
数据分析系统的设计与实现
基于Dynamic Web + JSP + Hive +Mysql + Spark 实现的双十一购物数据可视化分析,使用Echarts可视化,spark 的 SVM进行回头客预测
数据分析系统的设计与实现
大数据demo,参考自淘宝双11数据分析与预测课程案例 厦大数据库实验室博客 (xmu.edu.cn)
实验环境
- 操作系统 Linux (实验室版本为 Ubuntu1 8 .04 ,集群环境为 centos6.5
- Hadoop 版本: 2.9.0
- JDK 版本: 1.8
- Java IDE Eclipse 3.8
- Spark 版本: 2.3.0
- Mysql 8.0.29
- Tomcat 8.5
- Echarts 3.4.0
- Hive 3.1.2
- Sqoop 1.4.6
实验介绍
基于Dynamic Web + JSP + Hive +Mysql + Spark 实现的双十一购物数据可视化分析,使用Echarts可视化,spark 的 SVM进行回头客预测
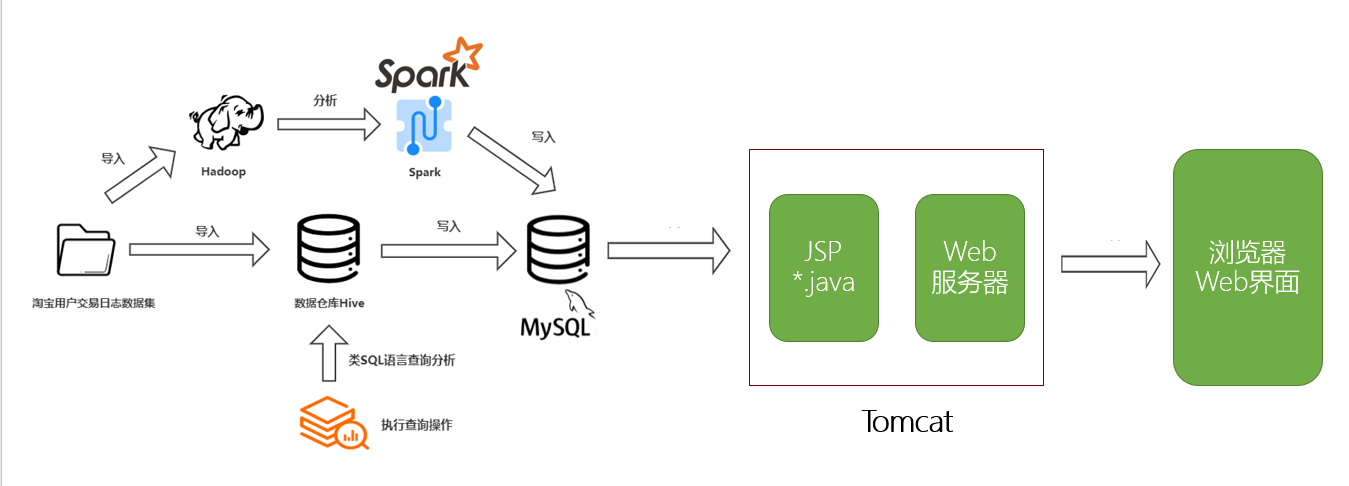
实验框架
数据集描述
三个数据集分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv
用户行为日志user_log.csv,日志中的字段定义如下:
- user_id | 买家id
- item_id | 商品id
- cat_id | 商品类别id
- merchant_id | 卖家id
- brand_id | 品牌id
- month | 交易时间:月
- day | 交易事件:日
- action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
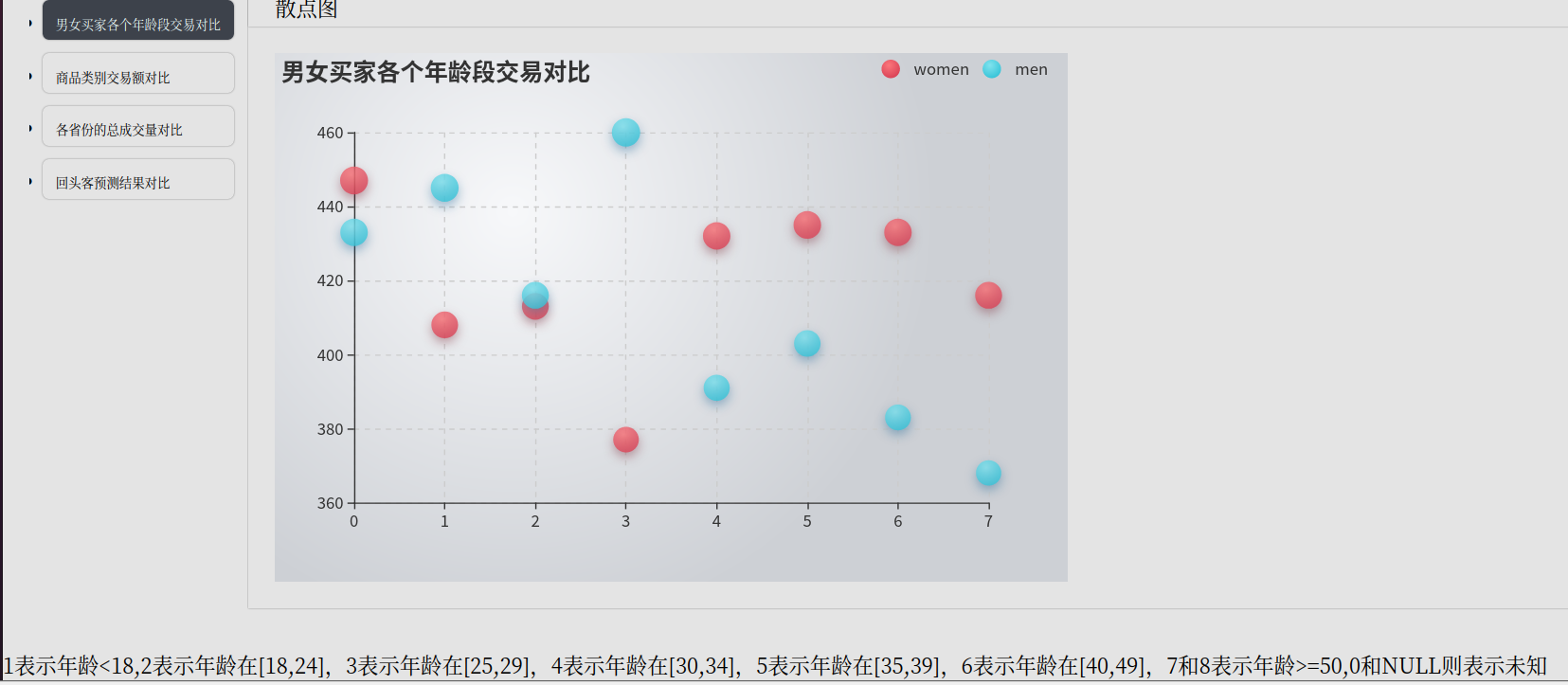
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- province| 收获地址省份
回头客数据集
- user_id | 买家id
- age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
- gender | 性别:0表示女性,1表示男性,2和NULL表示未知
- merchant_id | 商家id
- label | 是否是回头客,0值表示不是回头客,1值表示回头客,-1值表示该用户已经超出我们所需要考虑的预测范围。NULL值只存在测试集,在测试集中表示需要预测的值。
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
# 上传
./bin/hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log
在Hive上创建数据库
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
hive> create database dbtaobao;
hive> use dbtaobao;
创建Hive外部表,
hive> CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';
Hive 上进行数据分析
例如
hive> select brand_id from user_log limit 10; -- 查看日志前10个交易日志的商品品牌
Hive 可以使用类sql语句进行增删查改,对应的会自动转成mapreduce操作
从Hive导入数据到MySQL
使用Sqoop将数据从Hive导入MySQL
首先在mysql里面创建数据库
mysql> show databases; #显示所有数据库
mysql> create database dbtaobao; #创建dbtaobao数据库
mysql> use dbtaobao; #使用数据库
创建表
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
导入数据
cd /usr/local/sqoop
bin/sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password root --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
Spark SVM
利用Spark的SVM预测回头客
-
读取数据,从Hadoop
val train_data = sc.textFile("/dbtaobao/dataset/train_after.csv") val test_data = sc.textFile("/dbtaobao/dataset/test_after.csv") -
构建训练模型
// 属性1 2 3 4 作为输入变量 val train= train_data.map{line => val parts = line.split(',') LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts (2).toDouble,parts(3).toDouble)) } val test = test_data.map{line => val parts = line.split(',') LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts(2).toDouble,parts(3).toDouble)) } // 设置迭代次数,构建SVMWithSGD模型 val numIterations = 1000 val model = SVMWithSGD.train(train, numIterations) -
评估模型,设置阈值并且输出得分和分类结果
// 设置阈值 输出 model.setThreshold(0.0) val scoreAndLabels = test.map{point => val score = model.predict(point.features) score+" "+point.label } scoreAndLabels.foreach(println) -
上传到mysql
Web可视化
Tomcat+mysql+JSP 进行开发,使用Dynamic Web Project
思路
Java后端从数据库中查询数据 然后前端获取服务端的数据,JSP页面最后使用ECharts和查询的数据来展现可视化,并且代理到Web 8080端口显示界面
效果
所有卖家各消费行为对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yMcTfMSH-1654792113133)(https://vvtorres.oss-cn-beijing.aliyuncs.com/image-20220610000233762.png)]
男女买家交易对比
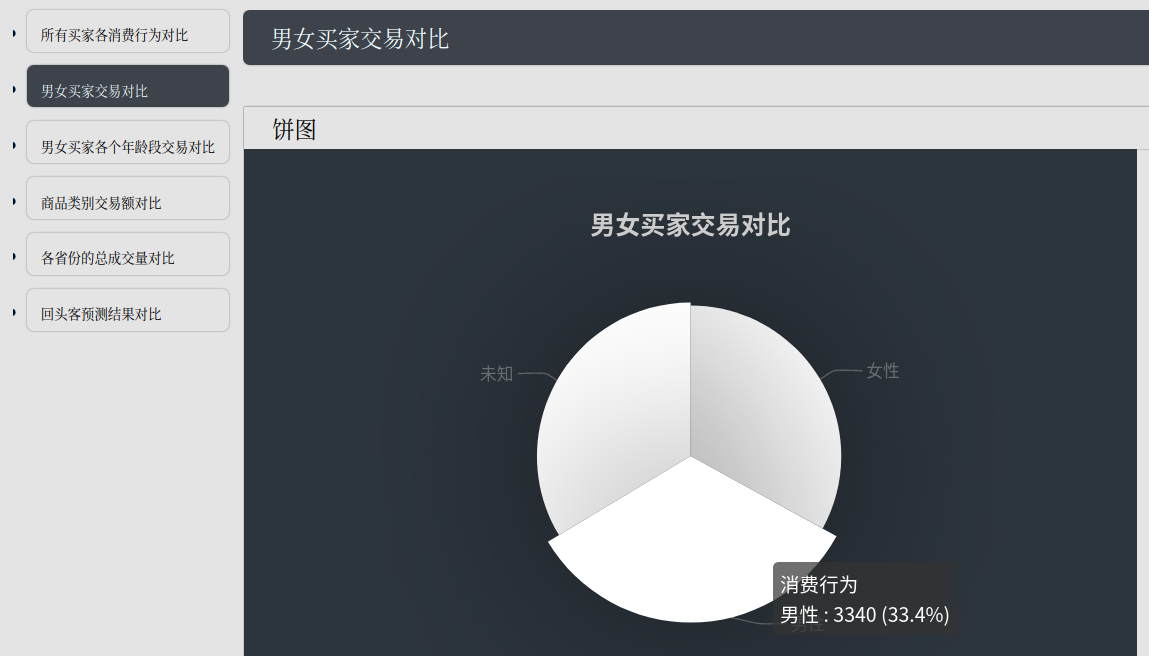
年龄段交易对比
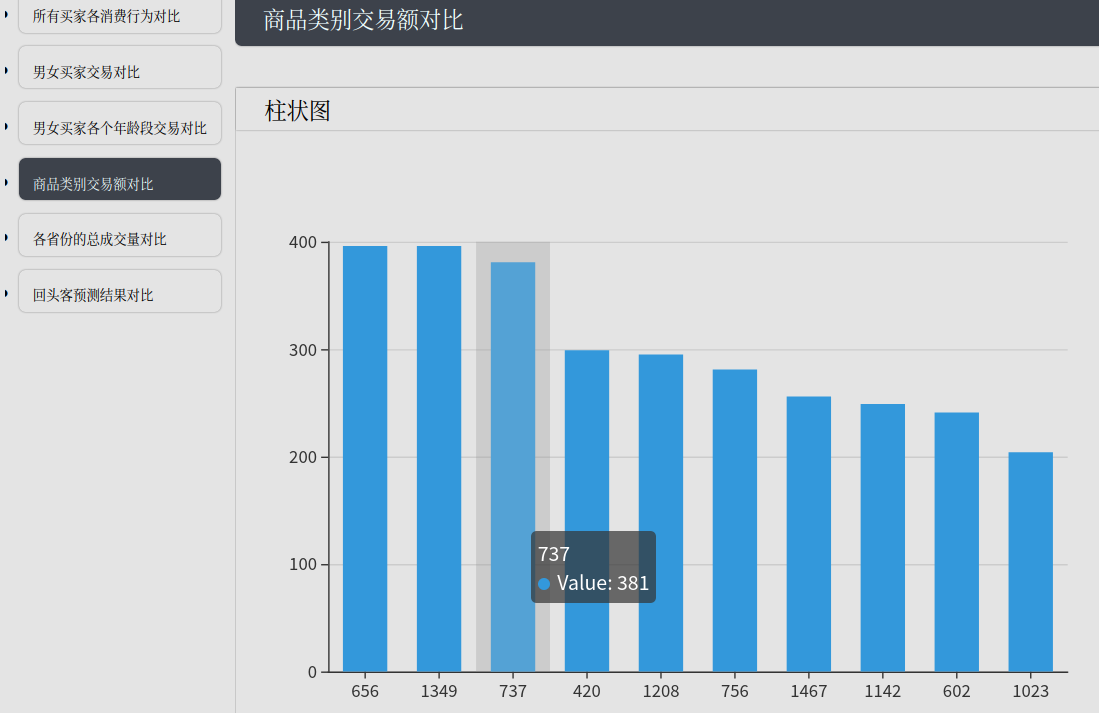
商品类别交易额对比
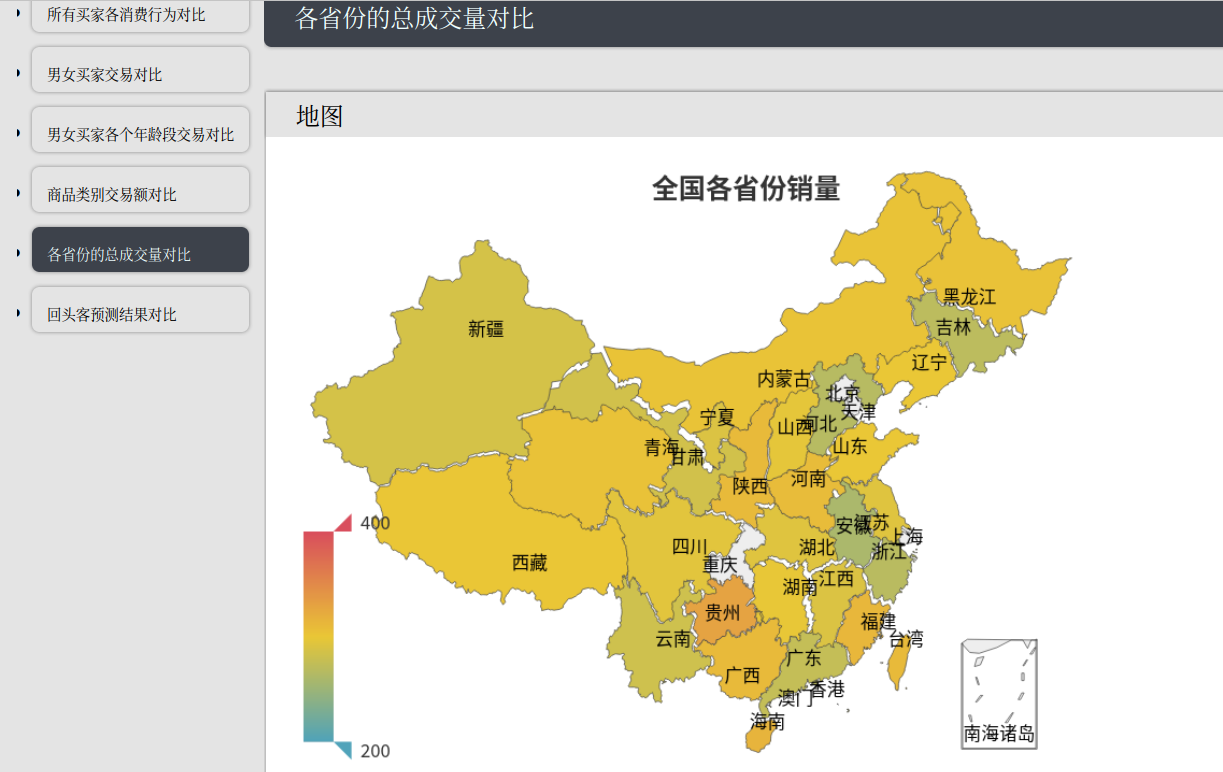
各个省份成交量对比
SVM回头客预测对比
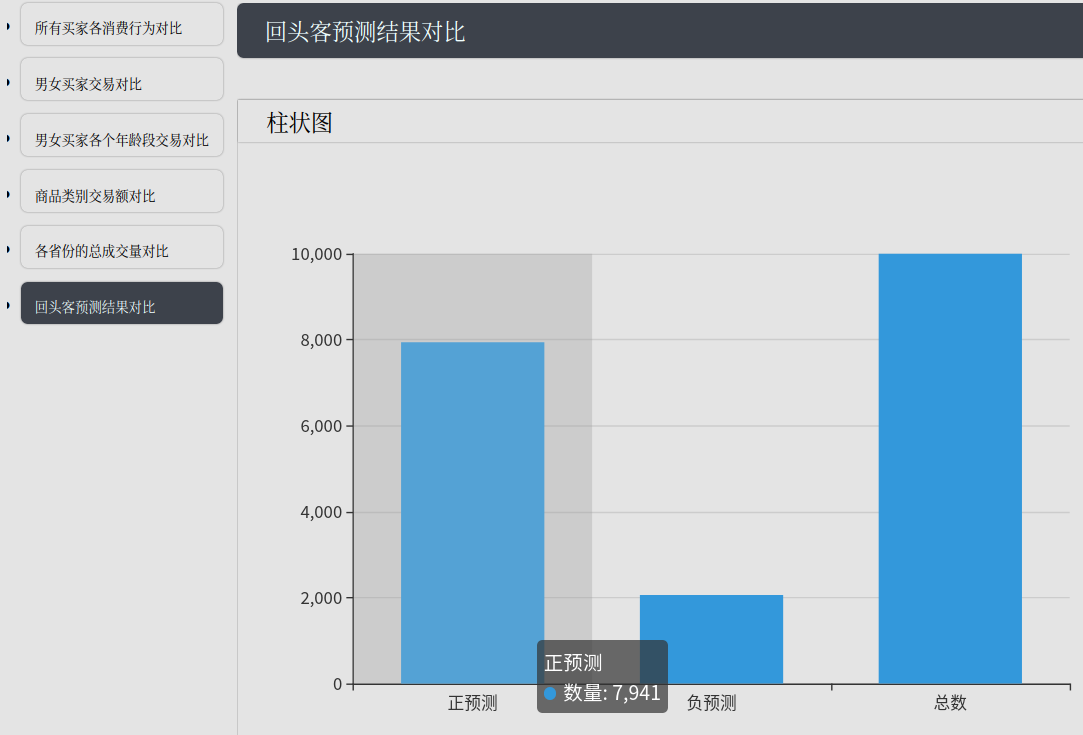
结论分析
-
熟悉了Hive,Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。十分适合对数据仓库进行统计分析!
-
熟悉了Java Web(Dynamic Web Project)开发,使用eclipse IDE,Tomcat作为Web容器, java编写后端,JSP编写用户界面,Echarts来进行可视化图表,即可实现数据分析系统
-
熟悉了 SVM算法,以及Spark的ML库里面的SVM的使用 , 支持向量机SVM是一种二分类模型。在机器学习里面已经学习过了。而在Spark的Machine Learning库里面已经封装好了SVM,里面的SVM只支持最基础的二分类,可以设置迭代次数正则化等参数,如果设置了阈值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测,可以通过AUC来评估。
自拟问题
关于Hive的外部表和内部表
Hive在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的
删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建内部表,否则使用外部表!
Hive导入MySQL数据库失败
因为是编码问题,把Mysql编码全部改成utf-8 即可正常导入。
外部表中的数据并不是由它自己来管理的
删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建内部表,否则使用外部表!
Hive导入MySQL数据库失败
因为是编码问题,把Mysql编码全部改成utf-8 即可正常导入。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)