paddle模型的保存与加载
一、什么是模型的保存与加载?人工智能模型本质上就是一堆参数,我们训练模型时就是使这些参数在某个任务上合理以使其能够得到较为准确预测结果输出。例如猫狗分类任务,训练一系列卷积核数值能够通过前向计算预测出类别。我们花了大量时间训练的模型肯定不想只训练结束后只使用一次,我们想的肯定是能够重复使用这个模型在后续的任务上继续做预测。那就涉及到模型的保存与加载。二、模型的保存paddle框架中模型保存加载相关
一、什么是模型的保存与加载?
人工智能模型本质上就是一堆参数,我们训练模型时就是使这些参数在某个任务上合理以使其能够得到较为准确预测结果输出。例如猫狗分类任务,训练一系列卷积核数值能够通过前向计算预测出类别。我们花了大量时间训练的模型肯定不想只训练结束后只使用一次,我们想的肯定是能够重复使用这个模型在后续的任务上继续做预测。那就涉及到模型的保存与加载。
二、模型的保存
paddle框架中模型保存加载相关API
paddle.save
paddle.load
paddle.jit.save
paddle.jit.load
paddle.static.save_inference_model
paddle.static.load_inference_model
其中paddle.save/load用于只保存/载入模型参数
paddle.jit.save/load可用于保存模型结构用作以后的推理
paddle.static.save_inference_model/load_inference_model用于保存静态图模型
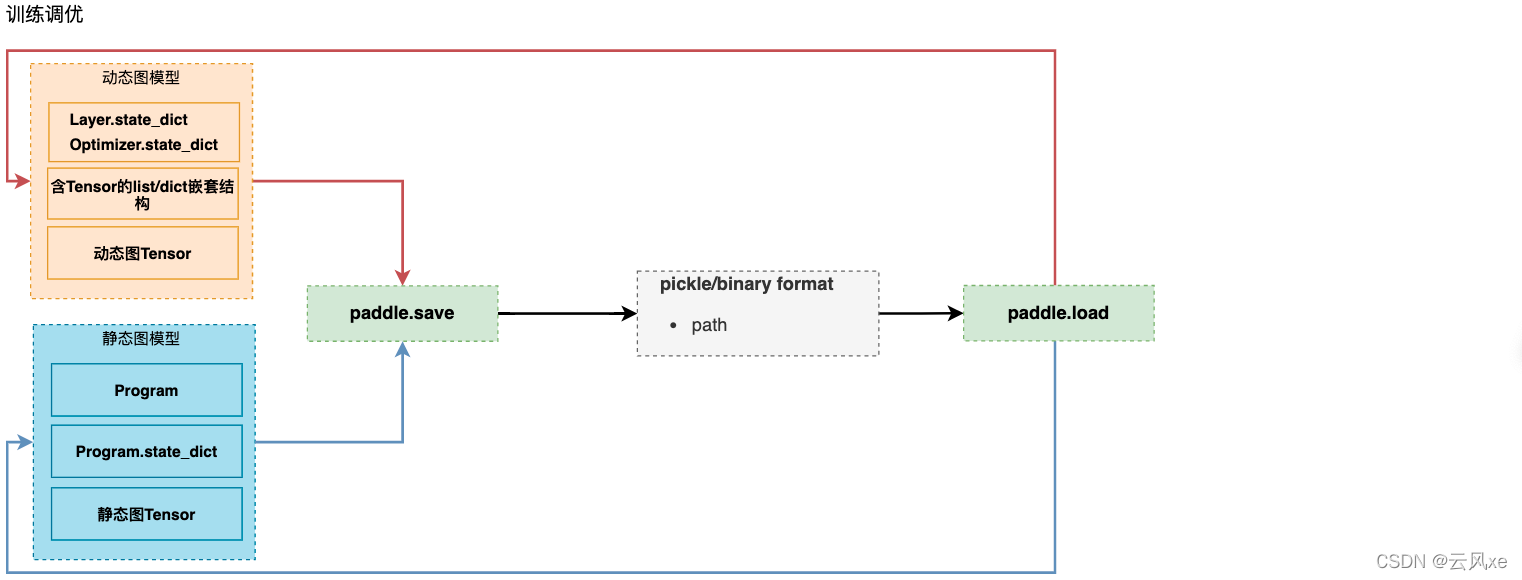
api关系图
下面以一个paddle官方文档中给出的一个例子学习这几个api的使用,我会详细地注释每一行代码。
import numpy as np#引入nunpy计算包
import paddle#引入paddle包
import paddle.nn as nn#引入网络结构包
import paddle.optimizer as opt#引入优化器包
BATCH_SIZE = 16#batch_size:表示一批数据包含多少条数据,这里是16条数据
BATCH_NUM = 4#batch数
EPOCH_NUM = 4#训练轮数
IMAGE_SIZE = 784#输入数据尺寸
CLASS_NUM = 10#标签类别数
# define a random dataset
class RandomDataset(paddle.io.Dataset):#生成数据集类,模拟一个数据集
def __init__(self, num_samples):
self.num_samples = num_samples#样本数
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')#生成数据
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')#生成标签
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):#搭建网络结构
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)#网络为一全连接层,输入784维输出10维
def forward(self, x):
return self._linear(x)#前向计算
def train(layer, loader, loss_fn, opt):#训练函数
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)#输出结果
loss = loss_fn(out, label)#得到损失函数
loss.backward()#反向传播
opt.step()
opt.clear_grad()#清除梯度
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
一、参数保存
1.paddle.save/load保存模型参数
参数保存时,先获取目标对象(Layer或者Optimzier)的state_dict,然后将state_dict保存至磁盘,示例如下(接前述示例):
# save
paddle.save(layer.state_dict(), "linear_net.pdparams")
paddle.save(adam.state_dict(), "adam.pdopt")
2.载入模型参数
参数载入时,先从磁盘载入保存的state_dict,然后通过set_state_dict方法配置到目标对象中,示例如下(接前述示例):
# load
layer_state_dict = paddle.load("linear_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
layer.set_state_dict(layer_state_dict)
adam.set_state_dict(opt_state_dict)
2.1仅保存模型参数
若仅需保存模型参数,不保存模型结构则可通过paddle.save/load保存参数
import paddle
import paddle.static as static
paddle.enable_static()
# create network
x = paddle.static.data(name="x", shape=[None, 224], dtype='float32')#创建输入到模型中的参数
z = paddle.static.nn.fc(x, 10)#前向计算
place = paddle.CPUPlace()
exe = paddle.static.Executor(place)
exe.run(paddle.static.default_startup_program())
prog = paddle.static.default_main_program()
接下来保存参数
paddle.save(prog.state_dict(), "temp/model.pdparams")
如果想要保存整个静态图模型,除了state_dict还需要保存Program
paddle.save(prog, "temp/model.pdmodel")
二、训练部署场景的模型&参数保存载入
2.1动态图模型&参数保存载入(保存训练推理的模型)
若要同时保存/载入动态图模型结构和参数,可以使用 paddle.jit.save/load 实现。
模型&参数存储根据训练模式不同,有两种使用情况:
1.动转静训练 + 模型&参数保存
2.动态图训练 + 模型&参数保存
2.1.1动转静训练 + 模型&参数保存
动转静训练相比直接使用动态图训练具有更好的执行性能,训练完成后,直接将目标Layer传入 paddle.jit.save 保存即可。:
一个简单的网络训练示例如下:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
# define a random dataset
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
@paddle.jit.to_static
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# create network
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# create data loader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# train
train(layer, loader, loss_fn, adam)
随后使用 paddle.jit.save 对模型和参数进行存储(接前述示例):
# save
path = "example.model/linear"
paddle.jit.save(layer, path)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)