图神经网络
目录一 预备知识1.1 什么是图深度学习1.2 图具有的性质1.3 时域( spectral domain )和空域(spatial domain)1.4 图深度学习的任务二 Embedding2.1 什么是嵌入2.2 Skip-gram词嵌入三 图嵌入方法四 图神经网络一 预备知识1.1 什么是图深度学习深度学习的目的是从输入数据中学习出有效的特征表示,然后利用学习到的特征表示进行相应的任务。举
目录
1.3 时域( spectral domain )和空域(spatial domain)
一 预备知识
1.1 什么是图深度学习
深度学习的目的是从输入数据中学习出有效的特征表示,然后利用学习到的特征表示进行相应的任务。举例来说,对于图片识别任务,我们可以利用卷积神经网络从图片中学习出不同物体的特征表示,然后根据这些物体的特征表示进行图片识别任务。我们会根据输入数据种类的不同,设计相应的神经网络,而图深度学习指的是当输入数据是图结构的时候,我们采用的深度学习方法,一般分为图嵌入和图神经网络两种方式,图嵌入通过人为设定的算法和目标从图结构数据中学习出有效的特征表示,而图神经网络借助神经网络自动从图结构数据中学习出有效的特征表示,可以把图嵌入类比为传统的机器学习,图神经网络为深度学习。
图结构因为即可以表示数据的属性又可以表示数据之间的关系,被普遍的使用。比如在社交网络中,每个用户作为图的节点,用户之间的关系作为图的边,我们将用户自身具有的信息,比如身高、年龄、收入等,称为图信号,具体到实现中图信号是一个N维的向量。

1.2 图具有的性质
基础的图定义和性质,比如度、有向图等,这里就不在赘述了,可查阅《数据结构》相关书籍

下面说一下图的傅里叶变换
普通的傅里叶变换公式为


对应到图傅里叶变换为


![]()

从线性变换的角度来看,矩阵论告诉过我们一个矩阵对应着一个线性变换,傅里叶变换相当于是利用特征向量矩阵将图信号从原空间变换到了另外一个特征空间。
傅里叶变换的优点在于其存在逆变换,傅里叶逆变换为

矩阵形式为
![]()
傅里叶变换结果如下图所示,左侧是图信号,右侧是傅里叶变换的结果,将图结构的信号变换为离散的信号。
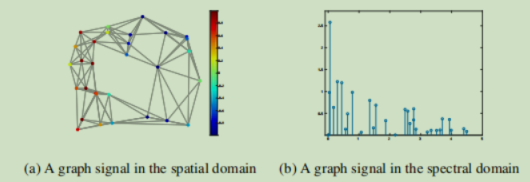
1.3 时域( spectral domain )和空域(spatial domain)
在图深度学习中,时域和空域指的是图深度学习进行特征表示学习的起始空间,如果我们直接从图信号开始处理,我们把这种处理方式叫做'空域',如果我们先将图信号进行傅里叶变换,然后在变换结果的基础上进行处理,我们把这种处理方式叫做'时域'.
1.4 图深度学习的任务
图深度学习中有以下几种常见的任务
-
侧重节点的任务:比如在图节点上进行分类或者回归
-
侧重边的任务:比如节点连接关系的预测,边权重的预测等
-
侧重整个图的任务:对整个图的分类
举个例子,我们将用户作为节点,用户之间的关系作为连接边可以构建一个社交网络,然后利用图深度学习在社交网络上进行特征表示学习,最终可以得到用户节点的特征表示或者整个社交网络的特征表示,利用这些特征表示,可以预测用户之间的连接关系,这就是侧重边的任务,
二 Embedding
2.1 什么是嵌入
在深度学习的眼中,万事万物都是向量(更准确的说叫张量),比如计算机视觉中图片的特征是向量、自然语言处理中词语是向量、推荐系统中用户的兴趣也是向量,我们把将外界事物变为向量的这个过程称为嵌入,得到的向量称为嵌入向量,准确的定义为:
嵌入通常指将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系。
那么什么是一种好的嵌入呢
-
我们希望其具有很强的表示能力,即同样大小的嵌入向量可以表示更多原事物的信息。
-
我们希望其学习过程不过于复杂,能够和其它的网络结构进行很好的衔接。
-
我们希望在嵌入向量空间中也能够体现出原事物具有的性质。
有了嵌入的概念,接下来说一种具体的嵌入方法-Skip-gram
2.2 Skip-gram词嵌入
在利用深度学习进行自然语言处理中,一般需要将词语表示为向量,我们希望表示成的向量能够较好保存词语间的语义信息,怎么达到这个目的呢,拿Skip-gram词嵌入方法进行举例。
对于
-
我吃饭
-
饭吃我
这两句话(中文语法),我们如何判断哪句话是正确的,哪句是错误的呢
传统的自然语言处理方法是从语法的层面进行分析,第一句话符合语法中的主-谓-宾结构,第二句不符合,所以认为第一句话是正确的,第二句话是错误的。
而基于统计学习的自然语言处理方法不从语法层面进行分析,而是从概率的层面进行分析,第一句话在日常生活中出现的概率比较大,而第二句话出现的概率比较小,所以认为第一句话是正确的,第二句话是错误的。
那么从概率的角度考虑,什么是词语之间的语义关系呢,我们发现某些词语一起出现的概率,相比于另外一些词语一起出现的概率要大,比如‘首都’和‘北京’一起出现的概率相比于‘自治区’和‘北京’一起出现的概率大,

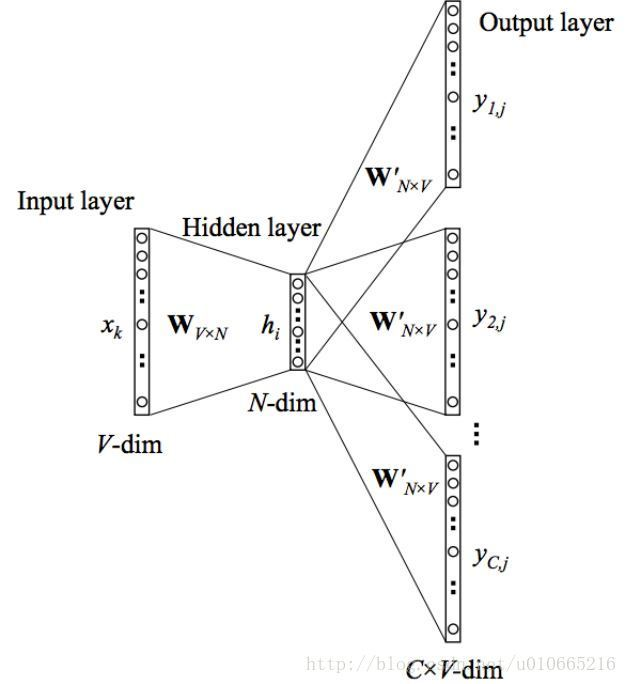
Skip-gram就基于以上的思想,通过最大化词语之间共同出现的概率来学习词语之间的语义信息以进行词嵌入,把词语表示成向量。我们将与词语A以较大概率共同出现的其它词语,称为词语A的上下文,最大化词语之间的共现概率就是让模型准确的预测出词语A的上下文,模型结构如下图

三 图嵌入方法
类似于词嵌入,图嵌入是指将图中的节点或者整个图表示为嵌入向量的方法。图嵌入包含很多种方法,这里介绍所有图嵌入方法的思想起源-DeepWalk。
《DeepWalk: Online Learning of Social Representations 》2014 KDD
这篇论文借鉴了上面说的Skip-gram词嵌入方法的思想,提出了一种图嵌入方法-DeepWalk,能够较好的保存图中节点的连接关系。
DeepWalk分为两个步骤
1.从图中采样出不同的随机游走序列
2.利用生成的随机游走序列更新图节点的表示向量


首先在图上执行随机游走过程,获得的随机游走节点序列相当于自然语言中的句子,而图中的节点相当于词语,类比Skip-gram的思想,DeepWalk通过最大化节点之间的共现概率,学习图节点的嵌入向量。
以下图举例,假设我们要学习下图中节点的嵌入向量表示

PyTorch代码为
import torch
import torch.nn as nn
import random
# 图嵌入方法-DeepWalk
# 方法出处 2014 KDD 《DeepWalk: Online Learning of Social Representations》
# 图的邻接表
adj_list = [[1, 2, 3], [0, 2, 3], [0, 1, 3], [0, 1, 2], [5, 6], [4, 6], [4, 5], [1, 3]]
# 图的节点个数
size_vertex = len(adj_list)
# 超参数设置
# 上下文窗口大小
w = 3
# 图节点嵌入向量的维度
d = 2
# 要执行DeepWalk的次数
y = 200
# 随机游走序列的长度
t = 6
# 学习率
lr = 0.025
# 节点标记
v = [0, 1, 2, 3, 4, 5, 6, 7]
# 随机游走
def RandomWalk(node, t):
"""
:param node: 随机游走开始的节点
:param t: 随机游走序列的长度
:return: 以node为起点,长度为t的随机游走序列
"""
# 初始化随机游走序列
# 将随机游走开始节点加入序列
walk = [node]
# 生成长度为t的随机游走序列
for i in range(t - 1):
# 随机移动到node的邻接节点中
# adj_list[node][next_v]表示node节点的邻接节点
# 其中random.randint(0,len(adj_list[node])表示从[0,到node的邻接节点数]中随机生成一个整数
# 即随机生成一个node的邻接节点编号
# next_v=random.randint(0,len(adj_list[node])-1,减1是因为节点在矩阵中的编号
# 和真实编号少1
node = adj_list[node][random.randint(0, len(adj_list[node]) - 1)]
# 加入到随机游走序列中
walk.append(node)
# 返回随机游走序列
return walk
# 图节点嵌入前馈神经网络
# 三层网络结构
class Embedding(torch.nn.Module):
def __init__(self):
# 所有继承于nn.Module的模型都要写这句话
super(Embedding, self).__init__()
# 隐藏层
# 维度=[节点个数,节点嵌入向量的维度]
# 也可以这样写
# self.hidden_layer=nn.Linear(size_vertex,d)
# nn.Parmeter可以理解为一个张量
# 这个张量保存了网络学习到的数值
# 具体到这个网络
# 最后hidden_layer就是图节点通过随机游走的嵌入矩阵
# torch.rand((size_vertex,d)相当于为张量进行了初始化
# 标记requires_grad=True
# 表示在这个网络反向传播的过程中
# hedden_layer中的参数需要更新
self.hidden_layer = nn.Parameter(torch.rand((size_vertex, d), requires_grad=True))
# 输出层
# 维度=[节点嵌入维度,节点个数]
# 也可以这样写
# self.out_layer=nn.Linear(d,size_vertex)
self.out_layer = nn.Parameter(torch.rand((d, size_vertex), requires_grad=True))
# 前向传递,构建计算图
def forward(self, one_hot):
"""
:param one_hot:输入网络的节点的one_hot向量表示
:return:输出在当前节点出现的情况下,其它节点出现的概率
"""
hidden = torch.matmul(one_hot, self.hidden_layer)
out = torch.matmul(hidden, self.out_layer)
return out
model = Embedding()
# 更新节点嵌入网络
# skip_gram和CBOW都是来自于NLP中的词嵌入模型
# skip_gram是通过一个词预测在当前词出现的情况下其它词出现的概率,也就是这个词的上下文信息
# CBOW正好相反,它是通过一些词语,也就是上下文信息,预测在这些词出现的条件下,下一个最有可能出现的词
def skip_gram(random_walk_list, w):
"""
:param random_walk_list: 随机游走序列
:param w: 上下文窗口大小
:return: 更新节点的嵌入向量表示
"""
# 对于随机游走序列中的每一个节点(可以看作是一个词语)
for j in range(len(random_walk_list)):
# 生成这个节点以w作为窗口大小的上下文节点信息(在当前节点出现的情况下,都有哪些节点出现了)
# 其中max,min函数防止越界
for k in range(max(0, j - w), min(j + w, len(random_walk_list))):
# 生成中心节点j的one_hot编码
one_hot = torch.zeros(size_vertex)
one_hot[random_walk_list[j]] = 1
# 获取当j节点出现时,最有可能出现的上下文信息
out = model(one_hot)
# 根据模型预测出的上下文信息
# 和真实的通过随机游走生成的上下文信息
# 计算损失函数
# 这个损失函数是-softmax()函数的展开,因为要梯度下降,所以softmax加了符号
loss = torch.log(torch.sum(torch.exp(out))) - out[random_walk_list[k]]
# 反向传递
loss.backward()
# 更新网络参数
for param in model.parameters():
param.data.sub_(lr * param.grad)
param.grad.data.zero_()
# 通过DeepWalk算法
# 生成图节点的嵌入向量
for i in range(y):
# 随机打乱节点
random.shuffle(v)
# 对于节点序列中的每一个节点
for vi in v:
# 生成一个以vi为起点的,长度为t的随机游走序列
random_walk_list = RandomWalk(vi, t)
# 根据这个生成的随机游走序列
# 更新节点嵌入矩阵
skip_gram(random_walk_list, w)
# 输入节点嵌入矩阵
# 其中每一行表示当前节点在DeepWalk算法下的嵌入向量
print("图节点嵌入矩阵为")
# 转为numpy形式之前
# 需要调用detach()将当前张量从计算图中分离才能进行转换
print(model.hidden_layer.detach().numpy())四 图神经网络
(更多图神经网络论文和其的PyG代码可见图神经网络框架PyTorch Geometric(PyG)中部分图卷积层的论文及源代码)
要注意图神经网络并不是提出了新的神经网络结构,而是一种依赖神经网络的特征学习方法,更准确的叫法应该叫做图卷积,图神经网络经历了从时域图卷积到空域图卷积的发展,这里图卷积中的'卷积'并不是指卷积神经网络中的卷积计算,而是取它广义的特征提取意思,下面这篇文章是从时域图卷积到空域图卷积中间过渡的重要论文。
《Inductive Representation Learning on Large Graphs 》2017 NIPS
这篇文章从信息传递、融合的角度重新看图卷积的过程。具有承前启后的重要意义,图神经网络框架PyG(具体介绍可见我的图神经网络框架-PyTorch Geometric(PyG)的使用及踩坑)中的图卷积模块(MessagePassing)也是采用这种思想进行构建的。
在这篇文章之前的图嵌入方法或者图神经网络都存在一个缺点:如果想要得到特征表示的节点不在训练的时候就加入到图结构中,我们就无法获取它的特征表示(嵌入表示)。也就是以往的方法都是在直推式学习(transductive learning)框架下进行的,即假设要测试的节点(要获取特征表示的节点)和训练节点在一个图中,并且在训练过程中图结构中的所有节点都已被模型考虑进去。它们只能得到已经包含在训练过程中节点的嵌入表示,对于训练过程中没有出现过的未知节点不起作用。
这篇文章有别于以往的方法,提出了一种归纳式学习(inductive learning)的方式,一种新的空域图卷积-GraphSAGE。
GraphSAGE中的SAGE是SAmple(采样)和AggreGatE(聚合)的缩写。它的主要想法是:先把当前节点邻接点的信息(特征表示)用一个聚合函数(Aggregate)进行汇聚,然后再与节点自身的信息进行融合,更新当前节点的特征表示。算法流程为

通过神经网络学习出聚合和融合过程中的参数,这样即使遇到未知的节点,也可以通过一样的聚合、融合过程得到其相应的特征表示,并且在GraphSAGE中利用了邻接点采样的方法加速网络的训练过程,在GraphSAGE中作者认为聚合函数应该是对称的、满足置换不变性的,这样无论我以什么顺序输入当前节点邻接节点的信息,聚合的结果都相同,并提出了三种聚合函数-Mean(均值聚合)、LSTM聚合、Max(最大值聚合):



因为LSTM不满足对称性,每次输入相邻节点信息时要将节点进行随机排列。
看PyG中的GraphSAGE源码


首先给出了卷积计算公式(注意PyG里的SAGEConv用的聚合函数是均值聚合),然后参数的意义如下:
-
in_channels,out_channels,bias,kwargs:图信号的维度、卷积输出的节点特征表示的维度,是否使用偏置
-
normalize:指定是否对最后输出的节点特征表示结果进行正则化,默认False
-
root_weight:指定是否计算公式中的第一部分,默认是True
PyG源代码为
class SAGEConv(MessagePassing):
# 卷积层的初始化
def __init__(self, in_channels: Union[int, Tuple[int, int]],
out_channels: int, normalize: bool = False,
root_weight: bool = True,
bias: bool = True, **kwargs): # yapf: disable
# 定义聚合函数为'mean'
kwargs.setdefault('aggr', 'mean')
super(SAGEConv, self).__init__(**kwargs)
# 保存输入的参数配置
self.in_channels = in_channels
self.out_channels = out_channels
self.normalize = normalize
self.root_weight = root_weight
# 看公式,因为是分为两部分计算
# 所以复制一下输入的维度
if isinstance(in_channels, int):
in_channels = (in_channels, in_channels)
# 公式第二部分中的W,一个线性变换层
self.lin_l = Linear(in_channels[0], out_channels, bias=bias)
# 公式第一部分中的W
if self.root_weight:
self.lin_r = Linear(in_channels[1], out_channels, bias=False)
# 参数初始化
self.reset_parameters()
def reset_parameters(self):
self.lin_l.reset_parameters()
if self.root_weight:
self.lin_r.reset_parameters()
# 公式中的第二部分
# 没对节点信息做任何变换,只是最后进行了一个均值汇聚
# 而均值汇聚这个操作我们前面指定完了
# 这里不用做任何事了
def message(self, x_j: Tensor) -> Tensor:
return x_j
# 稀疏连接情况下的
def message_and_aggregate(self, adj_t: SparseTensor,
x: OptPairTensor) -> Tensor:
adj_t = adj_t.set_value(None, layout=None)
return matmul(adj_t, x[0], reduce=self.aggr)
# 卷积
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
size: Size = None) -> Tensor:
# 复制一下输入
# 分别计算公式的两个部分
if isinstance(x, Tensor):
x: OptPairTensor = (x, x)
# 公式的第二部分
# 进行信息的传递,融合
out = self.propagate(edge_index, x=x, size=size)
# 线性变换
out = self.lin_l(out)
# 公式的第一部分
x_r = x[1]
# 如果指定了root_weight
if self.root_weight and x_r is not None:
out += self.lin_r(x_r)
# 如果指定了进行正则化
if self.normalize:
out = F.normalize(out, p=2., dim=-1)
# 返回卷积得到的特征表示
return out
# 输出信息
def __repr__(self):
return '{}({}, {})'.format(self.__class__.__name__, self.in_channels,
self.out_channels)
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)