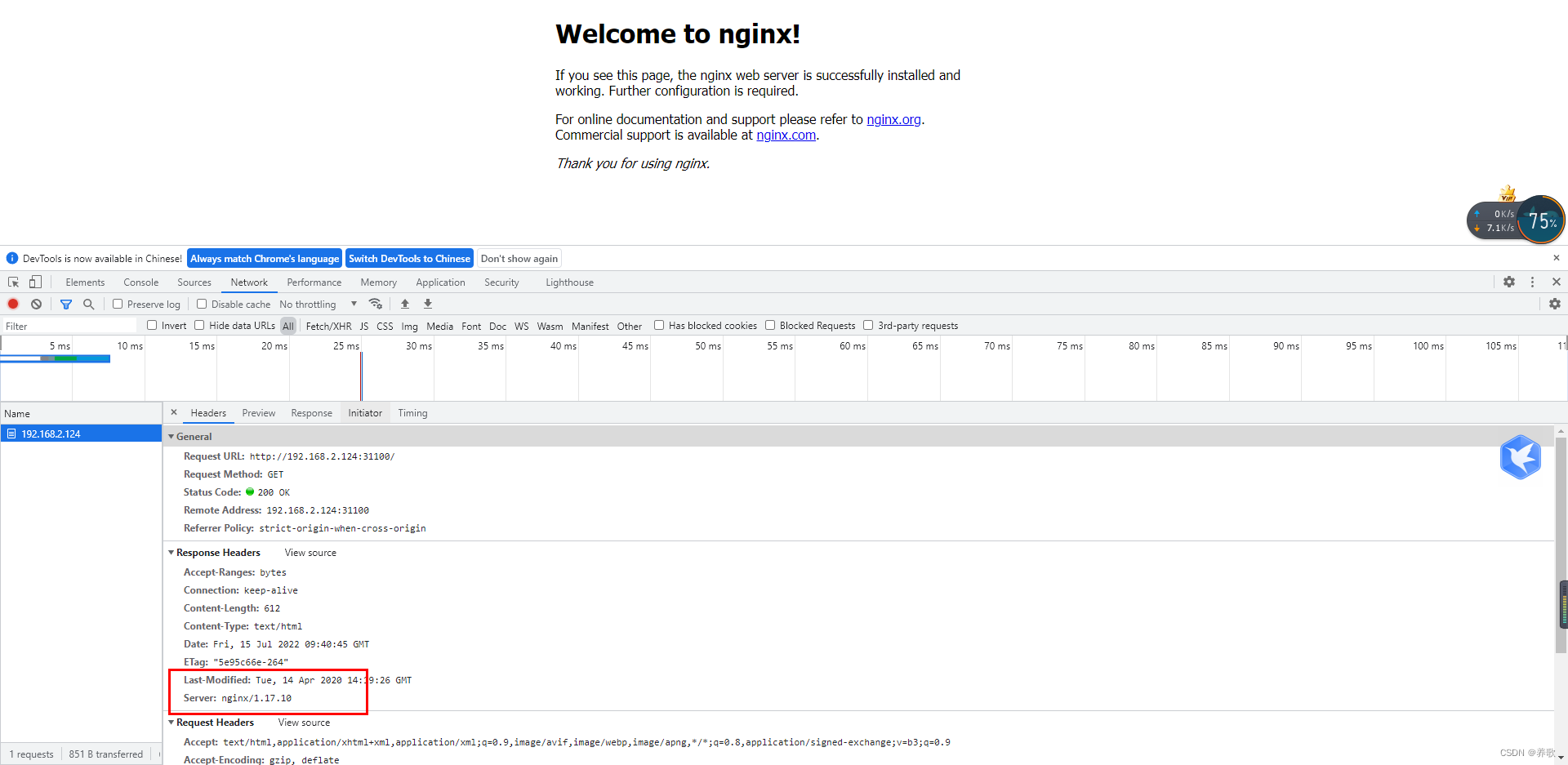
nginx 回滚到了上一个版本
再次查看 nginx 历史版本, 发现版本 2 被删除,新增了历史版本 3,即现在回滚成功,该 Deployment 回滚到第 2 个版本

我们这里还可以回滚到指定版本
kubectl rollout undo deployment/web --to-revision=3

下面这个就是回滚过程中状态的改变,从 Terminating 到 Running,新旧 Pod 转换


下面我们解决上面说的一个问题,就是更新版本 CHANGE-CAUSE 为 none 的问题,使用如下命令:
kubectl set image deployment web nginx=nginx:1.19 --record=true

这样就记录了我们做了哪些操作,进行回滚的话可以知道该回滚哪个版本,比为 none 要清楚一点。
使用 Deployment 水平扩容和缩容
在实际的业务场景中,我们经常会遇到某个服务需要扩容的场景,例如大型活动的秒杀、对服务的压测等等,由于资源紧张,工作负载降低这些都会需要对服务实例进行扩缩容的操作。
在 Deployment 控制器中 replicas 参数控制着 Pod 副本的数量
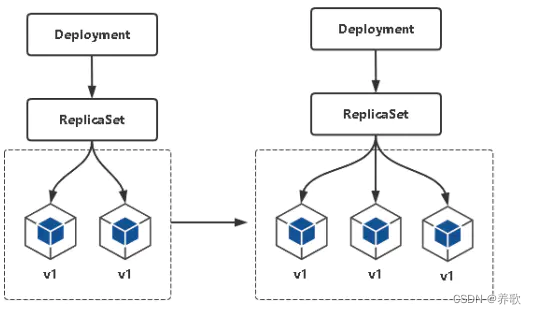
扩容有两种方式:
- 第一种方式:修改 yaml 文件中的 replicas 值,在进行 apply
- 第二种方式:使用命令:kubectl scale deployment 控制器名 --replicas=期望 Pod 副本数
第一种方式:
这里我们把 replicas 设置为 5 ,在使用 apply 操作一遍
kubectl apply -f nginx-deployment.yaml

可以看到创建了 5 个 Pod

第二种方式:
# kubectl scale deployment 控制器名 --replicas=期望 Pod副本数
kubectl scale deployment web --replicas=3
我们将 Pod 的副本数从 5 缩容到 3

以上的都是手动去扩缩容,还有一种就是自动扩缩容,K8s 通过 HPA 控制器,用于实现基本 CPU 使用率进行自动 Pod 扩容和缩容的功能,这个自动扩缩容的大家可以去尝试自己操作一遍,这里不在讲解,以上就是本章所有的内容。
最后
K8s 操作命令还有很多,这里我转载了一位博主的文章,对于 K8s 操作命令讲解的很全面,看这篇文章就足够了
执行删除 kubeadm 脚本
cat > test.sh << EOF
#!/bin/bash
kubeadm reset -f
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
yum -y remove kubeadm* kubectl* kubelet* docker*
reboot
EOF

开源、云原生的融合云平台
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)