k8s调度浅析
一、调度简介kube-scheduler是Kubernetes中的关键模块,扮演管家的角色遵从一套机制为Pod提供调度服务,例如基于资源的公平调度、调度Pod到指定节点、或者通信频繁的Pod调度到同一节点等。容器调度本身是一件比较复杂的事,因为要确保以下几个目标:公平性:在调度Pod时需要公平的进行决策,每个节点都有被分配资源的机会,调度器需要对不同节点的使用作出平衡决策。资源高效利用:最大化群集
一、调度简介
kube-scheduler是Kubernetes中的关键模块,扮演管家的角色遵从一套机制为Pod提供调度服务,例如基于资源的公平调度、调度Pod到指定节点、或者通信频繁的Pod调度到同一节点等。容器调度本身是一件比较复杂的事,因为要确保以下几个目标:
-
公平性:在调度Pod时需要公平的进行决策,每个节点都有被分配资源的机会,调度器需要对不同节点的使用作出平衡决策。
-
资源高效利用:最大化群集所有资源的利用率,使有限的CPU、内存等资源服务尽可能更多的Pod。
-
效率问题:能快速的完成对大批量Pod的调度工作,在集群规模扩增的情况下,依然保证调度过程的性能。
-
灵活性:在实际运作中,用户往往希望Pod的调度策略是可控的,从而处理大量复杂的实际问题。因此平台要允许多个调度器并行工作,同时支持自定义调度器。
二、调度流程
kube-scheduler的根本工作任务是根据各种调度算法将Pod绑定(bind)到最合适的工作节点,整个调度流程分为两个阶段:预选策略(Predicates)和优选策略(Priorities)。
-
预选(Predicates):输入是所有节点,输出是满足预选条件的节点。kube-scheduler根据预选策略过滤掉不满足策略的Nodes。例如,如果某节点的资源不足或者不满足预选策略的条件如“Node的label必须与Pod的Selector一致”时则无法通过预选。
-
优选(Priorities):输入是预选阶段筛选出的节点,优选会根据优先策略为通过预选的Nodes进行打分排名,选择得分最高的Node。例如,资源越富裕、负载越小的Node可能具有越高的排名。
通俗点说,调度的过程就是在回答两个问题:1. 候选有哪些?2. 其中最适合的是哪个?
值得一提的是,如果在预选阶段没有节点满足条件,Pod会一直处在Pending状态直到出现满足的节点,在此期间调度器会不断的进行重试。
调度器每次只调度一个pod资源对象,为每一个pod资源对象寻找合适节点的过程是一个调度周期
Kube-scheduler调度器在为pod资源对象选择合适的节点时,有以下两种最优解:
全局最优解:指每个调度周期都会遍历k8s集群中所有节点,以便找出最优节点(集群规模较小,几百台机器时使用)
局部最优解:指每个调度周期都只会遍历部分的k8s节点,找出局部最优解(集群规模较大时使用,比如5000台机器时使用)
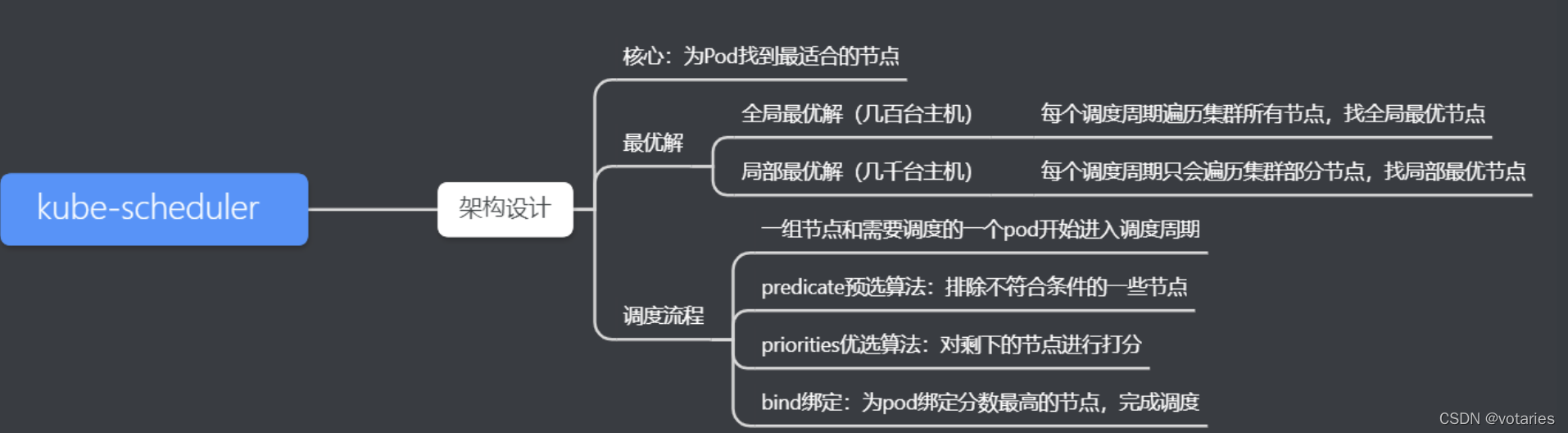
2.1 预选策略算法
CheckNodeConditionPred: 检查节点是否处于就绪状态
GeneralPred : 检查节点上的pod资源对象数量上限,以及CPU,内存,GPU等资源是否符合要求
CheckNodeMemoryPressure: 检查pod资源是否可以调度到可使用内存过低的节点上
PodToleratesNodeTaints:若当前节点被标记为Taints,检查pod资源对象是否能容忍Node Taints
MatchInterPodAffinity: 检查节点是否能满足pod的亲和性或反亲和性
CheckNodeLabelPresence: 检查指定的标签再上节点是否存在
除此之外还有基于存储卷的判断等策略
2.2 优选策略算法(Priorities)
优选过程会根据优选策略对每个候选节点进行打分,最终把Pod调度到分值最高的节点。kube-scheduler用一组优先级函数处理每个通过预选的节点,每个函数返回0-10 的分数,各个函数有不同权重,最终得分是所有优先级函数的加权和
-
LeastRequestedPriority(默认权重1):尽量将Pod调度到计算资源占用比较小的Node上
-
BalancedResourceAllocation(默认权重1):CPU和内存使用率越接近的节点权重越高。该策略均衡了节点CPU和内存的配比,尽量选择在部署Pod后各项资源更均衡的机器。该函数不能单独使用,必须和LeastRequestedPriority同时使用,因为如果请求的资源(CPU或者内存)大于节点的capacity(节点现有容量),那么该节点永远不会被调度到。
-
SelectorSpreadPriority(默认权重1):把属于同一个Service或者ReplicationController的Pod,尽量分散在不同的节点上,如果指定了区域,则尽量把Pod分散在该区域的不同节点。通常来说节点上已运行的Pod越少,节点分数越高。
-
NodeAffinityPriority(默认权重1):尽量调度到标签匹配Pod属性要求的节点
该函数提供两种选择器:requiredDuringSchedulingIgnoredDuringExecution(硬亲和)和preferredDuringSchedulingIgnoredDuringExecution(软亲和)。前者是强要求,指定将Pod调度到节点上必须满足的所有规则;后者是弱要求,即尽可能调度到满足特定限制的节点,但允许不满足。
-
TaintTolerationPriority(默认权重1):Pod与Node的排斥性判断。通过Pod的tolerationList与节点Taint进行匹配,配对失败的项越少得分越高,类似于Predicates策略中的PodToleratesNodeTaints。
-
ImageLocalityPriority(默认权重1):尽量调度到Pod所需镜像的节点。检查Node是否存在Pod所需镜像:如果不存在,返回0分;如果存在,则镜像越大得分越高。
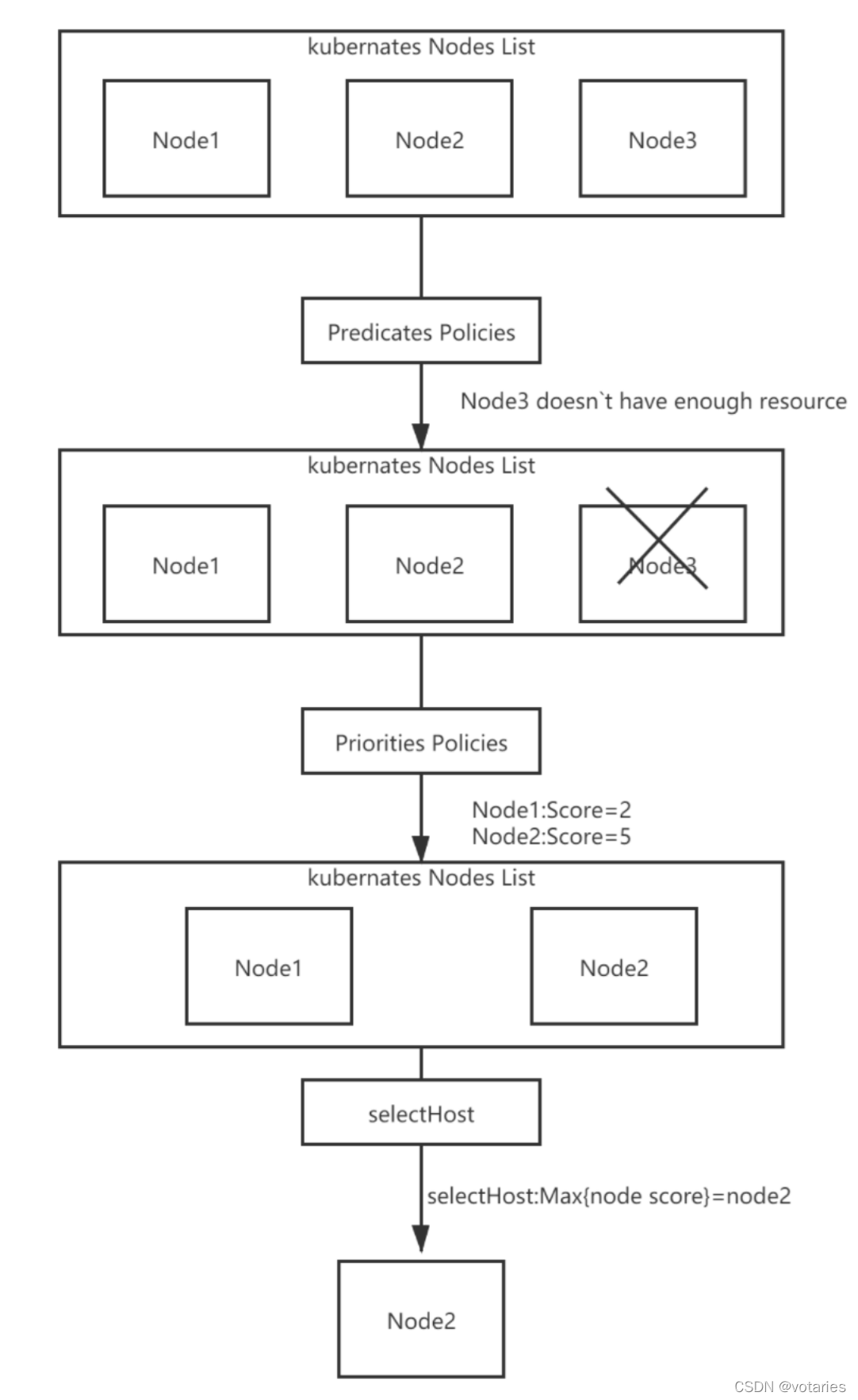
调度算法执行完成后,调度器就需要将 Pod 对象的 nodeName 字段的值,修改为k8s选择的node的名字。
2.3 调度时的资源需求
CPU:
requests: k8s调度pod时,会判断当前节点正在运行的Pod的CPU request的总和,再加上当前调度Pod的 CPU request ,计算 其是否超过节点的CPU的可分配资源
imits :配置cgroup以 限制资源上限
内存:
requests:判断节点的剩余内存是否满足pod的内存请求量,以确定是否可以将pod调度到该节点
limits :配置cgroup以限制资源上限
kc get deployment saber-saber-qturq -n medusa -o yaml
kc get node g1-med-online1-120 -o yaml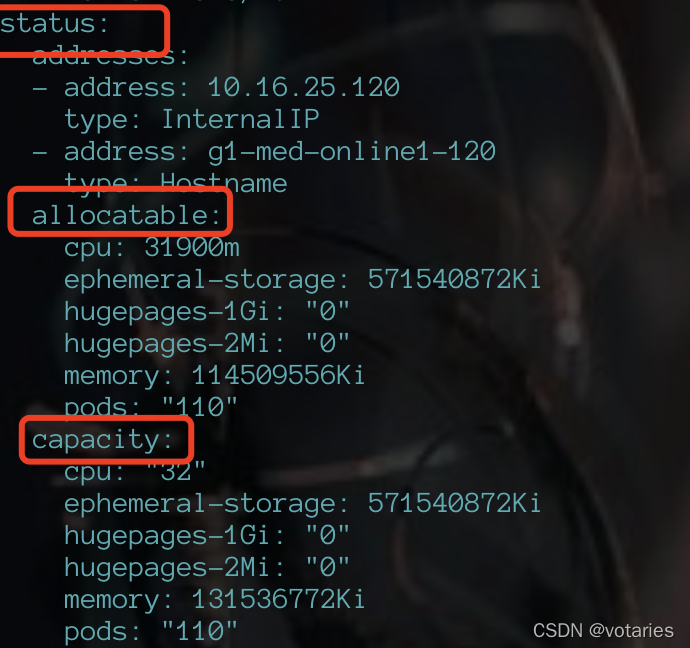
allocatable:节点可分配资源
capacity:节点一共有这些资源 去除不能分配的资源就是allocatable
limits:应用最多只能用这么多资源
requests :调度器调度时参考的值,一个应用至少需要这么多资源才能起来 调度的时候只看这个部分,调度后,节点会把这部分资源从节点剩余资源中扣除掉
2. 4 QoS
QoS(Quality of Service),大部分译为 “服务质量等级”,又译作 “服务质量保证”,是作用在 Pod 上的一个配置,当k8s创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级,可以是以下等级之一:
Guaranteed:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。如果一个容器只指明limit而未设定request,则request的值等于limit值。
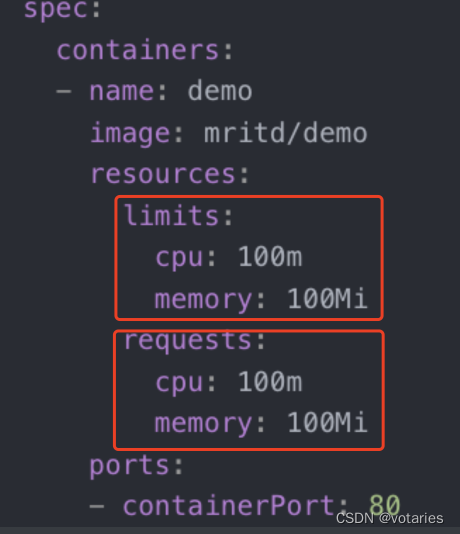
Burstable:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
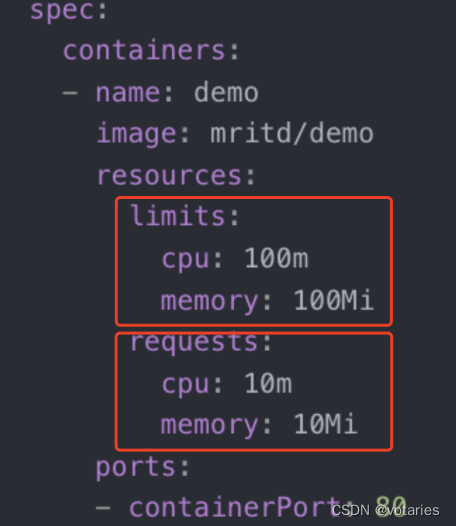
BestEffort:容器必须没有任何内存或者 CPU 的限制或请求。
QoS 优先级:三种 QoS 优先级,从高到低(从左往右) Guaranteed --> Burstable --> BestEffort
Kubernetes 资源回收策略:当集群监控到 node 节点内存或者CPU资源耗尽时,为了保护node正常工作,就会启动资源回收策略,通过驱逐节点上Pod来减少资源占用。
三种 QoS 策略被驱逐优先级,从高到低(从左往右)BestEffort --> Burstable --> Guaranteed
使用建议:关键业务,可将pod QoS 设置为 Guaranteed
非关键业务,可pod QoS 设置为 Burstable 或者 BestEffort
三、kube-scheduler组件启动流程
3.1 kube-scheduler组件启动流程
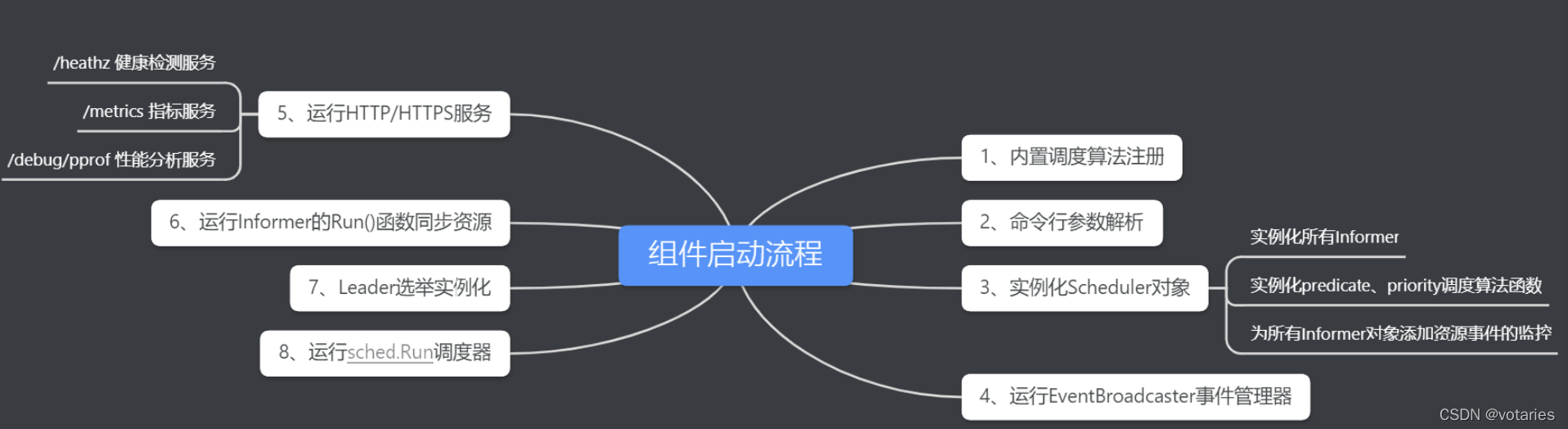
3.1.1 内置调度算法的注册
在 createFromProvider 函数中调用 algorithmprovider.NewRegistry() 注册调度器算法插件:
func (c *Configurator) createFromProvider(providerName string) (*Scheduler, error) {
klog.V(2).Infof("Creating scheduler from algorithm provider '%v'", providerName)
...........
r := algorithmprovider.NewRegistry()
.........
return c.create()
}algorithmprovider.NewRegistry( ) 函数调用了 getDefaultConfig() 获取默认调度算法,将其注册。
func getDefaultConfig() *schedulerapi.Plugins {
return &schedulerapi.Plugins{
QueueSort: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: queuesort.Name},
},
},
....................
//预选算法插件列表
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
},
},
............
//优选算法插件列表
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},
·········
}
}
3.1.2 Cobra 命令行参数解析
Cobra是k8s系统中统一的命令行参数解析库,所有的k8s组件都适用Cobra来解析命令行参数
Kube-scheduler组件通过Cobra填充Options配置参数默认值并验证参数
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
//初始化命令行默认配置
opts, err := options.NewOptions()
...
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: ...
Run: func(cmd *cobra.Command, args []string) {
// runCommand 函数对命令行的命令、参数进行解析、校验
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
...
return cmd
}\
// runCommand 函数对命令行的命令、参数进行解析、校验
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
verflag.PrintAndExitIfRequested()
cliflag.PrintFlags(cmd.Flags())
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
//cc(kube-scheduler 组件的运行配置)
cc, sched, err := Setup(ctx, opts, registryOptions...)
...
//运行 Run 函数,启动 kube-scheduler 组件
//Run函数定义了kube-scheduler组件启动的逻辑,它是一个运行不退出的常驻进程
return Run(ctx, cc, sched)
}
至此,完成了kube-scheduler组件启动启动之前的环境配置
3.1.3 实例化 Scheduler 对象
Scheduler对象是运行kube-scheduler组件的主对象,它包含了kube-scheduler组件运行过程中所有依赖模块的对象。
Scheduler对象实例化的过程可分为三部分
1.实例化所有的Informer
kube-scheduler组件依赖于多个资源的Informer 对象,用于监控相应资源对象的事件。例如:通过podInformer监控pod资源对象,当某个pod被创建时,kube-scheduler组件监控到该事件,并为该pod根据调度算法选择出合适的节点
2.实例化调度算法函数
在3.3.1中,内置调度算法的注册过程中只注册了调度算法的名称,在这一步,为已经注册名称的调度算法实例化对应的调度算法函数
3.为所有Informer 对象添加资源事件的监控
addAllEventHandlers()函数为所有的Informer对象添加对资源事件的监控并设置回调函数,
举个例子:podInformer对象监控pod资源对象,当pod触发Add、Update、Delete事件时,触发对应的回调函数,在触发Add事件后,podInformer将其放入SchedulingQueue调度队列中,等待kube-scheduler调度器为该pod资源对象分配节点
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
...
// 1、实例化所有 Informer
configurator := &Configurator{
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
}
...
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// 2、实例化调度算法
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
...
}
...
// 3、为所有 Informer 对象添加对资源事件的监控
addAllEventHandlers(sched, informerFactory)
return sched, nil
}3.1.4 运行 EventBroadcaster 事件管理器
Event(事件)作为 Kubernetes 的一种资源对象,用于描述集群产生的事件。如 kube-scheduler 组件在调度过程中,对某个 Pod 的调度做了什么处理、为什么需要对某些 Pod 做驱逐等决策都通过向 apiserver 请求创建 Event 记录下来,新创建的 Event 默认保留1个小时。
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// 运行 EventBroadcaster
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
...
return fmt.Errorf("finished without leader elect")
}3.1.5 运行 HTTP 或 HTTPS 服务
kube-scheduler 中提供了三个 HTTP 服务:健康检测、指标监控、pprof 性能分析。分别对应 /healthz、/metrics、/debug/pprof 三个接口。
/healthz:用于健康检查
/metrics:用于监控指标
/debug/pprof :用于pprof性能分析
3.1.6 运行 Informer 同步资源
在3.1.3中实例化好了所有的Informer 对象,在这一步需要将它们运行起来。
通过Informer监控nodeInformer、podInformer、RCInformer·······资源
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// 运行所有 Informer
cc.InformerFactory.Start(ctx.Done())
// 等待所有 Informer 缓存同步完成
cc.InformerFactory.WaitForCacheSync(ctx.Done())
...
return fmt.Errorf("finished without leader elect")
}3.1.7领导者选举实例化
Kubernetes 中 controller-manager 和 kube-scheduler 组件都有 Leader 选举机制,通过选主来实现分布式系统的高可用。
其实现原理是通过定义回调函数 leaderelection.LeaderCallbacks 中的 OnStartedLeading 和 OnStoppedLeading 来回调通知当前节点的 kube-scheduler 组件是否竞争 Leader 成功 OnStartedLeading 函数是当前节点领导者选举成功后的回调函数,调用其表示选举成功。该函数定义了 kube-scheduler 的主逻辑
OnStoppedLeading 函数是当前节点领导者被抢占后回调的函数,调用其表示选举失败。在领导者被抢占后,会退出当前的 kube-scheduler进程
//本函数会一直尝试使节点成为领导者
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// 判断是否开启选举
if cc.LeaderElection != nil {
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: sched.Run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
// 开启新一轮选举
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
...
return fmt.Errorf("finished without leader elect")
}3.1.8 运行 sched.Run 调度器
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// 运行调度器
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}四、优先级与抢占机制
当前的k8s系统中,Pod资源对象支持优先级(Priority)与抢占(Preempt)机制,当 kube-scheduler调度器运行时。根据pod资源对象的优先级进行调度,高优先级的pod资源对象排在调度队列的(SchedulingQueue)的前面,优先获得合适的node,然后再为低优先级的pod选择合适的节点。
当高优先级的pod资源对象没有找到合适的节点时,调度器会尝试抢占低优先级的pod资源对象的节点,抢占过程是将低优先级pod资源对象从所在节点上驱逐走,使高优先级的pod资源对象运行在该节点上,被驱逐走的低优先级pod会重新进入调度队列并等待再次选择合适的节点。
当集群面对资源短缺的压力时,高优先级的pod将依赖于调度程序抢占低优先级pod的方式进行调度,这样可以优先保证高优先级的业务运行。
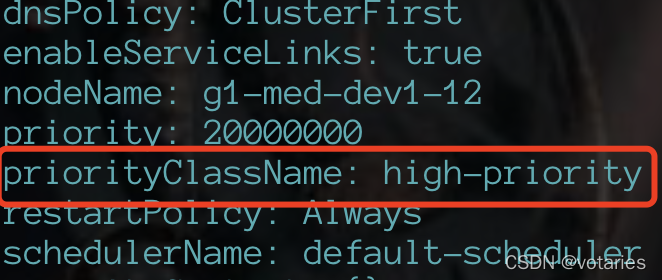
在默认情况下,若不启用优先级功能,则现有pod资源对象的优先级都为0,通过定义PriorityClass对象设置优先级
定义PriorityClass对象:
apiVersion: scheduling.k8s.io/v1alpha1
kind: PriorityClass
metadata:
name: high-priority
value: 2000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."使用:
在pod yaml中添加字段
五、亲和性调度
通过亲和性调度,可以将需要依赖GPU硬件资源的pod对象分配到具有GPU硬件资源的节点。如果两个业务联系的很紧密,则可以将这两个业务的pod调度到同一个节点上,以减少网络传输带来的损耗
开发者需要在这些节点上打上相应的标签,调度器可以通过标签来进行资源对象的调度,这种调度策略被称为亲和性和反亲和性调度。
pod资源对象目前支持两种亲和性和一种反亲和性
NodeAffinity:节点亲和性,pod资源对象与节点之前的关系亲和性
podAffinity:pod资源对象的亲和性,pod与pod之间亲和
podAntiAffinity:pod对象的反亲和性,pod与pod之间反亲和
注意:pod亲和性需要大量逻辑处理,在大型k8s集群中使用会大大降低调度性能,在大于数百个节点的集群中不建议使用
5.1 nodeAffinity
nodeAffinity(节点亲和性)将某个pod资源对象调度到指定的节点上,比如调度到指定机房,调度到具有GPU资源的节点上,调度到I/O密集型的节点上等场景
nodeAffinty支持两种调度策略
requiredDuringSchedulingIgnoredDuringExecution(硬亲和):pod资源对象必须被部署到满足条件的节点上,如果没有满足条件的节点,则pod资源对象创建失败并不断重试。
preferredDuringSchedulingIgnoredDuringExecution(软亲和):pod资源被优先部署到满足条件的节点上,如果没有满足条件的节点,则从其他节点中选择较优的节点
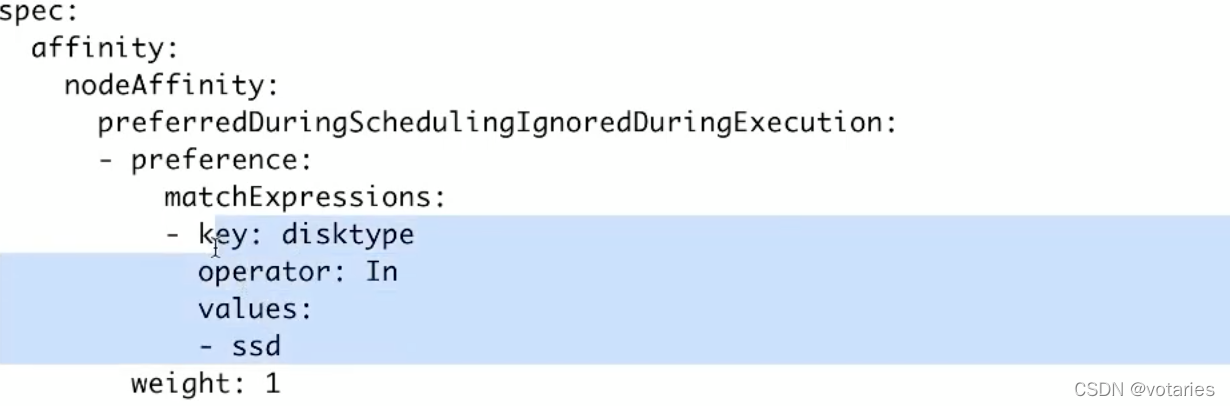
注意:在pod资源对象被调度并运行后,如果标签发生了变化,不再满足pod资源对象指定的条件,此时已经运行在node上的pod还会继续运行在当前节点上()
5.2 podAffinity
podAffinity(pod亲和性)将某个pod资源对象调度到与另一个pod相邻的位置,例如调度到同一主机,调度到同一硬件集群,调度到同一机房 以缩短网络传输延时
podAffinity支持两种调度策略
requiredDuringSchedulingIgnoredDuringExecution(硬亲和):Pod必须被部署到满足条件的节点上(与另一个pod相邻)如果没有满足条件的节点,则pod资源对象创建失败并不断重试。
preferredDuringSchedulingIgnoredDuringExecution(软亲和):pod资源被优先部署到满足条件的节点上(与另一个pod相邻),如果没有满足条件的节点,则从其他节点中选择较优的节点。

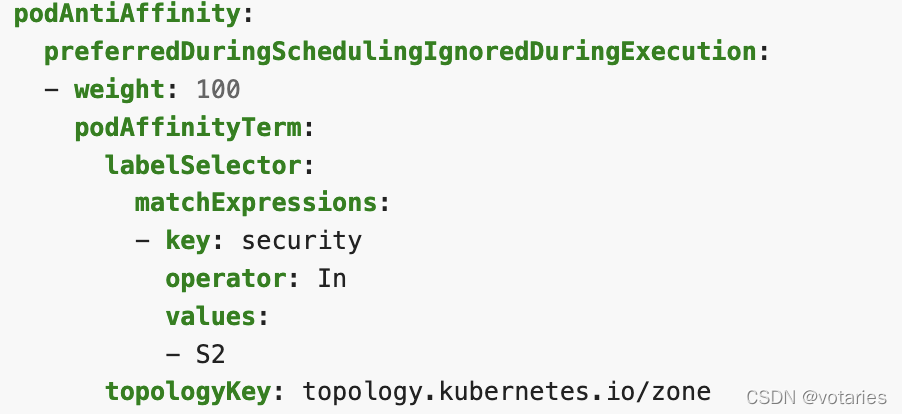
5.3 podAntiAffinity
pod反亲和,一般用于容灾,讲一个pod资源对象的多副本实例调度到不同节点上,调度到不同的硬件集群上
requiredDuringSchedulingIgnoredDuringExecution(硬亲和):Pod必须被部署到满足条件的节点上(与另一个pod资源对象互斥)如果没有满足条件的节点,则pod资源对象创建失败并不断重试。
preferredDuringSchedulingIgnoredDuringExecution(软亲和):pod资源被优先部署到满足条件的节点上(与另一个pod资源对象互斥),如果没有满足条件的节点,则从其他节点中选择较优的节点。
六、污点与容忍
节点亲和性是 Pod的一种属性,它使 Pod 被吸引到一类特定的节点(这可能出于一种偏好,也可能是硬性要求)。
污点(Taint)则相反,它使节点能够排斥一类特定的 Pod。
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。
6.1 污点
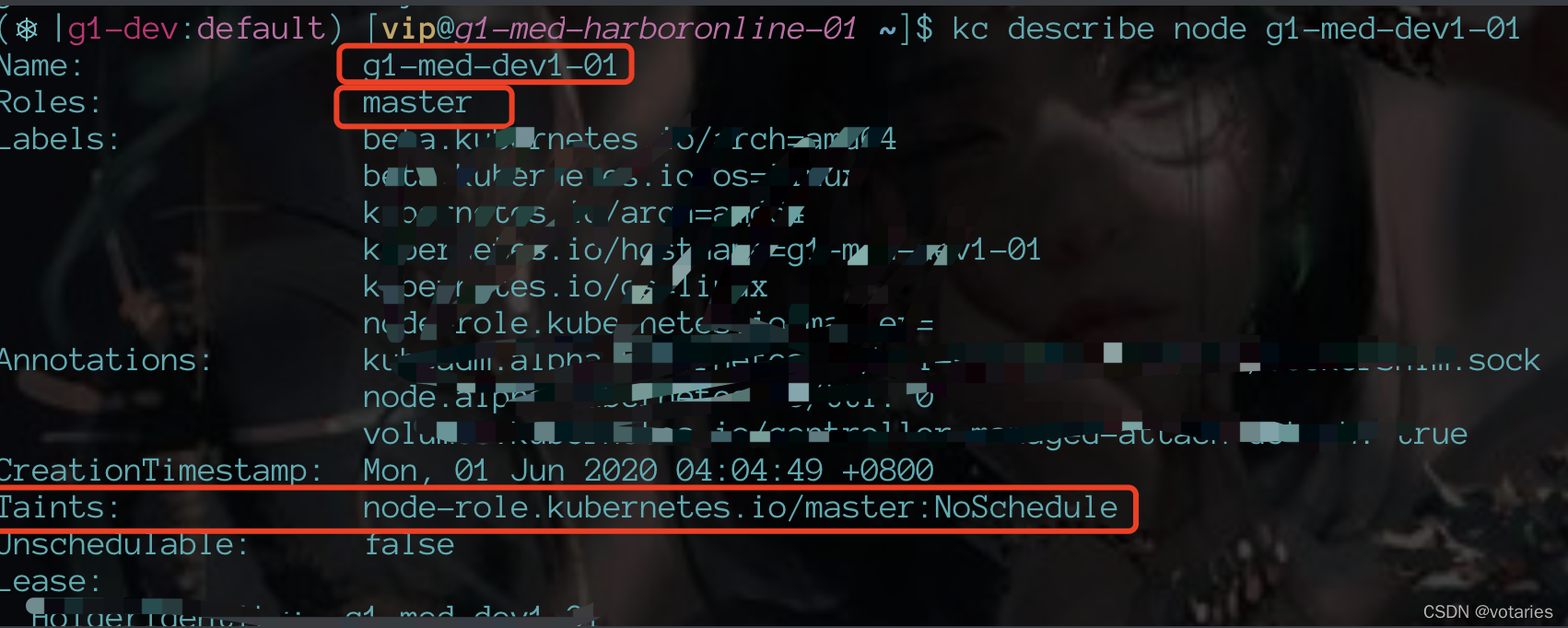
给节点添加污点
kubectl taint nodes node1 key1=value1:NoSchedule每个污点有一个key和value作为污点的标签,其中value可以为空,effect描述污点的作用。当前taint effect支持如下三个选项:
-
NoSchedule:不能容忍此污点的新
Pod对象不可调度至当前节点,属于强制型约束关系,节点上现存的Pod对象不受影响。 -
PreferNoSchedule:
NoSchedule的柔性约束版本,即不能容忍此污点的新Pod对象尽量不要调度至当前节点,不过无其他节点可供调度时也允许接受相应的Pod对象。节点上现存的Pod对象不受影响。 -
NoExecute:不能容忍此污点的新
Pod对象不可调度至当前节点,属于强制型约束关系,而且节点上现存的Pod对象因节点污点变动或Pod容忍度变动而不再满足匹配规则时,Pod对象将被驱逐。

6.2 容忍
举个例子:
假设给一个节点添加了如下污点
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule假定有一个 Pod,它有两个容忍度:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"在这种情况下,上述 Pod 不会被分配到上述节点,因为其没有容忍度和第三个污点相匹配。 但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上。
七、举几个例子
例1:只允许调度到CentOS节点**(亲和性)**
某系统中有各种异构系统机器,比如SLES、RHEL、CentOS7.2、CentOS7.3等,现在有一个线上任务只能运行在CentOS系统,但是不区分CentOS系统版本。用NodeAffinityPriority解决。
我们在该服务的YAML文件中将NodeAffinityPriority选择器的指定为requiredDuringSchedulingIgnoredDuringExecution,表示强要求,指定Pod必须被调度到key为“operation system”,值为“centos 7.2”或“centos 7.3”的节点。
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: operation system
operator: In
values:
- centos 7.2
- centos 7.3如果需要优先调度到CentOS 7.2的节点,还可以增加一个由preferredDuringSchedulingIgnoredDuringExecution决定的调度策略,优先调度到具有“another-node-label-key-system”标签,且值为“another-node-label-value-centos7.2”的节点。
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key-system
operator: In
values:
- another-node-label-value-centos7.2apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: operation system
operator: In
values:
- centos 7.2
- centos 7.3
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1 /// 0~100 计入评分
preference:
matchExpressions:
- key: another-node-label-key-system
operator: In
values:
- another-node-label-value-centos7.2
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0例2:
私有云服务中,某业务使用GPU进行大规模并行计算。为保证性能,希望确保该业务对服务器的专属性,避免将普通业务调度到部署**GPU的服务器。**
-
该场景要求Pod避免被调度到指定类型的节点,符合排斥关系,故可用策略PodToleratesNodeTaints解决。
首先先在配有GPU的node1中添加Taints污点(gpu = true),NoSchedule表示只要没有对应Toleration的Pod就不允许调度到该节点。
kubectl taint nodes nodes1 gpu=true:NoSchedule同时,通过更新服务的YAML文件,为需要GPU资源业务的Pods添加Toleration(key: "gpu",value: "true"),表示容忍GPU服务器的Taints,这样就可以把指定业务调度到GPU服务器,同时把普通服务调度到其他节点。
apiVersion: v1
kind: Pod
metadata:
generateName: redis-
labels:
app: redis
namespace: default
spec:
containers:
- image: 172.16.1.41:5000/redis
imagePullPolicy: Always
name: redis
schedulerName: default-scheduler
tolerations:
- effect: NoSchedule
key: gpu
operator: Equal
value: truetolerations里的effect字段表示处理排斥的策略,支持三种调度规则:NoSchedule表示不允许调度,已调度的不影响;PreferNoSchedule表示尽量不调度;NoExecute表示不允许调度,已运行的Pod将在之后删除。
此外,固定节点也有以下的做法可以实现
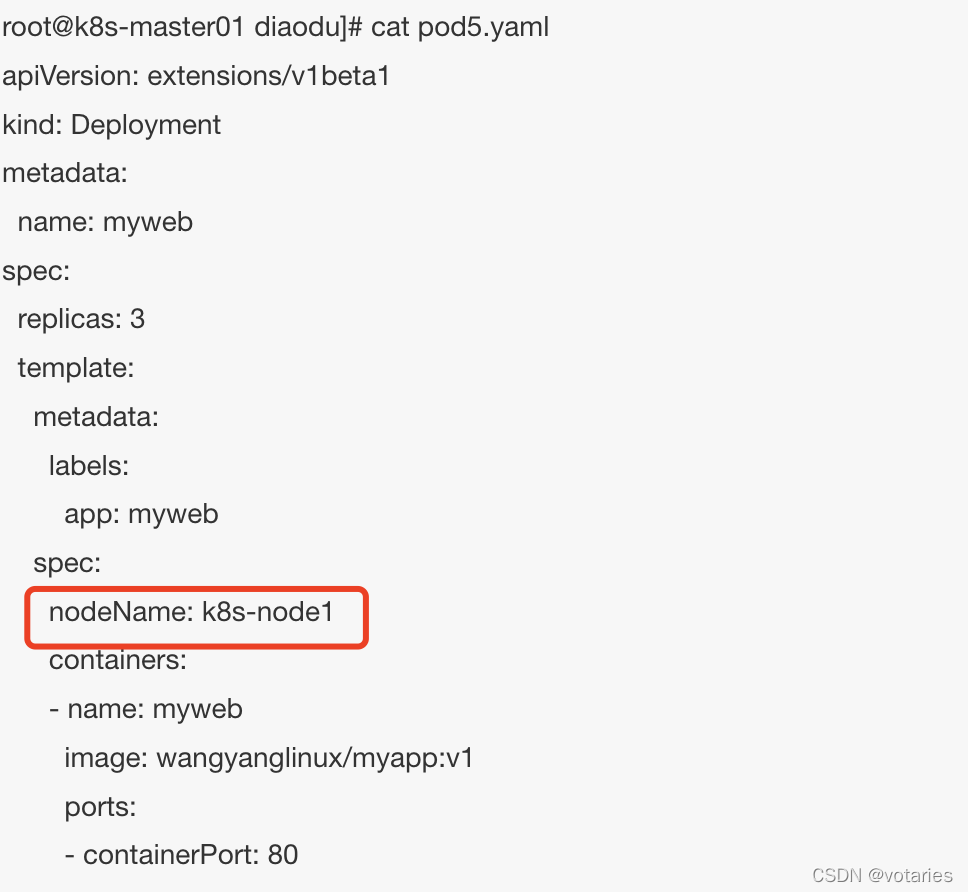
固定单节点
根据node节点的主机名选择 Pod.spec.nodeName 将 Pod 直接调度到指定的 Node 节点上,会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
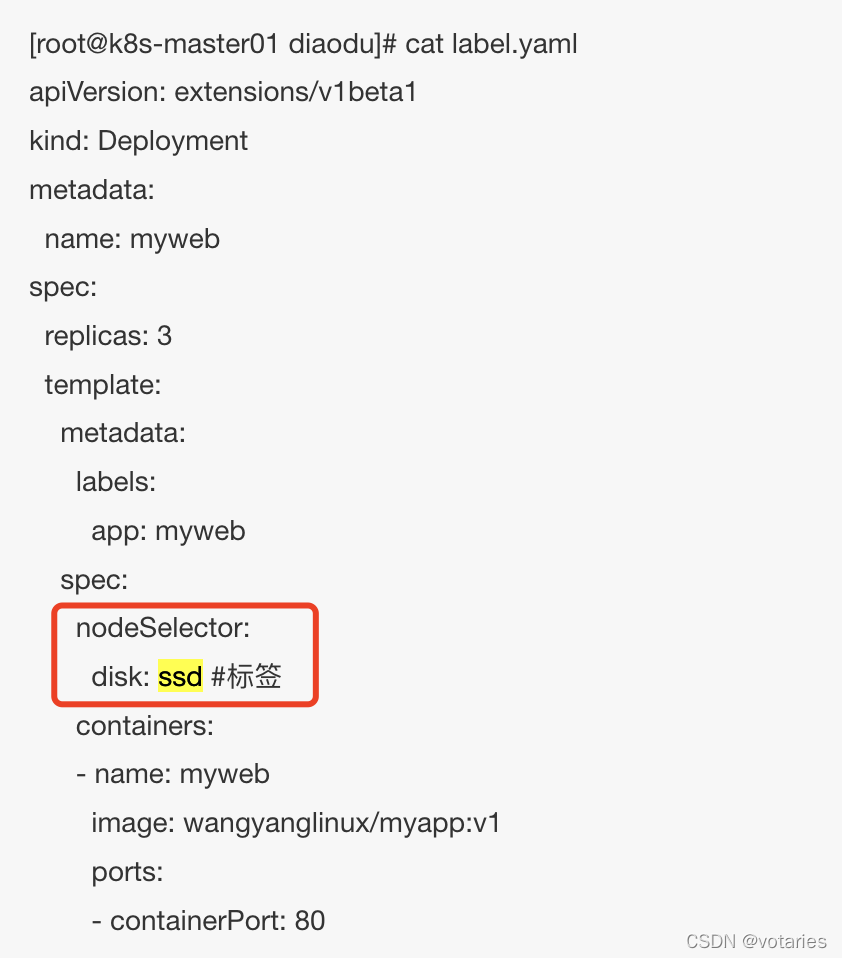
固定几个节点
![]()

开源、云原生的融合云平台
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)