分布式文件系统-Facebook haystack
0、分布式文件系统分布式文件系统很常见,主要功能:存储文档、视频、图像等作为分布式表格系统的存储层这类系统很多,比如:国外系统:GFS-(Google File System)、haystack(Fackbook图片存储系统)国内:淘宝TFS、这些系统架构和设计很多都相似,同时也有细微之处有许多区别,最近因为需要给一个朋友讲解haystack,重读了haystack,记录做下总结一、背景Faceb
0、分布式文件系统
分布式文件系统很常见,主要功能:
- 存储文档、视频、图像等
- 作为分布式表格系统的存储层
这类系统很多,比如:
国外系统:GFS-(Google File System)、haystack(Fackbook图片存储系统)
国内:淘宝TFS
这些系统架构和设计很多都相似,同时也有细微之处有许多区别,最近因为需要给一个朋友讲解haystack,重读了haystack,记录做下总结
一、背景
Facebook在2012年发布了《Finding a needle in Haystack: Facebook’s photo storage》论文,实现了小文件(图片)的高性能的存储系统。
Facebook目前存储了2600亿张照片,总大小为20PB,通过计算每张照片的平均大小为20PB/260GB,约80KB。用户每周新增照片数为10亿(总大小为60TB),平均每秒新增的照片数为10亿/7/40000(按每天40000s计算,半天时间),约为每秒3500次写操作,读操作峰值可以达到每秒百万次。
Facebook相册后端早期采用基于NAS的存储,通过NFS挂载NAS中的照片文件来提供服务。后来出于性能和成本考虑,自主研发了Facebook Haystack存储相册数据。Haystack是一个对象存储系统,主要解决facebook的图片存储问题。图片存储访问特点:
- Write once:往往只写一次
- Read often : 读很多次,被很多朋友或者陌生人浏览
- Never Modified:基本不更改
- Rarely Deleted:删除比较少
传统文件系统问题:
如果使用常用文件系统(比如POSIX),读取一张照片需要多次磁盘操作: 将文件名转换为inode号,从磁盘读取inode,最后读取文件本身
过多的磁盘IO操作,会影响系统的整体吞吐。
Haystack 设计的目标:
-
高吞吐,低延迟(High throughput and low latency)
keeping all metadata in main memory,在内存中维护照片的META信息,避免IO -
可容错(Fault-tolerant)
可以处理服务宕机、硬件故障、网络、BUG等 -
低成本(Cost-effective)
Haystack’s cost per terabyte of usable storage and Haystack’s read rate normalized for each terabyte of usable storage.<br /> In Haystack, each usable terabyte costs 28% less and processes 4x more reads per second than an equivalent terabyte on a NAS appliance.<br /> 相比之前基于NFS的架构,存储成本降低,读的速度提升 -
实现简单(Simple)
保证能快速迭代和上线
二、早期架构
2.1 经典设计
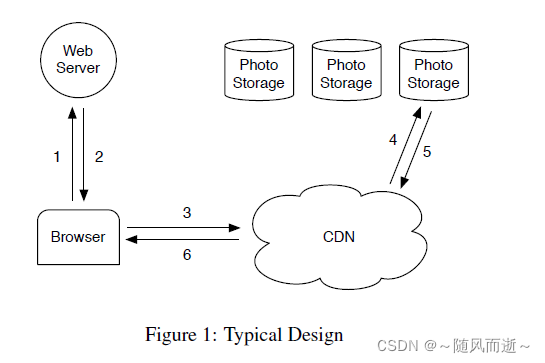
- 用户通过浏览器访问页面,发送HTTP请求到Web服务器访问照片
- Web服务器为每个照片生成一个URL链接,并重定向到CDN
- 对于流行的网站,这个URL通常指向一个CDN。如果CDN缓存了图像,那么CDN会立即响应数据
- 如果CDN不包含该照片,解析URL到真实存储系统获取照片,并缓存在CDN中
2.2 基于NFS的设计
Facebook 使用了CDN来缓存热点的图片。但是社交网络,有大量的请求都不是热点,也就是大量的长尾(long tail)请求,比如很多老照片。而缓存所有的图片的代价高昂。来长尾的请求占了Facebook 流量的很大一部分,几乎这些的请求都访问后台的照片存储。
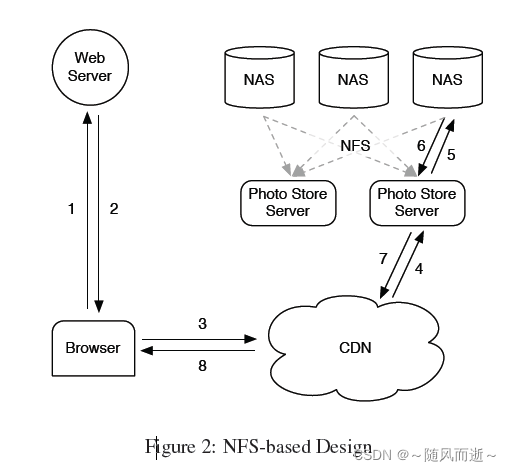
用一系列NAS设备存储照片,Photo Store servers通过NSF挂载这些NAS。Photo Store servers从照片的URL提取卷以及文件的完整路径信息,通过NFS读取数据,并将结果返回给CDN。
一个NFS卷的每个目录中存储了数千个文件,后果是:即使是读取一张照片,也会导致过多的磁盘操作。因为目录的块映射(blockmap)太大,设备无法有效地缓存它。优化方式:一个NFS目录保存上百个文件,一个读操作还至少需要3次IO操作:
- 在父目录中查找directory metadata,并从磁盘加载到内存
- 在磁盘读取文件的inode结构
- 读取文件内容
同时为了进一步减少IO操作,Photo Store servers每次打开文件,都在内存中保持了文件句柄,这样下次访问的时候,就可以通过自定义的系统调用open by filehandle,来直接进行。该优化存在问题:对于非热点照片,基本不可能被缓存。
同时是否可以缓存所有文件句柄? 但是只能解决部分问题,因为这依赖于NAS设备将其所有inode都放在内存中,这对于传统文件系统来说是一种昂贵的需求。
三、Haystack设计和实现
Facebook使用CDN来提供流行/热点图片,并利用Haystack来有效地响应长尾图片请求。对于非热点图片,即长尾请求,设计思路是尽量减少磁盘IO操作,因此对于文件的META信息特殊设计,这样将META信息都缓存在内存中。
注意两个概念:
Application metadata describes the information needed to construct a URL that a browser can use to retrieve a photo. 浏览器为用户访问照片维护的META信息
Filesystem metadata identifies the data necessary for a host to retrieve the photos that reside on that host’s disk. 照片文件存储的META
3.1 整体架构
最主要三个核心组件:
Haystack Store
物理存储节点,以物理卷轴(physical volume)的形式组织存储空间,照片写在物理卷轴,每个物理卷轴一般很大,比如100GB,这样10TB的数据只需100个物理卷轴。每个物理卷轴对应一个物理文件,因此,每个存储节点上的物理文件元数据都很小。多个物理存储节点上的物理卷轴组成一个逻辑卷轴(logical volume),用于备份。
Haystack Directory
维护映射关系logical to physical mapping
存放逻辑卷轴和物理卷轴的对应关系,以及照片id到逻辑卷轴之间的映射关系
Haystack Cache
主要用于解决对CDN提供商过于依赖的问题,提供最近增加的照片的缓存服务
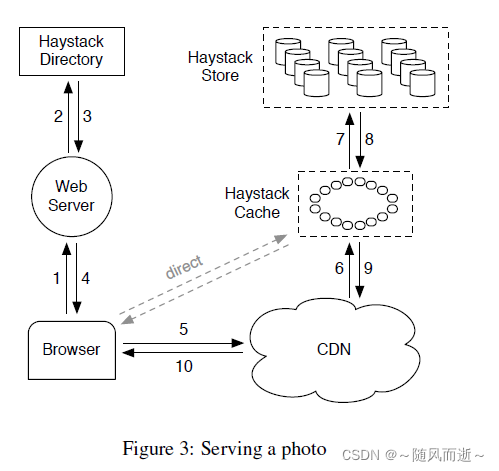
如上图,用户可能访问到CDN或者Haystack Cache。
用户请求一个照片,Haystack Directory会按照如下规则生成URL:
http://<CDN>/<Cache>/<Machine id>/<Logical volume,Photo>
上述规则有很多部分组成,后续根据各个部分的信息依次访问CDN、Haystack缓存和后端的Haystack存储节点。比如CDN没有该照片信息,就会请求缓存等。
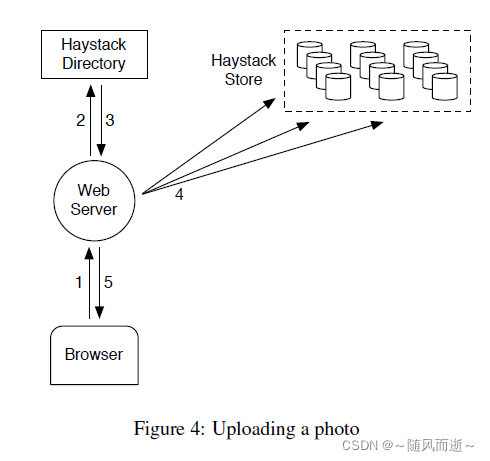
如上图,当用户上传一个照片时,Haystack目录为照片生成唯一ID,将其上传到映射到指定逻辑卷的每个物理卷。
这里留意一个write-enabled机器概念,当为Haystack Store新加机器扩容时,这些机器会标记为只写,避免大量读请求打到该机器(这个很好理解,当新增照片的时候,往往会带来很多访问量,类似微信朋友圈)后面还会具体讨论。
3.2 Haystack目录
目录主要提供四个功能:
- 逻辑卷到物理卷的映射关系:用于写请求(上传照片)和读请求(为照片构建上述访问的URL)
- 读写之间的负载均衡,决定读请求或者写请求去哪里
- 决定一个照片请求是由CDN处理还是缓存处理
- 如果逻辑卷达到存储容量上限,标识为只读
3.3 Haystack Cache
缓存既接受来自CDN的HTTP请求,也直接接受来自用户的请求
数据结构是一个分布式哈希表,并使用照片的id作为键来定位缓存的数据。如果缓存无法命中,那么就会从Haystack Store层读取数据。
Haystack Cache在满足如下两种场景下,才会缓存照片:
- 该请求直接来自用户,而不是CDN。基于经验,CDN无法命中的请求,也基本不可能在Haystack Cache命中,因此需要缓存上,保证后续可以在Haystack Cache中命中。
- 照片是从write-enabled机器存储上获取的。照片往往一上传,会获取大量访问-读请求,因此如果该情况不进行缓存,write-enabled机器同时会有大量读请求,会影响系统吞吐以及不稳当,因此对于上述场景,直接缓存上,是一种针对业务特点很好的优化
3.4 Haystack Store
每个Store机器上包含多个物理卷,而每个卷包含数百万张照片。一个物理卷可以认为非常大的文件,比如100G,按照如下格式保存:
‘/hay/haystack ’

物理卷设计如图5:开始是一个superblock,后续是一系列Needle(每一个代表一张照片)
每个Needle设计的字段以及如表1,很多字段都语义很清楚,其中需要关注几点如下:
- Key: 生成的照片ID
- alternatekey:对于每张照片,FaceBook为其都会生成4个大小的照片,用于不同的高清度。因此会附加alternatekey来标记不同的大小
Store机器上用(key, alternatekey)映射相应的Needle信息
- Flags: 标记删除
3.4.1 读流程
- 当需要从Haystack Store请求照片,提供参数如下:logical volume id, key, alternate key, and cookie
其中cookie是在Haystack目录随机生成和分配,避免黑客攻击,构造有效的URL
- 当Haystack Store收到上述请求,Haystack Store先在内存中查找应映射关系,如果照片没有被删除,Haystack Store在卷中查找实际偏移位置,在确认存储的cookie一致,以及校验和通过过,返回照片给Haystack Cache
3.4.2 写流程
-
当需要上传一张照片,Haystack web服务器将Haystack目录生成以及分配的the logical volume id, key, alternate key, cookie以及照片数据传给Haystack Store
-
为了高可用,往往照片也采用多副本,每个机器收到请求,开始同步追加needle(照片)到自身的物理卷,同时更新内存映射,因为只能追加写,不允许覆盖写,其实有一些限制,比如修改照片等流程
-
当需要修改照片,只会采用同样的key, alternate key来生成和存储新的needle,分如下情况讨论:
(1)如果新的needle和初始照片写在不同的逻辑卷, Haystack目录会更新application metadata,保证后续用户不会再访问老的请求
(2) 如果新的needle和初始照片写在相同的逻辑卷, Haystack Store会追加到同样的物理卷,基于位置偏移来区分照片的新旧,只返回最高偏移的照片,保证是最新的照片
3.4.3 删除流程
删除照片,只是标记删除,在内存映射删除flag,文件追加一个删除标记的needle
3.4.4 索引文件
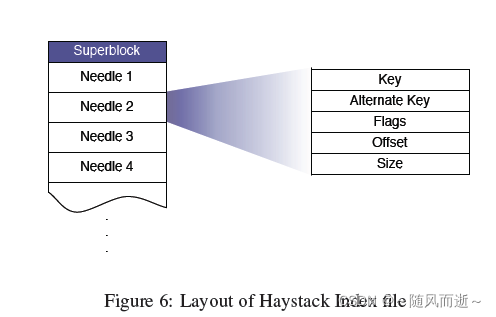

Haystack Store设计了索引文件,进行优化,本质上优化机器重启后,如何快速构建和恢复宕机前的状态。
如果没有索引文件,机器宕机重启后,可用通过读所用物理卷来恢复状态,比如内存中的映射关系,但是数据量太多,过于耗时。所以设计了索引文件。
Haystack Store为每个卷都维护了索引文件,索引文件如上图6,以superblock,然后每个needle对应一个索引信息,这些索引信息是和物理卷的needle一 一对应。基于Table2,可以看出索引信息,其实能快速定位needle,所以本身也是内存映射的一种文件持久化方式,类似CHECKPOINT
索引文件本身是异步记录的,含义是当写一张照片,只保证照片持久化物理卷,就可以返回用户,而不必要同步的等待索引文件记录成功,只需要异步追加,这在尽量保证照片尽快上传成功的同时,也带来了一些问题,索引文件是异步的,可能存在脏记录。比如当删除一张照片,Haystack Store同步设置flag即可返回,保证写操作、删除操作尽快返回,但是存在如下bad cases:
1. needle没有相应的索引记录: 对于该场景,称之为orphans-孤儿,在Haystack Store重启后,会为这些孤儿创建一个匹配的索引信息,然后追加到索引文件。快速识别孤儿的方式也很简单,基于现有的索引文件最后一条记录,找到物理卷文件的记录(非孤儿),之后全是孤儿信息。Haystack Store通过索引文件即可初始内存映射。
2. 索引记录存在,但是没有体现是删除状态。对于该场景,Haystack Store读取到删除的needle(存在删除的flag),会更新相应的内存信息,并通知Haystack Cache这个照片不能找到
3.4.5 文件系统
Haystack使用RAID 6,并且底层文件系统使用性能更好的XFS
3.5 故障恢复
为了检测机器、硬件故障,设计了一个后台任务叫做pitch-fork,用户周期性检查每台Haystack Store机器的状态,具体方式如下:
- 检测是否连通过、检查每个卷文件的可用性,并尝试从Store机器读取数据
- 当认定一个Haystack Store存在异常,会将该机器所有逻辑卷标记为只读,再检查失败原因
- 如果发生故障的Store节点不可恢复,需要执行一个拷贝任务,从其他副本所在的存储节点拷贝丢失的物理卷轴的数据;由于物理卷轴一般很大,所以拷贝的过程会很长
3.6 一些优化
- 对于一些重复数据(比如照片多次修改)和标记删除的数据(照片被删除),通过Compaction来真正物理删除。Compaction操作,即将所有老数据文件中的数据扫描一遍,以保留最新一个照片的原则进行删除,并生成新的数据文件。因此Haystack Store采用延迟删除的回收策略,因为删除照片只是向卷轴中追加一个带有删除标记的Needle。
- 内存优化,主要是Haystack Store一些信息不需要内存维护,比如cookie等
- 批量上传,磁盘顺序写比随机写更快,因此系统会对批量上传做优化,比如用户上传多张照片或者整个相册

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)