
编译原理-词法分析器代码分析报告
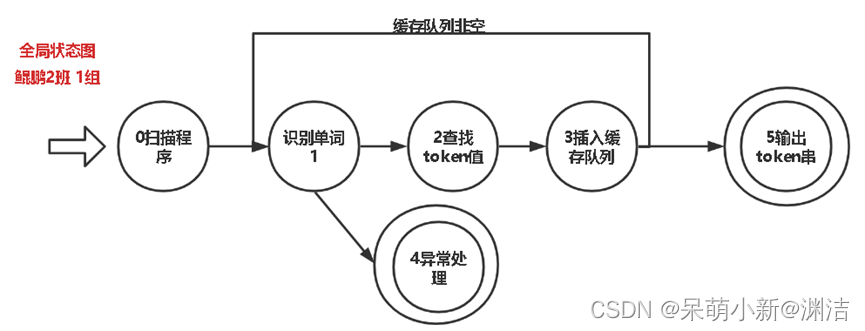
该词法分析器基于状态转换图进行设计。首先画出识别特定单词的状态转换图并编写对应的单词识别程序,然后把不同的状态转换图合并为完整的状态转换图,并编写对应的完整的识别程序。完整的识别程序中,根据输入字符的不同调用识别不同单词的程序。其中以 “//abcd\na=1”为例首字符识别为 /,进入注释除号判断操作,取容器中下一位元素而不删除当前元素
一.词法分析器设计思路说明
该词法分析器基于状态转换图进行设计。首先画出识别特定单词的状态转换图并编写对应的单词识别程序,然后把不同的状态转换图合并为完整的状态转换图,并编写对应的完整的识别程序。完整的识别程序中,根据输入字符的不同调用识别不同单词的程序。







其中以 “//abcd\na=1”为例

首字符识别为 /,进入注释除号判断操作,取容器中下一位元素而不删除当前元素.下一位依然是 /.进入if,利用迭代器跳过注释内容直到遇到换行符为止.

此时字符串//abcd\n均被剔除,则有效字符为a=1. Continue遍历下一个元素识别为a,a从缓存队列删除该元素加入处理过的队列.接下来正则匹配为非关键词.返回token值加入集合.

进行下一个元素 = 的识别. 从缓存队列删除该元素加入处理过的队列.判断词义完整性.返回token值加入集合.

最后识别1. 从缓存队列删除该元素加入处理过的队列.判断数值类型,返回token值加入集合.

最后集合为a=1

二.TinyScript的词法要求
1.给出TinyScript的字符集
英文大写字母,小写字母,数字,下划线和空白符号,以及下述特殊符号构成的集合: +,-,*,/,%,=,>,<,!,&,|,(,),{,},[,],,,.,;,’,”,\
2.列出TinyScript中的关键字


3.列出TinyScript中的运算符

三.词法分析器代码分析
词法分析器包括commom和lexer两个包,分别分析如下。
- common包
common包内的类分析如下。
(1)AlphabetHelper类
AlphabetHelper类的主要作用是定义TinyScript语言的字母表,包含以下4个属性和4个方法。
ptnLetter属性
ptnLetter是Pattern类型的模式串,用于匹配单个字母,可以是大写字母或小写字母。
ptnNumber属性
ptnNumber是Pattern类型的模式串,用于匹配0-9中的单个数字。
isLetter()方法
isLetter(char c)返回boolean类型的结果,用于判断参数c是否为字母。
(2)PeekIterator类
PeekIterator类的主要作用是定义缓存流队列,包含以下5个属性和7个方法.

● Iterator属性
定义一个变量名为it的迭代器.用来访问一个容器对象中各个元素,而又不需暴露该对象的内部细节.
● LinkedList属性
分别定义变量名为queueCache, stackPutBacks的链表数据结构.分别用来表示处理当前队列中的元素,缓存已经处理过的元素.
● Static Int 属性
用来全局静态定义缓存队列的初始大小.
● T 属性
通配符表示返回任意类型的结束符号.
● PeekIterator(Stream stream)方法
初始化构造迭代器,准备用来缓存元素
● PeekIterator(Iterator _it, T endToke)方法
初始化构造迭代器,并初始化结束符号.
● PeekIterator(Stream stream, T endToken)方法
初始化构造流对象,并初始化结束符号.
● public T peek()方法
实现取容器的下一个字符但是当前字符不会被删除
● public void putBack()方法
检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。即新插入的元素.
● public boolean hasNext()方法
重写实现类Iterator的hasNext()方法. 修改结束标准为_endToken变量的结束符.
● public T next()方法
重写实现类Iterator 的next()方法, 修改结束标准为_endToken变量的结束符.
- lexer包
(1)lexer类主要作用是进行词法分析.包含了以下3个方法.
● ArrayList analyse(PeekIterator it)方法
对缓存队列中的元素进行词法分析,主要进行以下操作:
读一非空字符
首字符分类: 如果首字符为’/’进入删除注释处理; 如果是",'开头交给字符串状态机处理; 如果是字母交给变量或关键字状态机处理; 如果是数字交给数字状态机处理; 如果是运算符交给运算符状态机处理
● ArrayList analyse(Stream source)方法
初始化流和结束符号,将词法分析后的单词token值以集合形式返回.
● static ArrayList fromFile(String src)方法
从源代码文件加载并解析文件内容.即解析代码程序文件.
(2)Keywords类主要作用是定义关键词,包含以下1个属性,2个方法
● keywords定义关键词
●static HashSet set 将字符串数组对象转化为HashsSet集合,以便有更丰富的操作.
● public static boolean isKeyword(String word)方法用来判断是否为关键词.
(3) LexicalException类主要进行字符的异常处理包含以下1个属性,3个方法
●private String msg;定义返回消息的变量
●public LexicalException(char c) 接收字符异常
●public LexicalException(String _msg)接收字符串异常
● public String getMessage() 返回异常消息
(3) Token类定义了2个属性,15个方法
● TokenType _type; String _value;分别用来定义token流的类型和值
● public Token(TokenType type, String value); 有参构造Token对象
● public TokenType getType() 获取token流类型
● public String getValue() 获取token值
● public String toString() 格式化输出流的类型和值
● public boolean isVariable() 判断是否为变量类型
● public boolean isScalar() 判断是否为标量
● public static Token makeVarOrKeyword 提取变量或关键字
● public static Token makeString(PeekIterator it) 提取字符串
● public static Token makeOp(PeekIterator it) 提取运算操作符
● public static Token makeNumber(PeekIterator it) 提取数值类型
● public boolean isNumber()判断是否为数值类型
● public boolean isOperator()判断是否为运算符
● public boolean isPostUnaryOperator()判断是否为自增自减运算符
● public boolean isType()判断是什么类型
● public boolean isValue()判断是否为变量或标量类型
(4) public enum TokenType 枚举类定义了基本词法类型
四. 测试执行过程分析【可选】
词法分析器的测试代码位于src/test/java目录下,包括commom和lexer两个包,分别分析如下。
词法分析器包括commom和lexer两个包,分别分析如下。
- common包
common包内的类分析如下。
(1)AlphabetHelperTests类
AlphabetHelperTests类的主要作用是对AlphabetHelper类的4个方法进行测试,通过test()方法验证其能否正确区分是否为相应类型的字符。

经测试,AlphabetHelper类的4个方法实现了相应功能。
(2)PeekIteratorTests类
PeekIteratorTests类的主要作用是对PeekIterator类的3个方法进行测试,通过
test_peek()方法测试迭代器是否能够正常读取字符.

test_lookahead2()方法测试检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。即测试新插入的元素.

test_endToken()方法测试结束符相关方法是否奏效.

经测试PeekIterator类的3个方法均实现相应功能.
- lexer包
(1) LexerTests类主要的作用是对Lexer类7个方法的测试.
test_expression()方法测试字符串是否能够被单词识别系统正确识别.

test_function()方法测试对方法体的识别检测.

test_deleteComment()方法主要测试对注释的删除屏蔽功能, 之后是否不影响正常代码

test_deleteErrorComment()方法主要测试对错误注释/*/的异常处理

test_deleteOneLine()方法主要测试对单行注释的删除屏蔽,之后是否不影响正常代码

Minus()方法主要测试对运算符号’-’的测试,是否成功识别.

test_loadFile方法主要对加载源文件代码的提取识别进行测试.


权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)