
MySQL表分区
主要介绍mysql几种表分区的基本使用,包括range分区、list分区、hash分区、key分区、子分区和columns分区。
学到这儿,边学边测,简要记录一下,以下代码都在mysql8.0下实测过。
关于分区以及为什么要分区
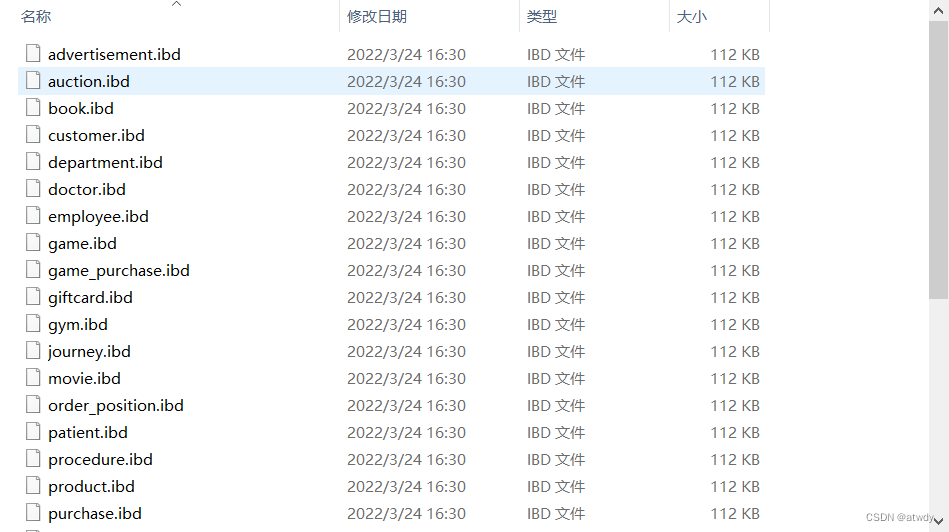
我们首先找到mysql的数据存储目录,可以通过语句show variables like '%datadir%';查看,我本机的是"C:\ProgramData\MySQL\MySQL Server 8.0\Data",在该目录下,可以看到每个数据库对应着一个文件夹,对于没有分区的表,库中的每个表就对应着文件夹下的一个ibd文件
当一个表中的数据量太大时,会面临两个问题,一是对数据的操作会变慢,比如select、join、update、delete时,会对全表操作;二是不便于存储,可能会出现剩余磁盘空间存储不下这张表的情况。而分区就可以在一定程度上解决这两个问题。
简要的说,分区就是将表物理截断,但在逻辑上依然是一个整体,开发人员在数据操作时仍然是对这个整体大表进行操作,之后由数据库底层自己去寻找对应的分区进行操作,数据库底层寻找分区这个过程对开发人员来说是透明的,这样在数据操作时可以只对特定分区操作以提高效率,存储时也可以将不同分区的物理文件分开存放,下面是一个有3个分区(p1、p2、p3)的表(p_table)的实际存储

注:当过滤条件为分区的字段时才会自动寻找分区,否则还是全表扫描
水平分区的几种类型及demo
之所以特别说明一下是水平分区,是因为还有一种垂直分区的分区方式,二者一个横向切割一个纵向切割,(对比之下感觉水平分区类似于HBase中的segment,垂直分区类似于HBase中的region~),关于垂直分区先跳过,一是没找到多少相关的资料,二是感觉业务中用到的也不多,大多用的都是水平分区,有时间日后再补。
mysql中的水平分区包含下面几种:
1.range分区
range分区,顾名思义,就是按照范围进行分区,下面是创建一个range分区表:
drop table if exists `range_table`;
create table `range_table`(
`id` int,
`name` varchar(10)
)
partition by range(id)(
partition p1 values less than (10),
partition p2 values less than (20),
partition p3 values less than maxvalue
);
上面以id为分区字段,根据id大小划分为[-∞, 10),[10, 20),[20, +∞]三个区间,注意包前不包后,在数据插入时会自动根据id插入到各自分区
# 插入数据
insert into range_table (id, name) values (1,"梁静茹"),(10,"金泰妍"),(15,"王菲"),(50,"邵夷贝");
# 查看各个分区数据条数
select partition_name,table_rows from information_schema.partitions where table_name = 'range_table';
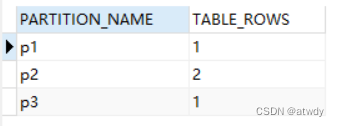
分别指定分区查看各个分区里面的数据,可以看到id为1的保存到了p1,id为10和15的保存到了p2,id为50的保存到了p3
select * from range_table partition (p1);
select * from range_table partition (p2);
select * from range_table partition (p3);
在进行select/update/delete时如果where后面的限制条件包含分区字段id时会自动去对应分区中查找,否则还是全表扫描。
explain select * from range_table where id = "1" and name = '梁静茹';

explain select * from range_table where name = '梁静茹';

range分区字段只支持整型,如果需要对时间日期这样的字段进行range分区,可以通过相关函数将类型转为整型再分区。
2.list分区
list就是枚举的意思,list分区就是在创建各分区时具体指定哪些值属于这些分区,下面是创建list分区表的代码:
drop table if exists `list_table`;
create table `list_table`(
`id` int,
`name` varchar(10)
)
partition by list(id)(
partition p1 values in (1),
partition p2 values in (10,15,50)
);
重新执行插入语句insert into list_table (id, name) values (1,"梁静茹"),(10,"金泰妍"),(15,"王菲"),(50,"邵夷贝");,id为1的保存到了p1分区,id为10,15,20的保存到了p2分区,需要注意如果插入数据的 id 在各个分区所对应着的列表里面都没找到,则会报错。
list分区分区字段同样只能是int型。
3.hash分区
hash分区分为常规hash和线性hash,常规hash是在分区字段上基于分区个数的取模运算,根据余数分区。线性hash是对分区字段进行二次方运算,根据运算结果分区,所以hash分区同样要求分区字段为整型或者是可以返回整型结果的表达式。二者在建表时候的区别只是线性hash比常规hash多了个linear(线性的)限定。
3.1.常规hash
常规hash分区建表:
drop table if exists `hash_table`;
create table `hash_table`(
`id` int,
`name` varchar(10)
)
partition by hash(id)
partitions 3;
hash分区不能指定分区名,会默认创建名为pn的分区,n从0开始自增。上面这段代码会创建p0,p1,p2三个分区,分区名可以通过下面的sql查看,
select partition_name from information_schema.PARTITIONS where table_schema = schema() and table_name = "hash_table";

上面说的常规hash就是基于分区数对分区字段进行取模求余操作,按照这种计算,插入下面的数据,
insert into hash_table (id, name) values (1,"梁静茹"),(10,"金泰妍"),(15,"王菲"),(50,"邵夷贝");
1 10 15 50 分别对3求余对应的结果 1 1 0 2,也就是上面4条数据应该分别被保存到p1, p1, p0, p2分区,对此进行验证:
select 'p0' as part, t.* from hash_table partition (p0) t
union
select 'p1' as part, t.* from hash_table partition (p1) t
union
select 'p2' as part, t.* from hash_table partition (p2) t;
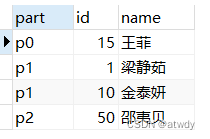
这样当在查询的时候会采用相同的取模运算到对应分区下查找,比如查id为5的数据,就会去p2分区查找。
3.2.线性hash
线性hash在建表时只是比常规hash多了个linear字段:
drop table if exists `hash_linear_table`;
create table `hash_linear_table`(
`id` int,
`name` varchar(10)
)
partition by linear hash(id)
partitions 3;
关于线性分区的具体计算规则可以参考官方文档:https://dev.mysql.com/doc/refman/8.0/en/partitioning-linear-hash.html,这里假设num是分区个数,value是某条记录的分区字段对应的值,N是最终经过计算得到的某个分区编号,则N的计算过程如下:
step1:V = power(2, ceil(log(2, num)))
step2:N = value & (V-1)
step3:if N>=num: N=N & (ceil(V/2) - 1)
按照上面步骤,将id为50的这条数据代入计算:
step1:V = power(2, ceil(log(2, num))) = power(2, ceil(log(2, 3))) = power(2, 2) = 4
step2:N = value & (V-1) = 50 & 3 = 110010 & 000011 = 000010 = 2
step3:N>=num? <=> 2>=3? False:N=2
即id为50的这条数据保存到p2分区,同理可以计算出id为10时N=2,id为1时N=1,id为15是N=1,验证一下计算结果:
select 'p0' as part, t.* from hash_linear_table partition (p0) t
union
select 'p1' as part, t.* from hash_linear_table partition (p1) t
union
select 'p2' as part, t.* from hash_linear_table partition (p2) t;
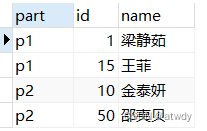
结果计算正确。
4.key分区
主要还是参考官方文档吧,https://dev.mysql.com/doc/refman/8.0/en/partitioning-key.html,里面主要说的是,key分区类似于hash分区,只不过分区列不再强制为整型,可以为除text和BLOB两种类型外的其它类型。key分区也有两种,常规key和线性key,常规key对分区字段采用的是MD5算法,线性key对分区字段采用的是二次方算法,参考hash分区中的线性hash,分区列选取的具体规则为:
- 当表中只有主键primary key或只有唯一键unique key时,分区列必须包含主键或唯一键中的部分或全部字段,不允许出现主键或唯一键中字段以外的其它字段
- 当表中主键和唯一键同时存在时,分区列为主键和唯一键公共字段的部分或全部
- 当表中主键唯一键都没有时:任意指定除text和BLOB类型外的其它字段,可以为1个或多个
分区列也可以缺省不指定,但必须要求表中存在主键或唯一键,优先以主键作为分区字段,没有主键时以唯一键作为分区字段,此时唯一键必须显式指定not null。
下面是常规key分区建表的一个demo,name为分区字段:
drop table if exists `key_table`;
create table `key_table`(
`id` int,
`name` varchar(10) not null,
unique `uk_name` (name)
)
partition by key()
partitions 3;
线性key分区的建表也只是多了一个linear字段:
drop table if exists `key_table`;
create table `key_table`(
`id` int,
`name` varchar(10) not null,
unique `uk_name` (name)
)
partition by linear key()
partitions 3;
5.子分区(复合分区)
文档地址:https://dev.mysql.com/doc/refman/8.0/en/partitioning-subpartitions.html,里面有这么一段话,
说的是我们可以对采用range分区或者list分区的表,进行二次分区,二次分区只能为hash分区或者key分区。这种分区方式有两种建表写法,一种是指定子分区名,一种是不指定子分区名由系统默认。
不指定子分区名创建:
drop table if exists `subpart_table`;
create table `subpart_table`(
dt date
)
partition by range(year(dt))
subpartition by hash(month(dt))
subpartitions 2 (
partition p1 values less than (1990),
partition p2 values less than (2000),
partition p3 values less than maxvalue
);
通过select partition_name, subpartition_name from information_schema.partitions where table_schema = schema() and table_name = 'subpart_table';查看下各个子分区:
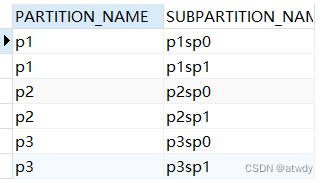
物理上也被分成了单独的6个文件:
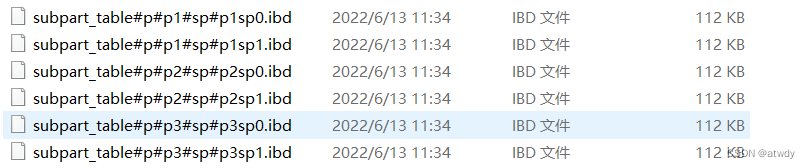
指定分区名创建,这种方式要求每个一级分区下的子分区数量必须一致,所有子分区的分区名不能重复:
drop table if exists `subpart_table`;
create table `subpart_table`(
dt date
)
partition by range(year(dt))
subpartition by hash(month(dt))
(
partition p1 values less than (1990)(
subpartition s1,
subpartition s2
),
partition p2 values less than (2000)(
subpartition s3,
subpartition s4
),
partition p3 values less than maxvalue(
subpartition s5,
subpartition s6
)
);
上表根据日期的年份进行一级分区,根据日期的月份二级分区,s1、s3、s5存偶数月,s2、s4、s6存奇数月,插入数据验证一下:
insert into subpart_table values('1989-01-01'), ('1989-02-01'),
('1995-01-01'), ('1989-02-01'),
('2022-01-01'), ('2022-02-01');
select 's1' as part, t.* from subpart_table partition (s1) t
union
select 's2' as part, t.* from subpart_table partition (s2) t
union
select 's3' as part, t.* from subpart_table partition (s3) t
union
select 's4' as part, t.* from subpart_table partition (s4) t
union
select 's5' as part, t.* from subpart_table partition (s5) t
union
select 's6' as part, t.* from subpart_table partition (s6) t;
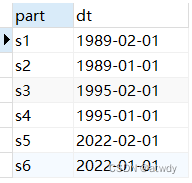
6.columns分区
包含range columns和list columns两种,分区字段可以不为整型,可以有多个,感觉用得不多,附上文档地址,用到的时候再来学习吧,https://dev.mysql.com/doc/refman/8.0/en/partitioning-columns.html

无需安装部署,在线快速体验 Byzer
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)