【博客417】k8s apiserver缓存机制避免轮询风暴
参考链接:https://mp.weixin.qq.com/s/qkCtAry25kzmuglIPXad3A绝大部分情况下,apiserver 直接从本地缓存提供服务(因为它缓存了集群全量数据);某些特殊情况,例如:考虑下面几个 LIST 操作:1、 LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0这里同时传了两个
k8s apiserver缓存机制避免轮询风暴
参考链接:https://mp.weixin.qq.com/s/qkCtAry25kzmuglIPXad3A
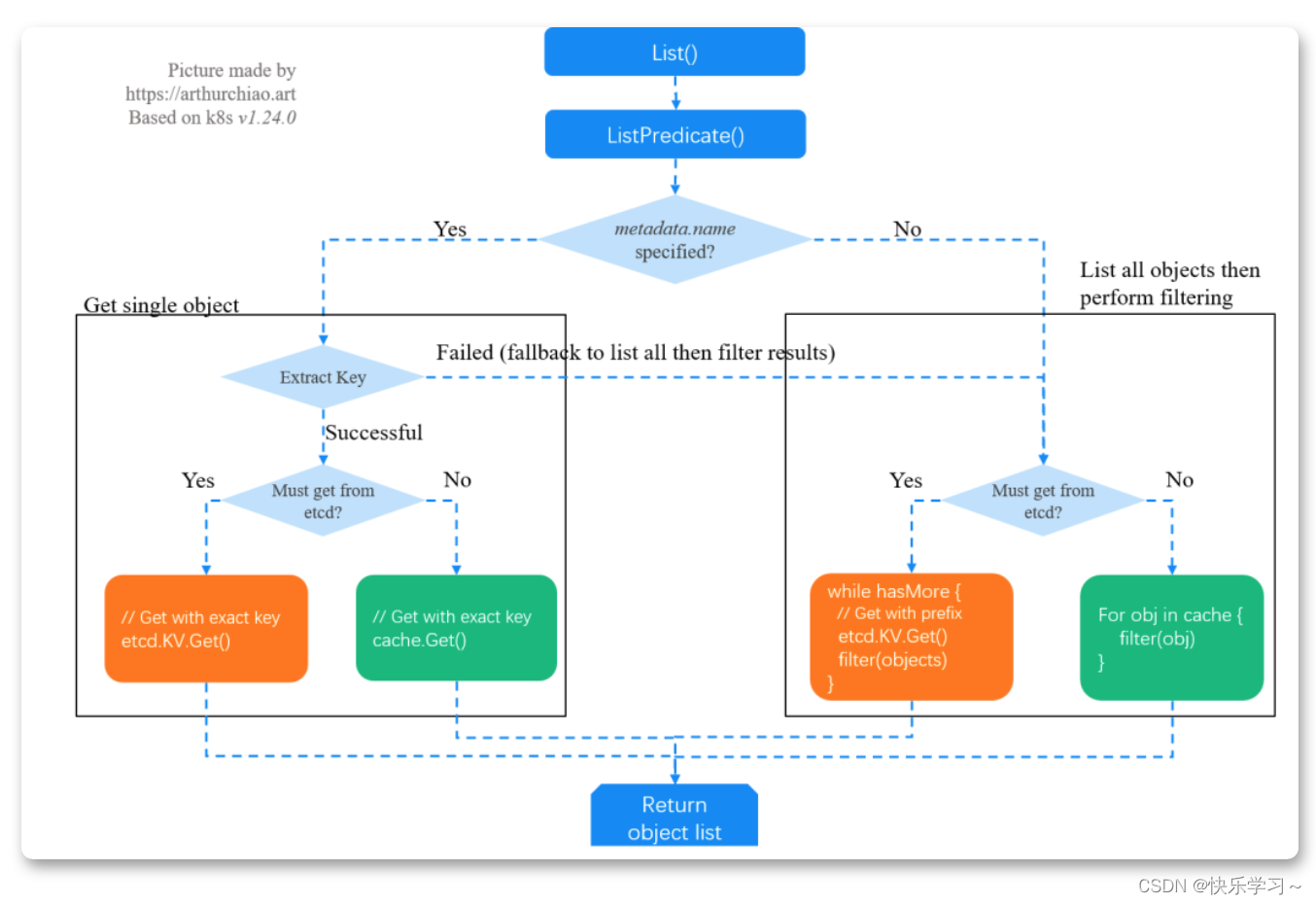
list流程

缓存架构
apiserver 就是挡在 etcd 前面的一个代理
+--------+ +---------------+ +------------+
| Client | -----------> | Proxy (cache) | --------------> | Data store |
+--------+ +---------------+ +------------+
infra services apiserver etcd
绝大部分情况下,apiserver 直接从本地缓存提供服务(因为它缓存了集群全量数据);
某些特殊情况,例如:
1、客户端明确要求从 etcd 读数据(追求最高的数据准确性),
2、apiserver 本地缓存还没建好
考虑下面几个 LIST 操作:
1、 LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0
这里同时传了两个参数,但 resourceVersion=0 会导致 apiserver 忽略 limit=500, 所以客户端拿到的是全量 ciliumendpoints 数据。
一种资源的全量数据可能是比较大的,需要考虑清楚是否真的需要全量数据
2、LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1
这个请求是获取 node1 上的所有 pods(%3D 是 = 的转义)。
这种行为是要避免的,除非对数据准确性有极高要求,特意要绕过 apiserver 缓存。
首先,这里没有指定 resourceVersion=0,导致 「apiserver 跳过缓存,直接去 etcd 读数据」;
其次,「etcd 只是 KV 存储,没有按 label/field 过滤功能」(只处理 limit/continue),
所以,apiserver 是从 etcd 拉全量数据,然后在「内存做过滤」,开销也是很大的
3、LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0
跟 2 的区别是加上了 resourceVersion=0,因此 apiserver 会从缓存读数据,「性能会有量级的提升」。
但要注意,虽然实际上返回给客户端的可能只有「几百 KB 到上百 MB」(取决于 node 上 pod 的数量、pod 上 label 的多少等因素), 但 apiserver 需要处理的数据量可能是「几个 GB」。
以上可以看到,不同的 LIST 操作产生的影响是不一样的,而客户端看到数据还有可能只 是 apiserver/etcd 处理数据的很小一部分。如果基础服务大规模启动或重启, 就极有可能把控制平面打爆。
List开销
List 请求可以分为两种:
1、List 全量数据:开销主要花在数据传输;
指定用 label 或字段(field)过滤,只需要匹配的数据。
大部分情况下,apiserver 会用自己的缓存做过滤,这个很快,因此「耗时主要花在数据传输」;
2、需要将请求转给 etcd 的情况:
etcd 只是 KV 存储,并不理解 label/field 信息,因此它无法处理过滤请求。实际的过程是:「apiserver 从 etcd 拉全量数据,然后在内存做过滤」,再返回给客户端。
因此除了数据传输开销(网络带宽),这种情况下还会占用大量 apiserver 「CPU 和内存」。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)