
【论文精读】--ResNet
沐神论文精度:https://www.bilibili.com/video/BV1P3411y7nn/?spm_id_from=pageDriver论文地址:https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html参考代码:https://github.co
沐神论文精度:https://www.bilibili.com/video/BV1P3411y7nn/?spm_id_from=pageDriver
论文地址:https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
参考代码:https://github.com/bubbliiiing/classification-pytorch/tree/main/nets
1、Introduction
提出问题:随着网络越来越深,梯度就会出现爆炸或者消失
解决方法:
1、在权重随机初始化的时候,不要特别大也不要特别小
2、在中间加入一些normalization,包括BN(batch normalization)可以使得校验每个层之间的输出和梯度的均值和方差相对来说比较深的网络是可以训练的,避免有一些层特别大,有一些层特别小,使用这些技术之后能够收敛,但是当网络变深的时候,性能其实是变差的
文章提出出现精度变差的问题不是因为层数变多了,模型变复杂了才导致的过拟合,是因为训练误差和测试误差都变高了,不是overfitting。虽然网络收敛了但是训练的效果不好。
这篇文章提出显示地构造一个identity mapping,使得深层的神经网络不会变得比相对较浅的神经网络更差,也就是deep residual learning frameword:
要学的东西叫做H(x),现在浅层神经网络的输出为x,现在在这个浅的神经网络上面新加一些层使得它变得更深。新加的层不要直接去学H(x),而是去学H(x)-x,x是原始的浅层神经网络已经学到的一些东西,新加的层不要重新去学习,而是去学习学到的东西和真实的东西之间的残差,最后整个神经网络的输出等价于浅层神经网络的输出x和新加的神经网络学习残差的输出之和,将优化目标从H(x)转变为了H(x)-x
这样做的好处在于只是加了一个东西进来,没有任何需要学的参数,也没有增加模型复杂度,也不会使得计算变得复杂。
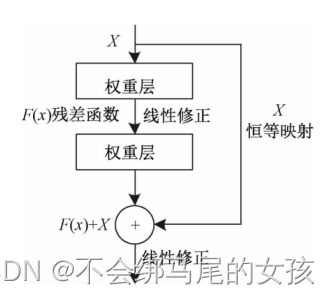
3、Deep Residual Learning
残差连接如何处理输入和输出形状是不太的情况:
1、在输入和输出上分别添加一些额外的0,使得这两个形状能够对应起来然后可以相加
2、在identity mapping经过1x1卷积核,步幅为2,使得高宽减半,通道数增加一倍。
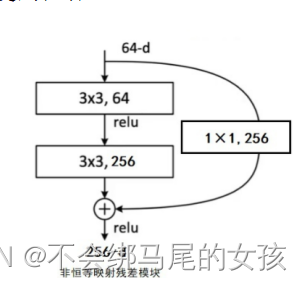
在整个残差连接,如果后面新加上的层不能让模型变得刚好的时候,因为有残差连接的存在,新加的层应该是不会学到任何东西也就是都是靠近0的,这样就等价于就算是训练了1000层的ResNet,但是可能就前100层有用,后面的900层基本上因为没有什么东西可以学的,基本上就不会动了
4、为什么ResNet训练起来比较快?
一方面是因为梯度上保持的比较好,新加一些层的话,加的层越多,梯度的乘法就越多,因为梯度比较小,一般是在0附近的高斯分布,所以就会导致在很深的时候比较小(梯度消失)。虽然Batch Normalization或者其他东西能够一定程度上改善,但是实际上相对来说还是比较小,但是如果是加了个ResNet话,好处就是在原有的基础上加上了浅层网络的梯度,深层的网络梯度很小没有关系,浅层的网络可以进行训练,变成了加法,一个小的数加上一个大的数,相对来说梯度还是比较大的。也就是说,不管后面新加的层数有多少,前面浅层网络的梯度始终是有用的,这就是从误差反向传播的角度来解释为什么训练的比较快
另一方面,因为在加了残差连接的情况下,因为梯度比较大,所以就没有那么容易收敛,导致一直能够往前。SGD的精髓就是能够一直能跑的动,如果哪一天跑不动了,梯度没了就完了,就会卡在一个地方出不去了,所以它的精髓就在于需要梯度够大,要一直能够跑,因为有噪音的存在,所以慢慢的他总是会收敛的,所以只要保证梯度一直够大,其实到最后的结果就会比较好

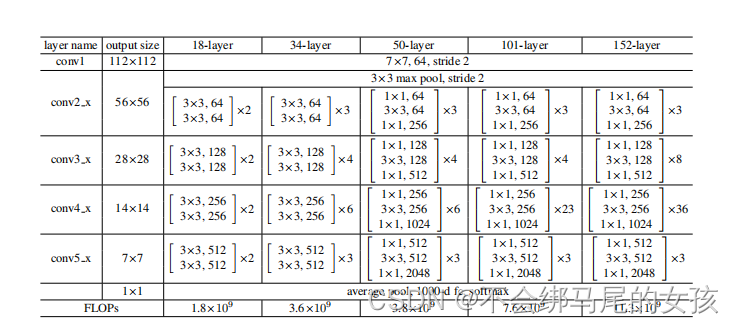
5、ResNet50结构
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的。ResNet已经被广泛运用于各种特征提取应用中,当深度学习网络层数越深时,理论上表达能力会更强,但是CNN网络达到一定的深度后,再加深,分类性能不会提高,而是会导致网络收敛更缓慢,准确率也随着降低,即使把数据集增大,解决过拟合的问题,分类性能和准确度也不会提高。但是一些学者们发现残差网络能够解决这一问题。
ResNet50 中包含了 49 个卷积层和 1 个全连阶层,其中,第二至第五阶段中的 ID BLOCK x2 代表的是两个不改变尺寸的残差块,CONV BLOCK 代表的是添加尺度的残差块,每个残差块包含三个卷积层,因此有 1 + 3×(3+4+6+3)= 49 个卷积层,结构如图 8 所示。
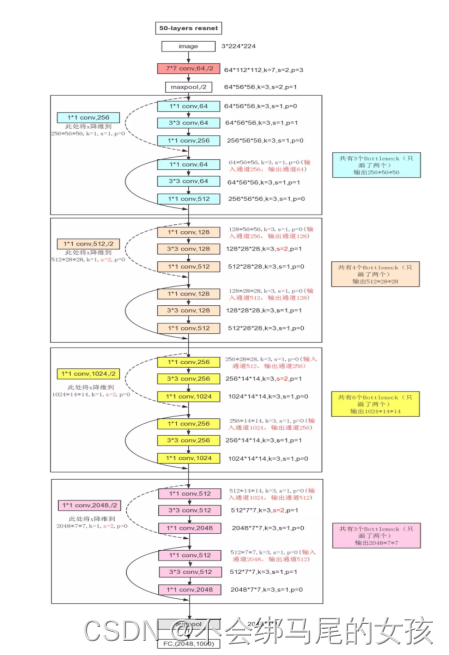
6、ResNet50代码
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
#可以下载resnet50权重
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
# ResNet(Bottleneck, [3, 4, 6, 3])
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64#输出通道数
self.dilation = 1
#replace_stride_with_dilation决定是否使用膨胀卷积(它是在标准卷积的基础上注入空洞,以此增加感受野reception field)
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.block = block
self.groups = groups
self.base_width = width_per_group
# 224,224,3 -> 112,112,64
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
# 112,112,64 -> 56,56,64
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 56,56,64 -> 56,56,256
self.layer1 = self._make_layer(block, 64, layers[0])
# 56,56,256 -> 28,28,512
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
# 28,28,512 -> 14,14,1024
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
# 14,14,1024 -> 7,7,2048
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
# 7,7,2048 -> 2048
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 2048 -> num_classes
self.fc = nn.Linear(512 * block.expansion, num_classes)
#根据网络层的不同定义不同的初始化方式
for m in self.modules():
if isinstance(m, nn.Conv2d):
#针对Xavier在relu表现不佳被提出。基本思想仍然从“输入输出方差一致性”角度出发,在Relu网络中, 假设每一层有一半的神经元被激活,另一半为0。一般在使用Relu的网络中推荐使用这种初始化方式。
#
# kaiming均匀分布
# torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
# 服从 U(-a, a), a = sqrt(6 / (1 + b ^2) * fan_in), 其中b为激活函数的负半轴的斜率, relu是0
# model 可以是fan_in或者fan_out。fan_in 表示使正向传播时,方差一致; fan_out使反向传播时, 方差一致
# nonlinearity 可选为relu和leaky_relu, 默认是leaky_relu
# kaiming正态分布, N~ (0,std),其中std = sqrt(2/(1+b^2)*fan_in)
# torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
#常数初始化
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
#0初始化残差
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:#膨胀卷积参数
self.dilation *= stride
stride = 1
#当步幅不为1或者输入通道数不等于输出通道数的时候,要进行下采样使得通道维数相匹配
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
# Conv_block
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
# identity_block
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
#ResNet50前向传播函数
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#按照x的第一个维度进行拼接->(batch_size,2048)
x = torch.flatten(x, 1)
#全连接层(batch_size,2048)->(batch_size,1000)
x = self.fc(x)
return x
#冷冻训练
def freeze_backbone(self):
backbone = [self.conv1, self.bn1, self.layer1, self.layer2, self.layer3, self.layer4]
for module in backbone:
for param in module.parameters():
param.requires_grad = False
#解冻训练
def Unfreeze_backbone(self):
backbone = [self.conv1, self.bn1, self.layer1, self.layer2, self.layer3, self.layer4]
for module in backbone:
for param in module.parameters():
param.requires_grad = True
def resnet50(pretrained=False, progress=True, num_classes=1000):
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
state_dict = load_state_dict_from_url(model_urls['resnet50'], model_dir='./model_data',
progress=progress)
model.load_state_dict(state_dict)
if num_classes!=1000:
model.fc = nn.Linear(512 * model.block.expansion, num_classes)
return model

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)