人工智能第3章 通过搜索进行问题求解
第3章 通过搜索进行问题求解
第3章 通过搜索进行问题求解
搜索:在确定性的、可观察的、静态的和完全可知的环境下,Agent构造行动序列以达到目标的过程称为搜索。
问题求解Agent
问题形式化:
-
初始状态: In(Arad)
-
行动:ACTIONS(s),即,给定一个状态s,ACTIONS(s)返回状态s下可以执行的动作的集合。例如状态s为 *In(Arad),动作集合( { Go(Sibiu) , Go(Timisoara) , Go(Zerind)} )
-
转移模型:RESULT(s,a),在状态s下,执行a动作后,达到的状态。也会使用后继状态表示从一给定状态出发,通过单步行动,可以达到的状态集合。
-
目标测试:确定给定的状态是不是目标状态。
目标状态有时是一个显式可枚举的目标状态集合,而有时是具备某些特定抽象属性的状态。 -
路径耗散:路径耗散函数为每条路径赋一个耗散值,即,边加权,罗马尼亚案例中,路径耗散可以是用公里数表示的路径长度。采用行动a从状态s走到状态s’所需要的单步耗散用c(s, a, s’)。
问题的解,是从初始状态到目标状态的一组行动序列。
解的质量,由路径耗散函数衡量,路径耗散值最小的即为最优解。
初始状态、行动和转移模型定义了问题的状态空间,即,从初始状态可以达到的所有状态的集合。
罗马尼亚地图就可以解释为一个状态空间图,结点表示状态,结点之间的弧表示行动。状态空间中的一条路径指的是通过行动连接起来的一个状态序列。
罗马尼亚案例的PEAS
见第二章的环境任务的描述(这是第二章的内容)
(Performance性能 ,Environment环境,Actuators执行器,Sensors传感器)
-
可观察的:Agent总是知道当前状态,Agent在罗马尼亚开车,每到达一个城市通过观察访问标识,知道是否访问过该城市。
-
离散的:在任一给定状态,可选的行动是有限的,在罗马尼亚游玩时,每个城市只与有限个数城市相邻。
-
已知的:Agent知道每个行动达到的状态(地图显示)
-
确定的:每个行动的结果唯一可确定。
-
完整状态形式化
状态:八个皇后的任一摆放都是一个状态。
初始状态:8个皇后都在棋盘上。
行动:选择一个皇后移动。
转移模型: 将移动后的棋盘返回。
目标测试:八个皇后都在棋盘上,并且无法互相攻击。无论哪种情况,都不需要考虑路径消耗,只需考虑最终状态。
通过搜索求解
frontier:已生成未拓展
closed:已拓展
-
一个解是一个行动,搜索算法考虑各种可能的行动序列
STATE:空间中的状态。
PARENT:产生该节点的父节点
ACTION:父节点产生该节点的行动
PATH-COST:代价(路径耗散) -
问题求解算法的性能
完备性:是否保证能找到解
最优性:是否能找到最优解
时间复杂度:找到解需要多少时间
空间复杂度:搜索中需要多少内存
树搜索
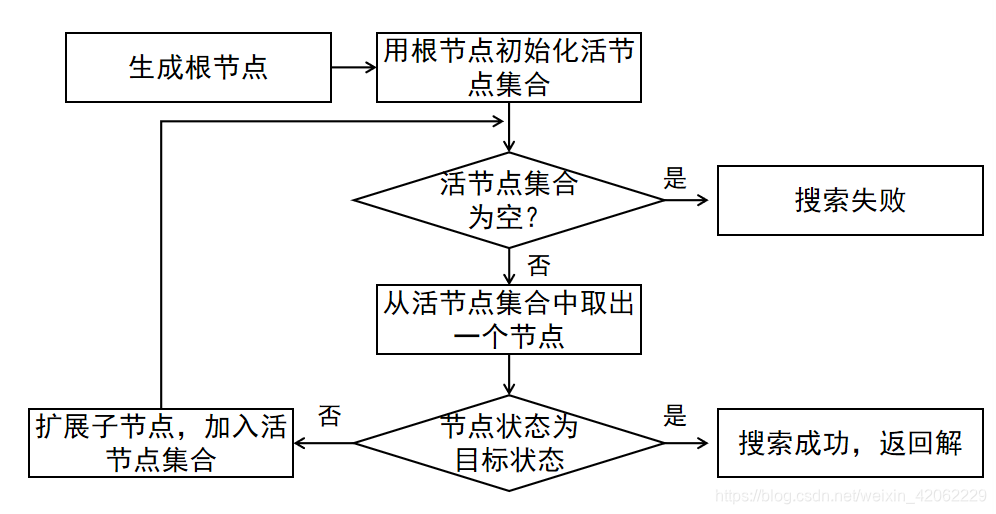
图搜索
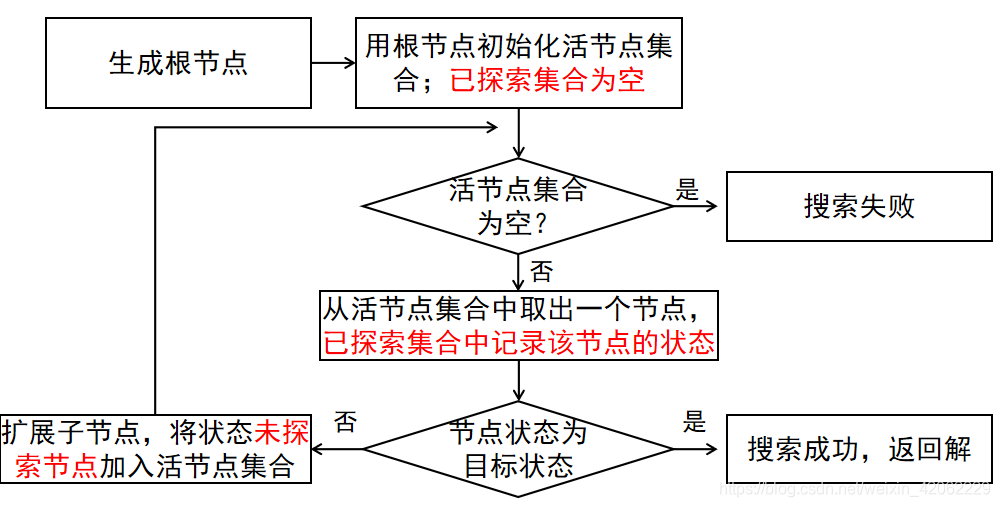
树搜索:重复状态增大时间开销,甚至导致死循环
图搜索:避免重复状态,空间开销大
无信息搜索策略
宽度优先搜索 (BFS)
- 基于节点深度的非递减函数,宽搜最优
- 扩展的是未扩展节点中深度最浅的节点
- 目标检测应用于被选择拓展时
- 时间复杂度:O(bd+1)
b = 一个非叶节点的子节点数
d = 层数
一致代价搜索 (Uniform-cost Search)
- 每一步的行动代价都相等时,UCS是最优的。
- 扩展的是路径消耗g(n)最小的结点。
- 目标检测应用于被选择拓展时,即在从frontier移除之后,否则最优性不能满足;
- 如果边缘中的节点有更好的路径到达该节点,则会引入一个测试。
- 不关心步数,只关心路径总代价。
- 当单步代价相同时,等价于宽度优先搜索
- 当单步代价为正时,算法是最优的
- 树搜索时当单步代价>0时完备,否则会死循环;图搜索(因为不会重复访问)总是完备的;
深度优先搜索(DFS)
- 扩展的是可扩展节点中深度最深的节点
- 目标检测应用于被选择拓展时,在加入frontier之前进行目标测试;
- 在有限状态空间的图搜索中,DFS是完备的,因为它可以把所有空间遍历一遍;
- 而在树搜索或无限搜索空间中,DFS则有可能会进入深度无限的分支,因此是不完备的。
- DFS的时间复杂度为为O(bm),而空间复杂度仅为O(bm)
因为我们只需要保存当前分支的状态,因此空间复杂度远远好于BFS。然而DFS并不能保证找到最优解。
深度受限搜索(Depth-limited Search)
深度受限搜索设定一个最大深度dmax,当搜索深度大于dmax的时候立即回溯,从而避免了在无穷状态空间中陷入深度无限的分支。
迭代加深的深度优先搜索(Iterative Deepening Search)
迭代加深的深度有限搜索也设定一个最大深度dmax,开始我们把dmax设为1,然后进行深度受限搜索,如果么有找到答案,则让dmax加一,并再次进行深度有限搜索,以此类推直到找到目标。这样既可以避免陷入深度无限的分支,同时还可以找到深度最浅的目标解,从而在每一步代价一致的时候找到最优解,再加上其优越的空间复杂度,因此常常作为首选的无信息搜索策略。
双向搜索(Bidirectional Search)
分别从源头和目标搜索。
对比
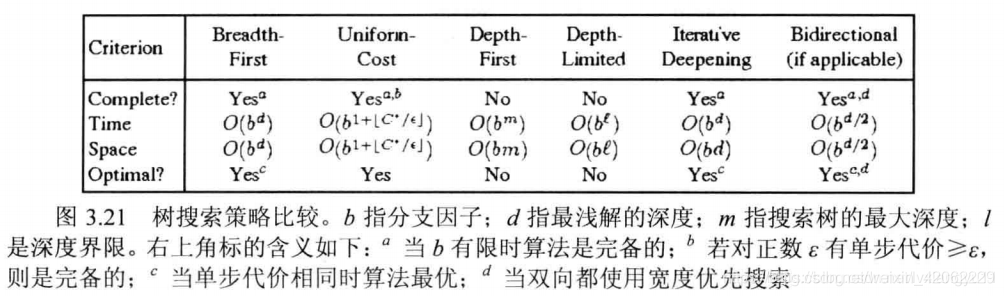
BFS 每次展开深度值最小的点;在加入frontier之前进行目标测试,这样可以少搜索一层;当分支因子有限时是完备的;当单步代价相同时最优。
UCS 每次展开路径代价最小的点;在从frontier移除之后,否则最优性不能满足;树搜索时当单步代价>0时完备,否则会死循环;图搜索(因为不会重复访问)总是完备的;具有最优性。
DFS 每次展开深度值最大的点;在加入frontier之前进行目标测试;树搜索或无限搜索空间时不完备,仅当有限空间的图搜索时是完备的;不具备最优性。
有信息(启发性)搜索
最佳优先搜索的评价函数f(N) 由启发函数(heuristic function)构成
h(N) = 结点n到目标结点的最小代价路径的代价估计值
设h*(N)为从N个节点到一个目标节点的最优路径的代价
可采纳:0 <= h(N) <= h*(N)
一个可采纳的启发式从不过高估达到目标的成本和难度,也就是说它是乐观的。
一致性:h(n)<=c(n,n’)+h(n’)
树搜索和图搜索是一致的
一致的启发式函数是可采纳的 h(n)<=c(n,n’)+h(n’) → h(n)<=h*(n)
贪婪最佳优先搜索(Greedy Best-first Search)
使用启发式,f(n) = h(n)
距离目标最近,最快找到解
GBFS,除了在有限分支的图搜索中有完备性,其余情况无完备性、不具最优性
A*算法
缩小总体评估代价
f(n) = g(n) + h(n)
最优性

具有完备性,除非有无穷多个具有f≤f(G)的节点。
比较:
GBFS优先扩展h最小的结点。不能确保完备性和最优性。
A搜索优先扩展g+h最小的结点,具有一致启发函数的A具有良好特性:完备性、最优性、不用访问重复状态。
启发式函数
同问题有多种启发函数
启发式精确度对性能的影响。考虑利用多个模式数据库构造比单个模式数据库更精确的可采纳的启发式。
有效分支因子b*,设总结点为N,解的深度为d,b为深度为d的标准搜索树为了能包括N+1个点所必须的分支因子。即,N+1 = 1 + b^1 + b^2 + … +b^d
例如,如果A算法用52个结点在第5层找到了解,那么有效分支因子就是1.92。
有效分支因子可能会因问题实例发生变化,但是在难题中通常它是相当稳定的。
随着解路径所在深度的增加,A算法扩展的结点数呈指数级增长,这导致了有效分支因子的存在。
所以,在一小部分问题集合上做实验以测量出 b的值,有益于探讨启发式的总体实用性。
设计良好的启发式会使 b*的值接近于1,以合理的计算代价对大规模的问题进行求解。
从松弛问题出发设计可采纳的启发式
减小了行动限制的问题称为松弛问题。松弛问题的状态空间图是原有状态空间的超图,因为减少限制导致图中边的增加。
松弛问题的最优解代价也是原问题的一致的启发式
松弛问题增加了状态空间的边。所以,一个松弛问题的最优解代价是原问题的可采纳的启发式。
松弛问题本质上要能够不用搜索就可以求解。
由于得出的启发式是松弛问题的确切代价,那么它一定遵守三角不等式,因而是一致的。
从子问题出发设计可采纳的启发式
子问题方法中,构建模式数据库可以避免重复计算。
存储每一个子问题代价的实例(模式数据库),作为启发式用。
多个子模式可取max。加法不能确保可采纳性。
多个不相交的子问题的代价之和是整个问题的下界(不相交的模式数据库)子问题的最优解代价是完整问题的解代价的下界。
如果子问题之间存在重复的动作,相加得到的启发式不是可采纳的。
从经验中学习启发式
每个最优解都可提供学 习h(n)的实例。每个实例都包括解路径上的一个状态和从这个状态到达解的代价。一个学习算法从实例构造h(n),预测搜索过程中所出现的其他状态的解代价。
如果在状态描述外还能刻画给定状态的特征,归纳学习方法则是最可行的。
例如,特征“不在位的棋子数” x1(n), “现在相邻但在目标状态中不相邻的棋子对数” x2(n) ,用线性组合构造h(n) :
◼ h(n) = c1 x1(n) + c2 x2(n)。
◼ c1和c2是需要学习的常数
◼ 这个启发式满足目标状态h(n)=0,但不保证是可采纳性或一致性
课后习题
如题所示的状态空间图中,S为初始节点,G为目标节点。请回答以下问题:其中,构建搜索树时,节点按字母序进行扩展;对要求给出一条路径的问题,按“S-A-G”的形式给出答案。
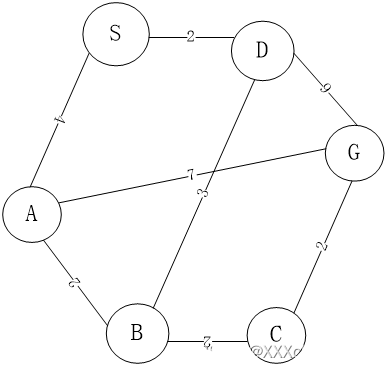
1)分别画出宽度优先搜索、深度优先搜索、一致代价搜索的搜索树及返回的路径。
宽度优先搜索:
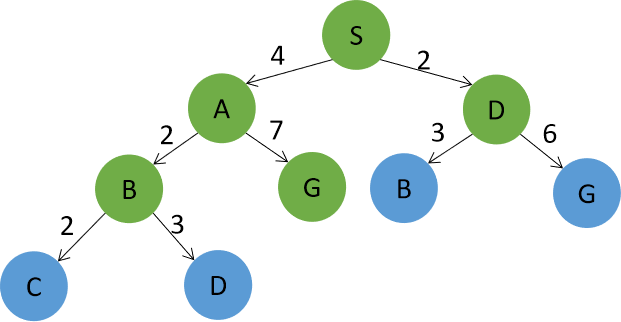
为了减少时间和空间开销,宽度优先搜索会在生成节点时进行目标检测,只需生成绿色节点,节点扩展顺序为S,A。返回路径为:S->A->G。路径损失为11。
深度优先搜索:
堆栈实现时,为了减少时间和空间开销,会在生成节点时进行目标检测。扩展节点为S,A。返回路径为S->A->G。路径损失为11。
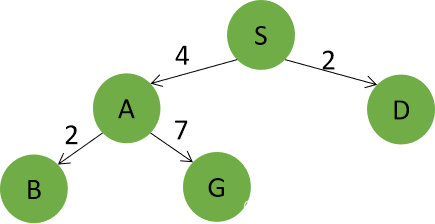
递归实现时,往往采用在扩展时进行目标检查的方法。扩展节点为S,A,B,C,G。返回路径为S->A->B->C->G。路径损失为10。
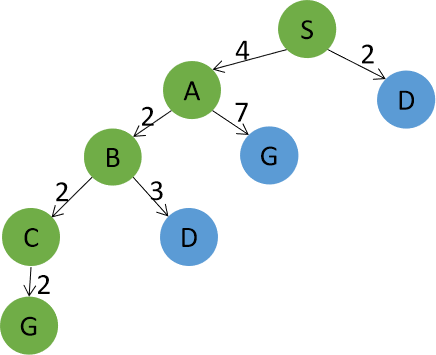
一致代价搜索:扩展节点为S,D,A,B,C,G。返回路径为S->D->G。路径损失为8
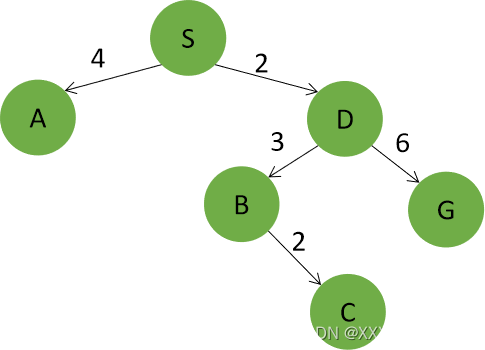
一致代价搜索在生成节点时会排除已探索节点,并与已生成节点进行比较,如果路径损失不低于已生成对应节点的路径损失,则不将该节点加入候选节点中。
因此A节点的两个后继节点B,G的代价不低于已生成的D节点的后继,故不会加入到候选列表中。
2)分别以H1和H2为启发式函数,给出贪婪最佳优先搜索的搜索树并在树中标出每个节点的评估函数值。给出所返回的路径,并回答:贪婪最佳优先搜索是否能够保证找到最优解,为什么?
贪婪最佳优先搜索算法不能确保最优解,它扩展的节点始终为到目标结点估计代价最小节点,没有考虑根节点到当前节点的路径代价。
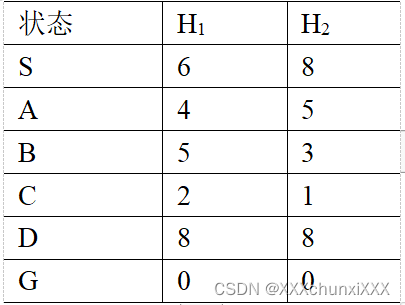
以h1为启发函数的搜索树为:节点扩展顺序为S,A,G。返回路径为:S->A->G。路径损失为11
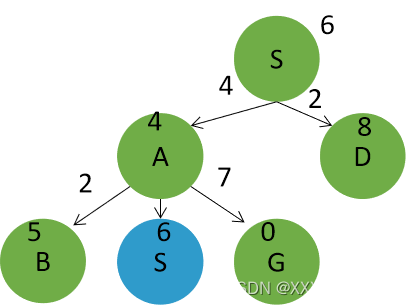
以h2为启发函数的搜索树为:搜索树如作图绿色部分所示。节点扩展顺序为S,A,G。返回路径为:S->A->G。路径损失为11
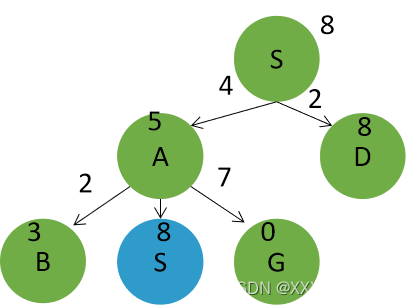
3)分别以H1和H2为启发式函数,给出A搜索的搜索树并在树中标出每个节点的评估函数值。给出所返回的路径,并回答:A搜索是否能够保证找到最优解,解释其原因。
以h1为启发函数的搜索树为:节点扩展顺序为S,A,D,G。返回路径为 S->D->G。路径损失为8。
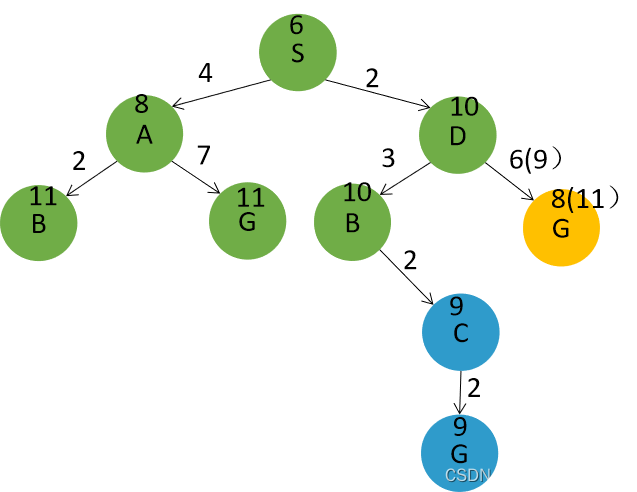
以h2为启发函数的搜索树为:节点扩展顺序为S,A,B,C,D,B,C,G。返回路径为 S->D->G。路径损失为8。
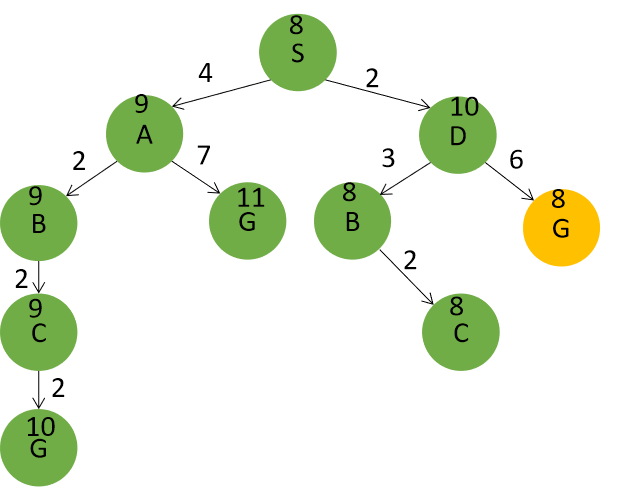
A*搜索是否能够保证找到最优解,解释其原因。
在启发函数满足可采纳性的条件下,A算法可以确保A树搜索结果的最优性。
可采纳性是指启发函数不会高估到达目标的代价。
在启发函数满足一致性的条件下,A算法可以确保A图搜索结果的最优性。
一致性是指,如果对于每个节点n和通过任意行动a生成的n的每个后继节点n’,从节点n到达目标的估计代价不大于从n到n’的单步代价与从n’到达目标的估计代价之和:h(n) <= c(n, a, n’) + h (n’)
可以证明,一致的启发式都是可采纳的。
需要注意的是,在启发函数不满足上述条件的情况下,A算法不能确保搜索结果是最优的*。
3.1
解释为什么问题的形式化要在目标的形式化之后。
答:在制定目标时,我们决定我们对世界的哪些方面感兴趣,哪些方面可以被忽视或抽象化。然后,在问题描述中,我们决定如何操纵重要的方面(而忽略其他方面)。如果我们先制定问题,我们就不知道应该包括什么,也不知道遗漏了什么。也就是说,在目标制定、问题制定和问题解决之间有一个循环,直到找到一个足够有用和有效的解决方案。
3.2
你的目标是将机器人从迷宫中导航出去。机器人从迷宫中心开始朝北。您可以将机器人转到面向北、东、南或西。您可以指示机器人向前移动一定距离,尽管它在撞到墙壁之前会停止。
a.制定此问题。状态空间有多大?
b、在迷宫中,我们唯一需要转弯的地方是两个或多个走廊的交叉点。使用此观察重新格式化此问题。现在状态空间有多大?
c.从迷宫中的每一点开始,我们可以沿着四个方向中的任何一个方向移动,直到到达一个转折点,这是我们唯一需要做的动作。使用这些操作重新设置问题。我们现在需要追踪机器人的方向吗?
d在我们对我们已经从现实世界中提取的问题的初始描述中,限制操作和删除细节,列出三个这样的简化。
答案A.
我们将定义坐标系,使得迷宫的中心位于(0,0),迷宫本身是(-1,-1)到(1,1)的正方形。
初始状态:机器人在坐标(0,0),面向北。
目标测试:|X|>1或|Y|>1,其中(x,y)为当前位置。
行动:向前移动任何距离D;将方向机器人改变方向。
成本函数:移动的总距离。由于机器人的位置是连续的,所以状态空间是无限大的。
答案B.
将记录机器人目前的交叉口的状态,以及它面临的方向。在每条走廊的尽头,离开迷宫,我们将有一个出口节点。我们假设某个节点对应于迷宫的中心。
初始状态:位于朝北迷宫中心。
目标测试:在出口节点。
行动:如果有一个交叉口,就移到前面的下一个十字路口;转向一个新的方向。
成本函数:总移动距离。有4N个状态,其中n是交叉口的数目。
答案C.
初始状态:在迷宫的中心。
目标测试:在退出节点处。
行动:移动到北、南、东或西的下一个交叉点。
成本函数:移动的总距离。
我们不再需要跟踪机器人的方位,因为它与预测我们的行动的结果无关,而且不是目标测试的一部分。执行该计划的电机系统需要跟踪机器人的当前取向,以知道何时旋转机器人。
答案D.
状态抽象:(i)忽略机器人离地面的高度,不管它是否从垂直方向倾斜。
(ii)机器人只能在四个方向上面对。
(iii)世界的其他部分被忽略:其他机器人在迷宫中的可能性,天气等。
动作抽象:(i)我们假设我们可以安全访问的所有位置:机器人无法卡住或损坏。
(ii)机器人可以无电源限制地移动。
(iii)简化的移动系统:向前移动一定距离,而不是控制每个单独的马达并观看传感器以检测碰撞。
3.3
两个朋友住在地图(如图 3.2 给出的罗马尼亚地图)上的不同城市中。每一轮次,两个人都可以前进到地图上相邻的城市。从城市 i到相邻城市j耗费的时间与城市间的距离d(i,i)相等,但是每一轮次先到达相邻城市的人要等另一人抵达他的相邻城市(到达后打手机),方可进入下一轮次。我们希望这两个朋友能尽快相遇。a.请详细形式化此问题(你会发现在这定义一些形式符号很有帮助)。
b.用D(i,j)表示城市i和j之间的直线距离。下列启发式函数哪些是可采纳的?
(i)D(i,j):
(ii)2D(i,j);
(ii)D(i,j)/2。
c.是否存在完全联通图却没有解?
d.是否存在这样的地图∶所有解都需要一个朋友访问同一城市两次?
a.
State space: States are all possible city pairs (i, j). The map is not the state space. Successor function: The successors of (i, j) are all pairs (x, y) such that Adjacent(x,i)and Adjacent(y, j).
Goal: Be at (i, i) for some i.
Step cost function: The cost to go from (i, j) to (x, y) is max(d(i, x), d(j, y)).
b.In the best case, the friends head straight for each other in steps of equal size, reducing their separation by twice the time cost on each step. Hence (iii) is admissible.
c.Yes: e.g., a map with two nodes connected by one link. The two friends will swap places forever. The same will happen on any chain if they start an odd number of steps apart. (One can see this best on the graph that represents the state space, which has two disjoint sets of nodes.) The same even holds for a grid of any size or shape, because every move changes the Manhattan distance between the two friends by 0 or 2.
d.Yes: take any of the unsolvable maps from part © and add a self-loop to any one of the nodes. If the friends start an odd number of steps apart, a move in which one of the friends takes the self-loop changes the distance by 1, rendering the problem solvable. If the self-loop is not taken, the argument from © applies and no solution is possible.
3.6
有三个水壶,容量分别为12加仑,8加仑,3加仑,还有一个放液嘴。可以吧水壶装满或倒空,从一个壶倒进另一个壶或倒在地上。请量出刚好1加仑水。
状态:(V(a),V(b),V©);V(a),V(b),V©是各壶中水的体积;V(a)⋲Z,0<=V(a)<=12;V(b)⋲Z,0<=V(b)<=8;V©⋲Z,0<=V©<=3;
初始状态:V(a)=V(b)=V©=0
行动:这个任务环境中,每个状态可执行的行动共有12种。分别为:将a中的水倒入b中;将a中的水倒入c中;a中的水倒在地上;将a装满;将b中的水倒入a中;将b中的水倒入c中;b中的水倒在地上;将b装满;将c中的水倒入a中;将c中的水倒入b中;将c中的水倒在地上;将c装满。
转移模型:(V’(a),V’(b),V’©) = result(V(a),V(b),V©,action)
其中V(a),V(b),V©是执行动作前各壶中水的体积,action为执行的动作,V’(a), V’(b), V’©是执行动作后各壶中水的体积。
对于不同action,result函数计算公式如下:
1.将a中的水倒入b中。V’(a)=V(a)-min(8-V(b),V(a));V’(b)=V(b)+min(8-V(b),V(a));V’©=V©
2.将a中的水倒入c中。V’(a)=V(a)-min(3-V©,V(a));V’(b)=V(b);V’©=V©+min(3-V©,V(a))
3.a中的水倒在地上。V’(a)=0;V’(b)=V(b);V’©=V©
4.将a装满。V’(a)=12;V’(b)=V(b);V’©=V©
5.将b中的水倒入a中。V’(a)=V(a)+min(12-V(a),V(b));V’(b)=V(b)-min(12-V(a),V(b));V’©=V©
6.将b中的水倒入c中。V’(a)=V(a);V’(b)=V(b)-min(3-V©,V(b));V’©=V©+min(3-V©,V(b))
7.将b中的水倒在地上。V’(a)=V(a);V’(b)=0;V’©=V©
8.将b装满。V’(a)=V(a);V’(b)=8;V’©=V©
9.将c中的水倒入a中。V’(a)=V(a)+min(12-V(a),V©);V’(b)=V(b);V’©=V©-min(12-V(a),V©);
10.将c中的水倒入b中。V’(a)=V(a);V’(b)=V(b)+min(8-V(b),V©);V’©=V©-min(8-V(b),V©)
11.将c中的水倒在地上。V’(a)=V(a);V’(b)=V(b);V’©=0
12.将c装满。V’(a)=V(a);V’(b)=V(b);V’©=3
目标测试:V(a)=1 or V(b)=1 or V©=1
路径消耗:每一步耗散值为1,整个解路径的耗散值是路径中的步数。
3.14
a.深度优先搜索至少要扩展与使用可采纳启发式的 A一样多的结点。
False: 一个幸运的DFS可能会精确地扩展d个节点来达到目标;A在很大程度上优于任何能保证找到最优解的图搜索算法。
b.h(n)=0对于八数码问题是可采纳的启发式。
是可采纳的启发式方法,因为成本是非负的。
c.A在机器人学中没有任何用处,原因是感知器、状态和行动都是连续的。
False:A搜索经常用于机器人技术;这个空间可以被离散化或框架化程序化。
d.即使是通路零代价的情况下,宽度优先搜索依然是完备的。
对,解决方案的深度对于广度优先搜索很重要,而不是成本。
e.假设车在棋盘上可以沿水平或垂直方向移动至任一方格中,但要注意不能跳过棋子。将车从方格 A 移到方格 B的最小移动步数问题中,曼哈顿距离是可采纳的启发式。
False:车可以在一次移动中从方格 A 移到方格 B,但是曼哈顿距离从方格 A 移到方格 B的距离是8,高估了距离成本。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)