es查询-统计总数以及深度分页
es查询-统计总数以及深度分页
一、查询总数
1. ES 查询 hits 统计总数不准?
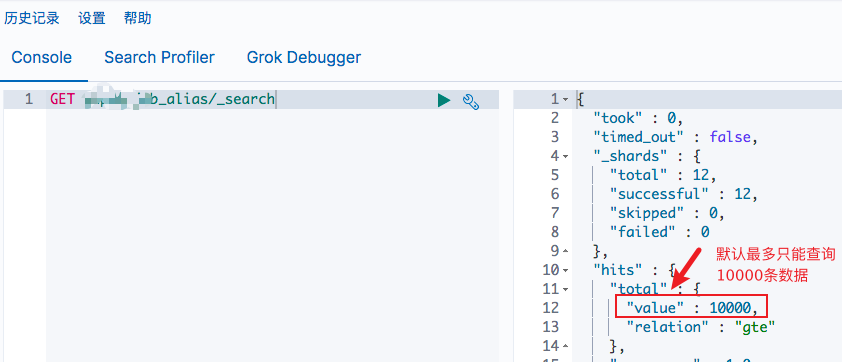
当我们使用 ES 的时候,有时会比较关心匹配到的文档总数是多少,所以在查询得到结果后会使用 hits.total.value 这个值作为匹配的总数,如下
图一
说明:这是因为,es官方默认限制索引查询最多只能查询10000条数据。
2. track_total_hits
平常数据量不大的情况下,这个数值没问题。但是当超出 10000 个数据量的时候,这个 value 将不会增长了,固定为 10000。这个时候很显然数量统计就不准了。
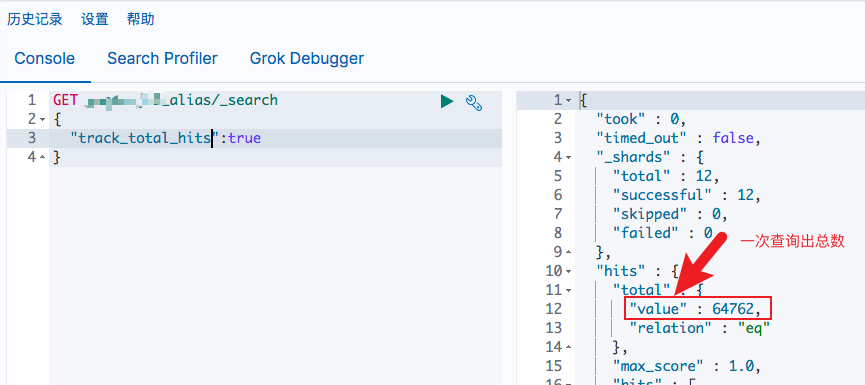
ES 为我们准备了这样一个参数来开启精确匹配 track_total_hits
这个时候返回值将是精确的:
图二
3. track_total_hits的使用场景
如果你的业务需求在超过 10000 这个阈值之后就不需要精准的计算的话,就不需要设置该值,毕竟匹配大量的文档是一个成本较高的操作,同样的如果你并不需要统计数量,那么将该值设置为 false "track_total_hits": false 也是一种优化检索效率的操作。
4. hits.total.relation
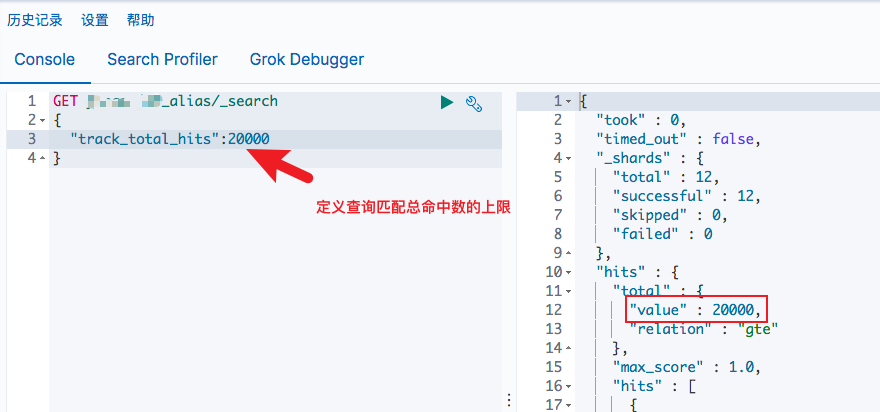
通过图一和图二,可以发现设置 track_total_hits 为 true 的时候返回 relation 的值是不一样的,gte 表示 hits.total.value 是查询匹配总命中数的上限。 eq 则表示hits.total.value 是准确计数。
因此,我们可以通过设置 track_total_hits 为整数,来自定义上限如:
二、查询数据
1. 查询超过10000条数据,开始报错
上面解决了需要统计超过10000条数据总数的问题,但是在查询具体数据的时候依然存在类似的问题。es官方默认限制索引查询最多只能查询10000条数据,查询第10001条数据开始就会报错:
result window is too large, from + size must be less than or equal to
解决方案:
1)第一种办法:在kibana中执行,解除索引最大查询数的限制
put _all/_settings
{
"index.max_result_window":200000
}
_all表示所有索引,针对单个索引的话修改成索引名称即可。
2)第二种办法:在创建索引的时候加上
1 "settings":{
2 "index":{
4 "max_result_window": 500000
5 }
7 }
三、深度分页
做分页查询的时候,我们需要考虑两个问题
- 性能要求,在硬件和查询效率中作出权衡
- 对大部分请求来说,都不会超过10000条,即不需要深度分页,当需要请求超过10000条时,就需要考虑我们的查询语句是否恰当
下面有几种分页方式:
1、方式一: from+size浅分页
"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。

1 GET test_alias/_search
2 {
3 "query": {
4 "match_all": {
5 }
6 },
7 "sort": [
8 {
9 "add_time": {
10 "order": "desc"
11 }
12 }
13 ],
14 "from":0,
15 "size": 2
16 }

其中,from定义了目标数据的偏移值,size定义当前返回的数目。默认from为0,size为10,即所有的查询默认仅仅返回前10条数据。
from/size的原理:
因为es是基于分片的,假设有5个分片,from=100,size=10。则会根据排序规则从5个分片中各取回100条数据数据,然后汇总成500条数据后,选择最后面的10条数据。
做过测试,越往后的分页,执行的效率越低。总体上会随着from的增加,消耗时间也会增加。而且数据量越大,就越明显。
说明:from+size查询在10000-50000条数据(1000到5000页)以内的时候还是可以的,但是如果数据过多的话,就会出现深分页问题。
2、方式二: scroll深分页
为了解决上面的问题,elasticsearch提出了一个scroll滚动的方式。
scroll 类似于sql中的cursor,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景。
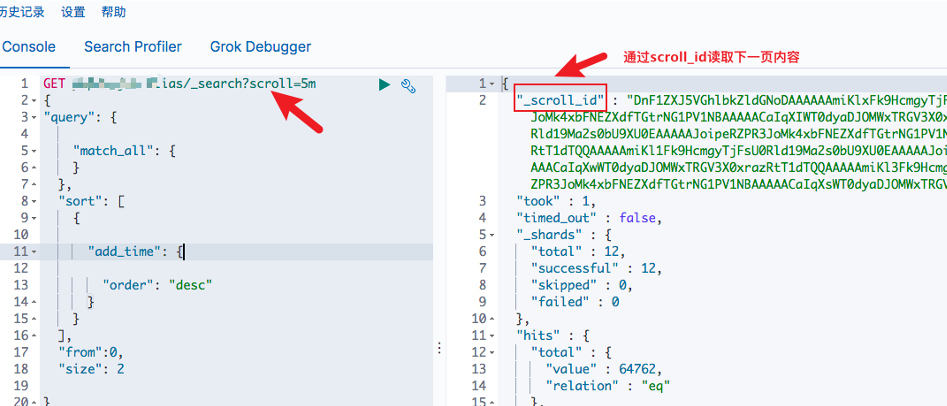
2.1 参数说明:
- scroll=5m表示设置scroll_id保留5分钟可用。
- size决定后面每次调用_search搜索返回的数量
2.2 scroll删除
根据官方文档的说法,scroll的搜索上下文会在scroll的保留时间截止后自动清除,但是我们知道scroll是非常消耗资源的,所以一个建议就是当不需要了scroll数据的时候,尽可能快的把scroll_id显式删除掉。
1)清除指定的scroll_id:
DELETE _search/scroll/DnF1ZX...
2)清除所有的scroll:
DELETE _search/scroll/_all
然后我们可以通过数据返回的_scroll_id读取下一页内容,每次请求将会读取下10条数据,直到数据读取完毕或者scroll_id保留时间截止。
说明:scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个 scroll_id 不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
3、方式三:search_after 深分页
search_after是ES5.0 及之后版本提供的新特性,search_after有点类似scroll,但是和scroll又不一样,它提供一个活动的游标,通过上一次查询最后一条数据来进行下一次查询。
比如第一次查询如下:
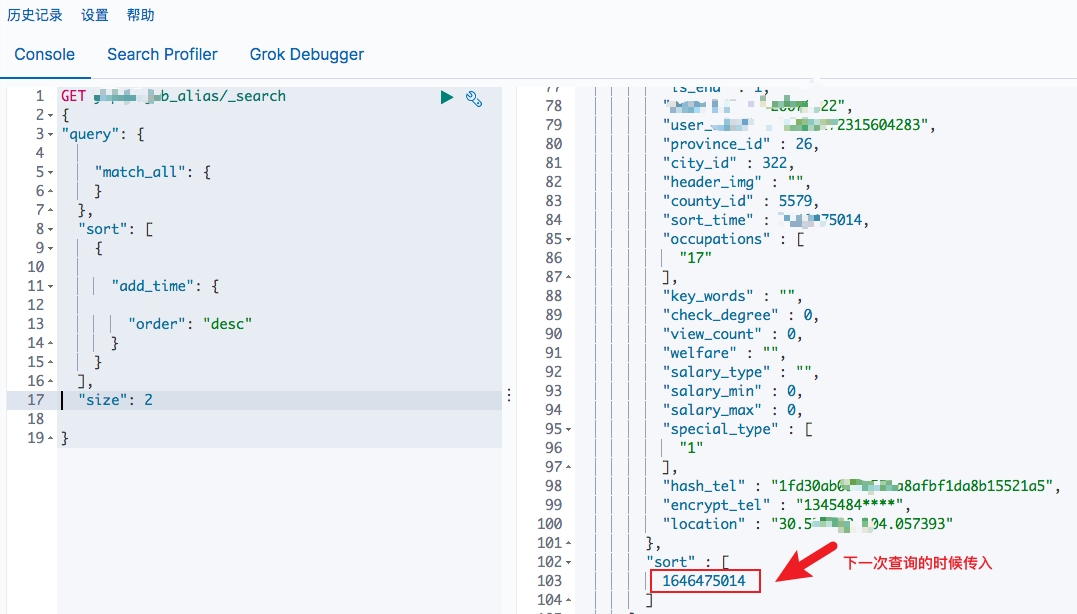
注意到返回结果中有一个sort字段,所以下一次查询的时候,只需要将本次查询最后一条数据中的排序字段加入查询即可:
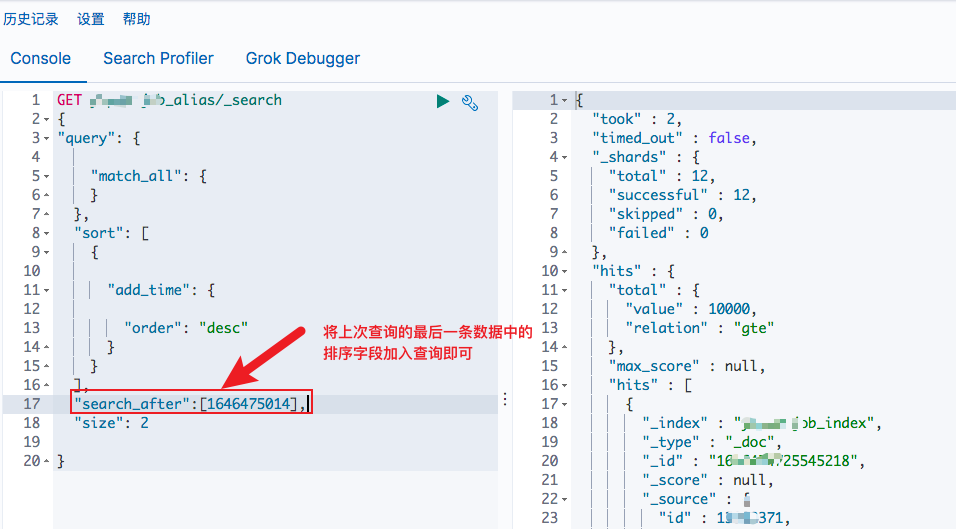
实现原理:
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
说明:
- 为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
- 说明:使用search_after查询需要将from设置为0或-1,当然也可以不写。
需要注意的是:
1)sort字段的选择
如果search_after中的关键字为***,那么***123的文档也会被搜索到,所以在选择search_after的排序字段时需要谨慎,可以使用比如文档的id或者时间戳等。另外,search_after并不是随机的查询某一页数据,而是并行的滚屏查询;search_after的查询顺序会在更新和删除时发生变化,也就是说支持实时的数据查询。
2)无法跳页请求
因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
4、方式四: 由前端传入上次查询的最小ID
由于业务需要,我这边实现的分页列表由前端配合一起完成,这样也解决了跳页的问题,供参考:

1 <?php
2
3 class Test
4 {
5
6 public function queryBaiduJobList(array $fileds, int $minId, int $limit)
7 {
8 // 为了解决es查询默认1w条的上限,由前端传入上一次查询返回列表中最小id:minId
9 $query = JobParams::build()
10 ->term('is_check', 1)
11 ->select($fileds)
12 ->trackHits(true)
13 ->sort('id')
14 ->limit($limit);
15
16 if ($minId) {
17 $query = $query->range('id', ['<', $minId]);
18 }
19
20 return $this->all($query);
21 }
22 }
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)