
从0了解矩阵——矩阵的本质
矩阵是大学线性代数课程里的内容,当时学的时候虽然一头雾水,不过,牵扯到的问题基本上都是一些加减乘除,所以,我的线性代数课程倒是拿了不错的成绩。虽然分数考得不错,但是,直到毕业后很多年,我都不知道,矩阵这个东西究竟是干什么用的?一堆数字排成矩形,到底有什么用?
其实,我的脑子里一直都有非常多的问题,所以,我非常喜欢去图书馆或者书店之类的地方,试图在茫茫书海里去寻找脑海里那些不怎么确定的问题答案。
你可能会问,为什么不上网查?
我查过,除了查到一堆看似高深、而且完全看不懂的内容之外,就是一些“很厉害”的网友复制粘贴的一些内容。所以,我一直认为,学者把自己的东西写成书籍,才能让人信服。
而且我通过这样的方式也确实解决了一些脑海里的疑问,其中,就包括“矩阵究竟是什么”这样的问题。
你问我什么书?
是一本外国大佬写的3D游戏引擎的书籍,书名就不说了,免得有XX嫌疑。
接下来,就请你跟着我的思路一起,来看一看矩阵究竟是什么吧!
在这里,我先假定你有初中数学的水平。
一、矩阵是什么样子的?
从表面上看,矩阵是一个由多个数字组合起来的方阵,比如说下面这个样子:

从这里我们看出矩阵的基本特征:
1.“矩”的意思是矩形,由数字组成的矩形;
2.“阵”的意思是整齐,这些数字排列起来是非常整齐的,并不会歪歪扭扭;
3.矩阵中,横向的数字是行,竖向的数字是列,行和列都是整数,可以是1或者是n(n是整数);
4.矩阵中,通过“第几行、第几列”这种简便的方式来确定某个数字的具体位置。
以上面这个矩阵为例。它是一个3行×3列的矩阵,数字“1”在第1行第1列,数字“9”在第2行第2列,数字“8”在第3行第2列。
知道矩阵长什么样子后,你可能就会有一个疑问:把数字弄成这个样子,有什么作用?
二、矩阵的由来
你别急,我们一点一点慢慢来讲。
矩阵是一个数学问题,而一提到数学,很多人的第一反应就两个字——不懂。
说到底,数学就是1+1的科学,本就是从生活中提炼出来的,到底是什么原因,让数学越发展越让人看不懂呢?
这个问题比较复杂,但我个人的理解是——越发展越深奥的关键点,在于代数的发明。
什么意思呢?
也就是用x这样的未知数来代替计算。
比方有这么一个简单的问题:
我知道一个人1小时可以走2公里,那么,现在他走了10公里,请问他走了几个小时?
这是一个小学生的数学问题,我们很容易就知道他走了5个小时,这是一个很简单的问题。
好了,我再看一个复杂一些的问题:
小明想在花园里养一些鸭子和小狗,于是就去市场买。小鸭子是3块钱一只,小狗是7块钱一只,小明一共花了59块钱;小明数了一下,鸭子和小狗一共有44条腿。那么,你知道小明一共买了多少只鸭子?多少只小狗吗?
如果我们只用小学数学来解决这个问题,是有点烧脑的,因为这个题目中有两个未知数,很多人的脑袋是转不过弯来的。但是,这种题目一用到代数就非常简单了。我们只要设鸭子的数量为x,小狗的数量为y,就可以列出如下的方程:

然后这个问题就很好解决了。
一般的人看到问题解决了,就不会继续思考了,但是对数学家来说,他们看问题的角度和我们是很不一样的。
数学家看到上面这个二元一次方程(初中数学知识)的时候,就会联想到一元一次方程。为了继续说明这个问题,我们把第一个走路的数学问题也用代数的方式列一个方程。设他走了x个小时才走了10公里,那么,可以列出如下的方程来:

作为一个数学家,自然而然就会想到,有没有什么方法,可以把二元一次方程弄得和一元一次方程一样简单,然后解起来也很方便呢?
这就是矩阵的雏形。
数学家发现,这个二元一次方程可以分解成3个部分:
第一部分,是代数x、y左边的系数;
第二部分,是代数x、y本身;
第三部分,是等号右边的数字。
然后,数学家惊奇地发现,一元一次方程也是3个部分:
第一部分,代数x左边的系数;
第二部分,代数x本身;
第三部分,是等号右边的数字。
数学家类比一元一次方程的3个部分,将二元一次方程的3个部分分别提取出来,按照它们原先的排列组合列成了数字组合。
我们用上面的这个二元一次方程来做例子,第一部分是代数左边的系数,按照它们原先的位置顺序,写成了如下的样子:

第二部分是代数本身,它们是上下组合的,所以写成下面这个样子:
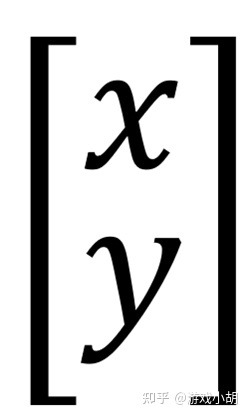
第三部分类似第二部分,我们把它写成这个样子:

然后,数学家类比一元一次方程的样子,把这三个部分组合了起来:

你看,是不是和一元一次方程非常像?
这就是矩阵被创造出来的大致过程了。
三、探究矩阵的乘法
方程写出来了,那怎么计算呢?
10除以2很明显是5,那这个右边一坨除以左边一坨,是个什么玩意儿?
所以,我们还得探究一下矩阵的乘法计算过程。
我们先观察一下上面刚刚写出来的矩阵和原本方程的有什么相通的地方:

你发现了什么?
你可以思考一下,为了可以更容易观察,我们把矩阵等式做个小小的变化,就是把二元一次方程的等式代入矩阵等式的右边:

然后,这个乘法的过程是不是一目了然了呢?
首先看等式右边第一行,它是等式左边第一项的第一行和第二项的第一列的数字分别相乘相加;然后是右边第二行,是左边第一项第二行和第二项第一列的数字分别相乘相加。用图示的话,是这样表示的:
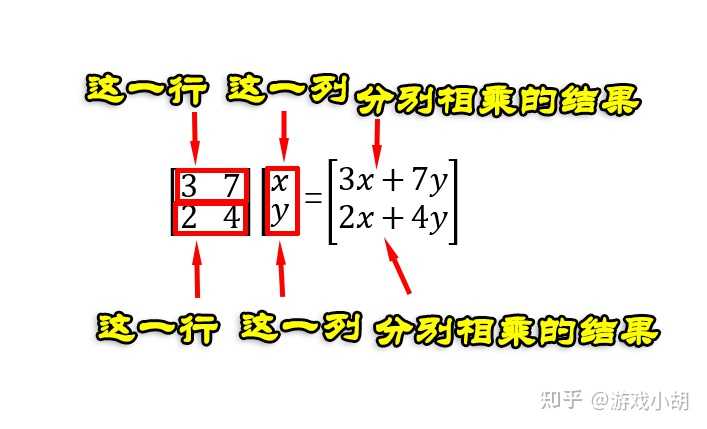
数学家们从这个简单的例子中总结了如下2个关于矩阵相乘的规律:
1.第一个矩阵的列数必须和第二个矩形的行数相等,才能相乘。
我们用
数字1×数字2
的形式来表示一个矩阵的行列属性,那么,只有m×n的矩阵和n×l的矩阵才可以相乘,最后会得到一个m×l的矩阵。
就拿我们上面的矩阵为例,左边是一个2×2的矩阵,右边是一个2×1的矩阵,那么相乘之后,就会得到一个2×1的矩阵。
2.矩阵相乘不满足交换律。
道理非常简单,矩阵A×矩阵B可能是合法的,但矩阵B×矩阵A可能就没有意义。比方说,矩阵A是4×2的矩阵,而矩阵B是2×3的矩阵,A×B满足上面的要求,而B×A就无法解释了,因为3和4明显不一样。
四、关于单位矩阵
因为有了矩阵,复杂的多元方程就可以简化成和一元一次方程一样。由于两者很像,数学家就会想,一元一次方程中有一个特殊的系数“1”,那矩阵中有没有类似的呢?
不研究不知道,一研究就发现还真有。数字1的唯一特点,就是和任何数相乘不会改变它们的值。相似的,矩阵中的“1”也应该有这样的功能,和其他矩阵相乘不会改变其他矩阵。
单位矩阵可以推导出来。还是用上面的例子,就是下面这个矩阵乘法:
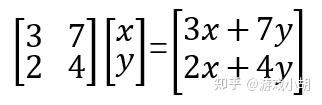
如何让右边的多项式等于x或者是y呢?很简单,把3改成1,把7改成0,再把2改成0,把4改成1,然后,等号右边的矩阵就是x和y的矩阵了。

把这些改变套回左边第一个矩阵,这个矩阵就变成下面这个样子了:

经过数学家们长期的研究发现,所有的单位矩阵都有如下2个特点:
1.是正方形矩阵;
2.除了左对角线上的数字是1之外,剩下的数字全部是0,下面图中就是一个单位矩阵了。单位矩阵一般用大写的粗体I来表示。

我想,我应该说明白了吧?
这个问题还有后一部分,矩阵有什么用?
确实,如果矩阵发明出来只是为了方便解方程的,那就不算什么。矩阵之所以“强大”,主要还是因为矩阵的实际应用。
矩阵在其他方面有什么应用我不太了解,不过,矩阵在计算机图形学,尤其是3D图形计算中的作用是极大的。
所以,我打算从计算机角度来说一说矩阵的应用。
如果你认真看了上面的内容,就能知道关于矩阵的两个重要知识点:矩阵的由来和矩阵的乘法。
这个时候,你的脑子里估计有个疑问:矩阵只不过是数学家换一种方法来解方程的“戏法”罢了,具体有什么作用呢?
如果这个世界上没有电脑,我们还停留在用纸和笔计算的时代,那矩阵可能真的就没什么太大的用处了。在大多数人的眼中,矩阵除了可以快速解多元一次方程外,没有其他任何用处。说真的,在现实生活中,我们用到矩阵的地方也非常非常少。
我一直把某一个道理信奉为真理:如果你觉得某个问题难以解决,不妨好好去学一学数学,没准儿,数学家在好几百年前就已经有了解决方法了。
矩阵就是这样,当时被发明出来的时候很多人并不理解,一个快速计算方法有什么用?直到有了计算机,直到程序员在处理计算机3D问题时遇到了非常大困难的时候,计算机前辈才发现矩阵的真正用处——它能大大提高3D问题中复杂计算的效率。
打个比方你就明白了。在电脑上运行3D程序,就好比是在路上开车。而矩阵,就相当于是一个额外的氮气加速器。假设,在没有矩阵的情况下,车子只能开10码,那么,有了矩阵之后,车子就能开到200码的样子了。
在程序员使用矩阵之前,他们也不知道计算机在处理矩阵的时候那么给力,所以,这应该算是一个意外之喜吧?
这里顺带插一句,聊一聊一个小故事。
你可能觉得,计算机3D图形使用矩阵是比较晚的事情,起码要到2000年吧?
其实不是的,在80年代初,那个时候电脑的CPU还是8位的(现在CPU普遍64位),电脑内存可能才1~2M(你没看错,和现在动不动16G内存比起来,是不是少得可怜?),在这种“低配置”的情况下,3D游戏已经开始发展了。
当时有很多厉害的程序员前辈在写3D游戏程序,其中有一个叫做Space Duel的3D游戏程序让其他的程序员叹为观止!原因就是这个游戏程序在8位计算机上表现出了非常惊人的运行效率!
为什么?
据当时的内部人员透露,这个3D游戏程序使用了矩阵来进行了3D图形运算。(没错,这些内容都是我看书才知道的)
好了,大致了解了简单的内容之后,我们就来看一看矩阵在3D游戏编程中到底是怎么用吧。
一、虚拟3D中的数学计算操作
首先,我们简单了解一下游戏中的3D世界。
第一步,我们要在一个虚拟的3D坐标系中构建3D世界;
第二步,我们把各种各样的虚拟3D物体(建模得到的)加入到这个虚拟世界中;
第三步,就是用虚拟摄像机把虚拟3D场景拍摄下来。
这个过程中,第二步和第三步都牵扯到了大量的数学计算。
举个小栗子,你就知道有多少计算过程了。
假设,我要在虚拟3D世界中放置一辆小汽车,然后显示在电脑屏幕上,计算机在背后的操作过程大致如下。
①先确定虚拟3D世界的坐标系,一般的,我们会采用左手系,也就是屏幕中心为坐标原点,右方向是X轴正向,上方向是Y轴正向,垂直屏幕朝里是Z轴正向。
②小汽车放在虚拟3D世界中,总得有个位置吧?也就是位置信息,计算机根据位置信息把这辆小汽车加入到场景中,需要进行大量的数学计算。
③小汽车在三维软件(比如3dmax)中建模的时候,是最大化建模的,各个细节都会画出来,但是,我们在虚拟3D世界中不一定要显示得那么大,也就是说,小汽车需要按照设计者预定的大小进行缩放,这个过程,也需要进行大量的数学计算。
④同理,小汽车在三维软件中创建的时候,可能是按照正面的视角来创建的,如果我们直接这样放进去,小汽车可能一直都是车头对着我们,所以,我们还需要把小汽车按照一定的角度进行旋转,这样,小汽车才能正确放置在虚拟3D世界的公路上面,这个过程,更需要进行大量的数学计算。
⑤小汽车不可能不动吧?这个程序或者是游戏的主角就是小汽车,那么,小汽车需要移动、转弯、加速等等,就是说,使用者在操控小汽车的时候,也需要对小汽车进行移动、旋转、缩放的操作,这也需要大量的数学计算。
⑥你以为这就完了吗?这一系列操作过后,小汽车的确正确地放在了虚拟3D世界中,可是,我们看不到啊!因为我们的电脑屏幕是二维的,二维屏幕只有x、y两个维度的坐标,怎么可能直接显示三维的东西呢?所以,三维世界要显示在二维屏幕上,需要进行投影操作,也就是把3D世界中的所有内容都投影到一个平面上。这个过程想想就复杂,就会需要更多的数学计算!
总之,要在屏幕上把一辆3D小汽车正确地显示出来,耗费的数学计算量是无法想象的!
那么,有没有解决办法呢?
有,答案就是矩阵。
好,我们先喘口气。
……
好了吗?
如果你只是想简单知道矩阵是干什么的,了解到上面就足够了。而我本人比较喜欢刨根问底,所以,接下来的内容可能有那么一点点复杂。
我们继续。
仔细分析一下上面的①~⑥的过程,我们很容易就能总结出来,3D小汽车在虚拟3D世界中只会进行4种操作:
a:小汽车位置的移动;
b:小汽车的旋转;
c:小汽车的缩放;
d:小汽车的投影。
而这4个操作在3D图形学中有专有的名词,分别叫做平移、旋转、缩放和投影。
如果没有矩阵的话,每一种基本的操作都会牵扯到巨量(看清楚,不是大量,是巨量)的数学计算。因为,任意的3D模型都是由最基本的三角形组成的,而一辆小汽车,可能有成百上千个三角形组成。拿最简单的平移操作来讲,要移动小汽车,实际上移动的是这成百上千的三角形!也就是说,每个三角形都需要进行一遍相同的数学加减乘除操作,这个计算量不用我说,你也应该知道很大。
然而,如果把数学计算用矩阵代替的话,计算量就会骤减!因为,很多复杂的数学计算可以写在一个矩阵框框里面,然后,简单地用一个矩阵乘法,结果就出来了!
好,接下来,我们简单来推导一下这些矩阵,这样,你对矩阵的理解就能更加深刻了。
二、从旋转开始
根据前辈们的经验,虚拟3D物体的操作过程是有顺序的,是按照缩放->旋转->平移->投影的步骤来的。
为什么是缩放->旋转->平移->投影的步骤呢?
还是拿小汽车为例。当小汽车从数据变成图形的时候,最开始是处于虚拟3D坐标系原点的,而且,初始的小汽车模型数据是优化过的,其中很多数据都是对称的或者干脆是0,也就说,最原始的小汽车数据是最容易处理的。这几个步骤中,平移是最简单的,缩放稍微复杂些,旋转是最复杂的了,而投影必须在最后一步。
如果不按这个顺序呢?也是可以操作的,只不过,会带来性能和效率上的问题。
如果我们先平移后旋转,就相当于让简单的平移把最原始的优化数据破坏了,数据一旦被破坏就会变复杂,然后,这个“复杂化”的数据再进行旋转的话,会加大CPU的负荷。
如果我们先旋转后平移,相当于最优的数据先进行复杂计算,然后再进行简单的平移计算,就能大大提高3D图形数据的处理速度了。
明白了这一切之后,我们再深入了解一下3D物体的旋转。
由于上面先旋转后平移的原则,我们的旋转都是在3D坐标系原点进行的。一开始我们会觉得旋转很简单,不就是转动个角度吗?仔细一想发现并不简单,因为物体是自由的,它可以绕着任何一条直线进行旋转,问题一下子就变得复杂了。
但是,根据程序员们的经验,任何一个物体的复杂旋转问题,都可以分解成相对简单些的“绕轴”旋转,也就是绕着x轴、y轴或者z轴之一进行旋转。因为任一旋转轴都可以看成是一个向量,这个向量可以分别在三个轴上进行投影,某个物体绕着该轴旋转的时候,我们可以用三角函数的知识得到该物体绕3个轴分别旋转了多少角度。总而言之一句话,绕着3个方向轴的旋转,可以合成3D物体的任意旋转。
所以,我们只需要知道,一个3D物体绕某个方向轴旋转应该如何计算,然后,我们就可以处理3D物体的任意旋转了。
我们可以把问题再简化一下,这回旋转的不是小汽车了,而是一个立方体(旋转的原理是一样的),立方体的正中心就处于3D坐标轴的原点。
好了,我们试着让这个立方体绕着z轴顺时针旋转一个角度θ。
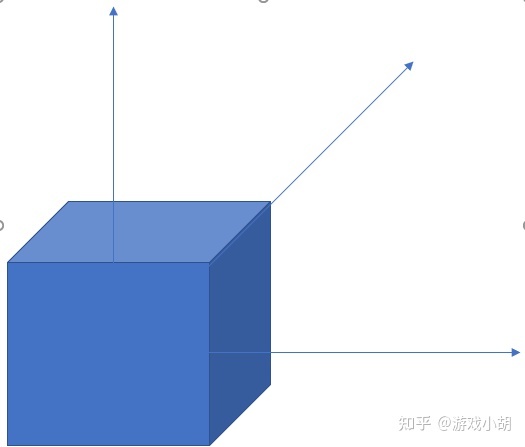
你发现了什么?没错,一个立方体绕着z轴旋转的时候,里面任意一点的z坐标是不变的。为什么z坐标不变呢?你想一想,要改变立方体的z坐标,是不是需要让立方体在z轴方向上移动呢?而现在,立方体只是绕着z轴旋转,根本就没有移动。如果把这个立方体投影到z轴上(降到一维),它就变成了一条直线,而旋转的过程中,这条直线是不会变的。
也就是说,立方体绕着z轴旋转,我们只需要重新计算旋转后的x、y坐标就可以了,然后,这个相对复杂的3D问题一下子就变成一个2D问题了。
在3D游戏编程中,所有的3D物体都是由一个一个三角形组成的,而三角形是由3个小点组成的,也就是说,立方体的旋转过程,可以简化成一个又一个点的旋转。接下来,我们就在2D坐标系下推导一下任意一点的旋转计算过程。
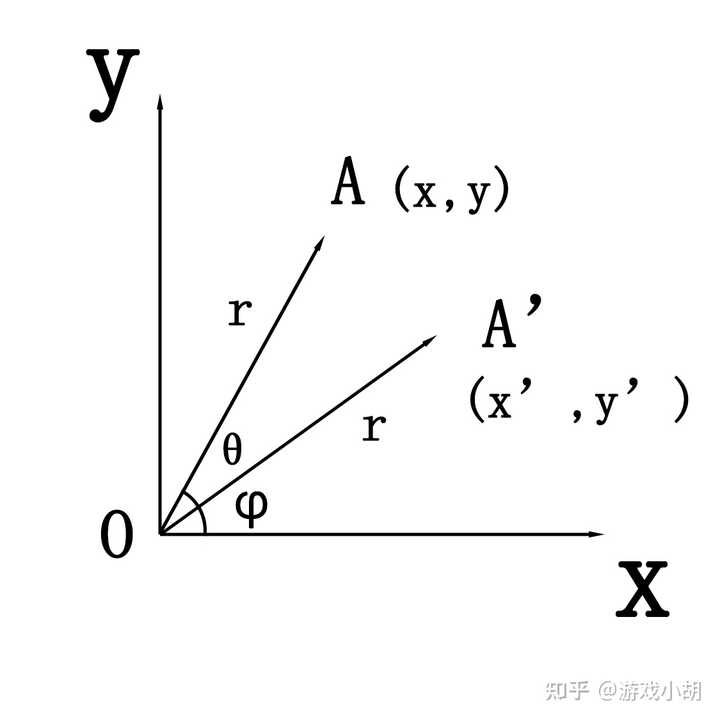
其实,这个问题使用初中数学的知识就可以解决了,我们先看下图。
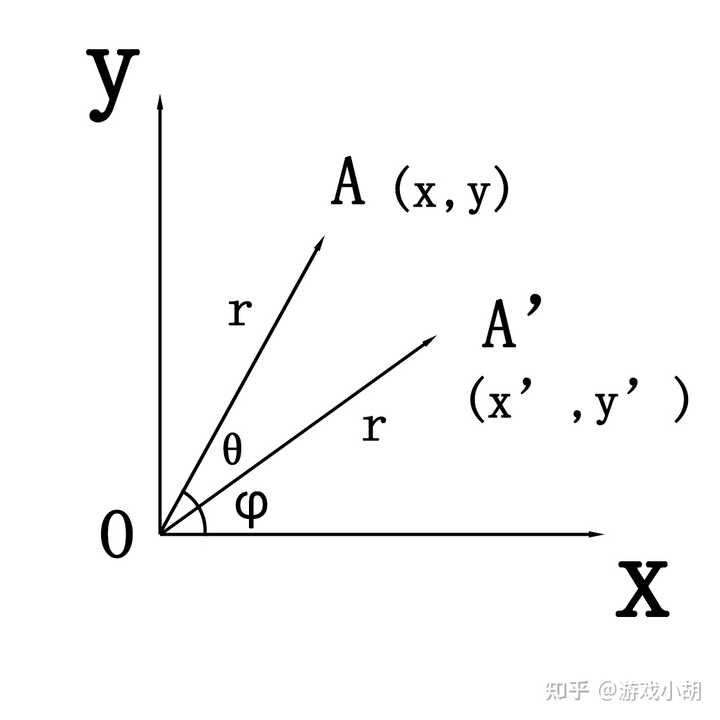
画一个最常见的x-y坐标系,然后点A绕着原点旋转一个θ角度来到了A’点,已知A点的坐标是(x,y),如何计算A’点(x’,y’)的坐标呢?
这个问题看起来难解,其实我们只要按部就班就能解决。
1.首先我们把A点和A’点和原点O连起来,那么OA和OA’的夹角为θ;
2.设OA’和x轴的夹角为φ,这样的话,方程就很好列了;
3.然后列A点的方程,设OA的长度是r,可以得到如下的方程:
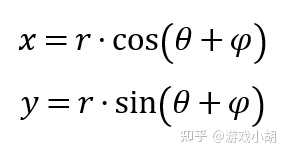
4.接下来再列A’点的方程:

5.然后,我们用和差公式展开A点的方程:
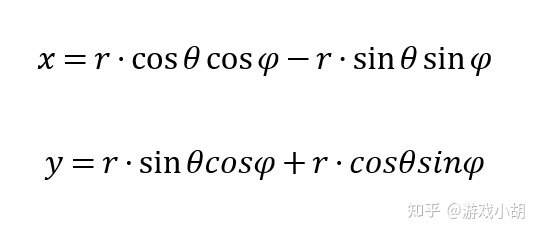
6.把A’点的方程代入A点的方程,就可以消除r这个变量了:

7.在A点方程两边乘以cosθ,就可以得到第一个关系方程:
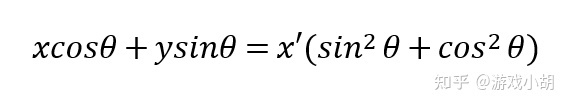
8.在A点方程两边乘以sinθ,就可以得到第二个关系方程:
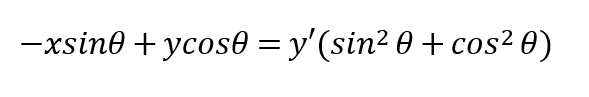
9.根据三角函数的平方公式,x’和y’右边的平方和为1,所以,两个方程可以写成下面这样的最终形态:
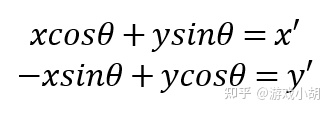
根据最开始矩阵的知识,我们可以把这两个方程写成下面的矩阵样子:
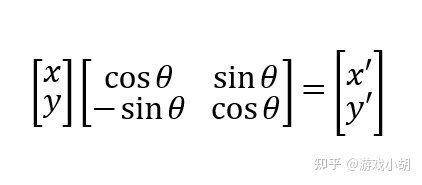
这下明白了吧?一个点的旋转,可以非常简单地仅仅利用一个矩阵进行解决。
我们做个简单的对比:
如果不用矩阵的话,这个旋转的过程需要4次乘法、2次三角函数计算、2次加法;
如果我们用矩阵计算的话,只需要进行1次矩阵乘法操作。
你可能会说,矩阵的计算不还是要展开吗?如果你这样想的话,那就错了。因为矩阵非常对称的关系,而且用在3D图形学中的矩阵都是正方形矩阵,计算机在处理矩阵乘法的时候有很多非常特别的方法,非常快速就能计算出结果。所以,用矩阵乘法来代替普通的乘法和加法,能大大提高3D图形处理的效率。
我们上面得到的矩阵乘法,是2D点使用的,但我们是3D空间,里面是3D的点,该如何推导呢?其实很简单,因为绕z轴旋转的时候z坐标是不会变的,我们只需要把上面得到的二维矩阵扩展到三维就可以了。
我们先改变一下矩阵的写法,把上面竖着写的x、y变成横着写的x、y:
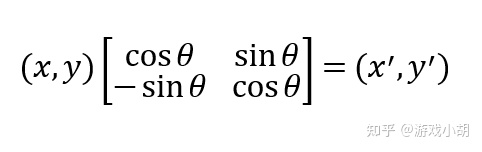
这样的话,更符合我们的视觉习惯,也就是一个点的坐标乘以矩阵得到另一个坐标。
然后,我们要把二维坐标变成三维坐标,也就是在两边各添加一个相同的z坐标:

按照矩阵乘法的规则,我们得到了如下的三维点旋转的变幻矩阵:
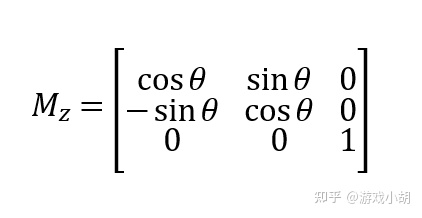
这是绕z轴的旋转矩阵,还有绕x轴、y轴的旋转矩阵,推导过程就不重复了,和z轴的推导过程类似,我在这里就把结果写出来吧。
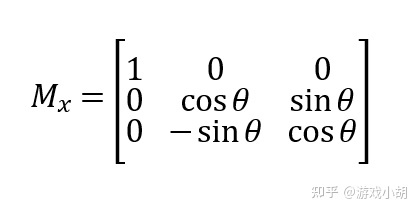
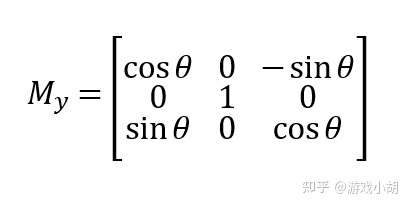
三、从移动操作看齐次坐标
旋转矩阵是除投影矩阵外最复杂的一个了,不过,你跟着我上面的思路,应该不难理解吧?
也就是说,不仅旋转可以变成矩阵乘法,缩放、平移、投影也能变成矩阵乘法。我们先看平移的过程。
平移其实很简单,就是一个简单的加法而已。比方说,这回是三维空间中的点A,坐标是(x,y,z),我们要把它移动一段距离。根据前面学习的向量知识,移动的过程可以看成是一个向量加法的过程。不理解?我们画个图你就明白了。
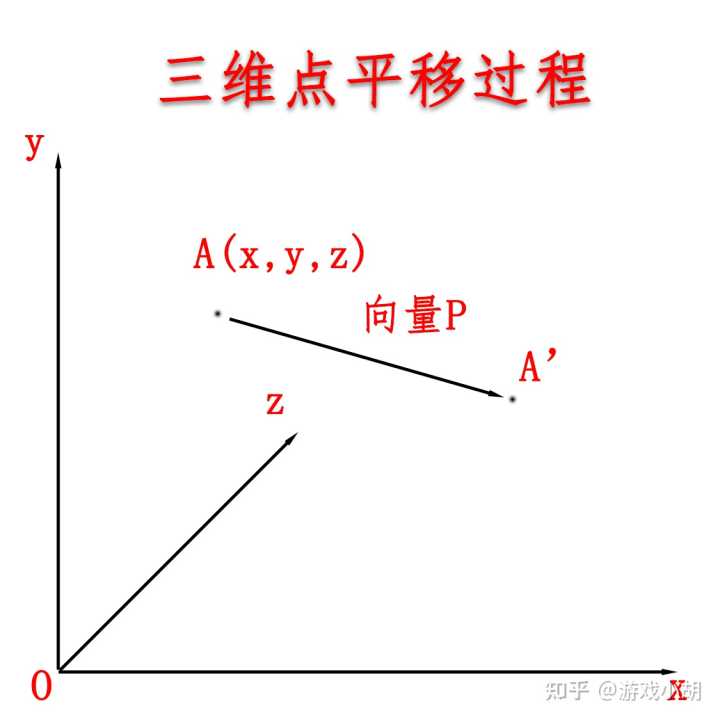
我们要得到A’点的坐标很简单,只要计算
(x,y,z)+P
的结果就行了。假设向量P的坐标是(Px,Py,Pz),那么,A’点的坐标就是下面这样子的:
A’ = (x+Px,y+Py,z+Pz)
但是,我们的目的不是加法,而是要把这个平移的过程写成类似矩阵相乘的样子,比方说下面的这个样子:

我们可以直接解方程,然后代入这个矩阵,这个矩阵就会变成下面的样子:
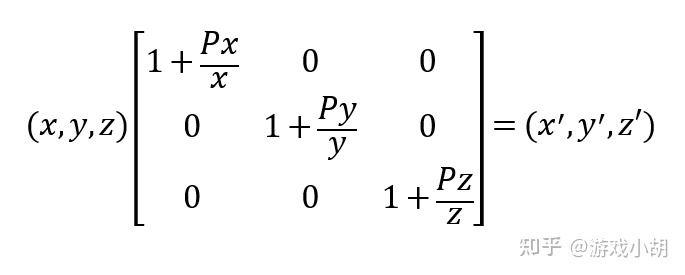
不用我来评价你也知道,变换矩阵写成这个样子肯定是不行的。原本只是一个简单的加法,变成矩阵之后,竟然活生生多出了除法的计算!而且,当A点坐标中有0分量的时候,这个变换矩阵还不能用!这不是明显的简单问题复杂化吗?即便计算机在处理矩阵乘法的时候有优势,但我们也不能这么造啊!
当年的程序员们也发现了这个问题,不过,他们很快就解决了这个问题,方法很简单——给三维空间中的点增加一个齐次坐标。
也就是说,A点的坐标不再是(x,y,z),而是变成了(x,y,z,w)。实际上,披着程序员外衣的数学家们又一次创造了新东西(齐次坐标和四元数是类似的,四元数是由数学家William Rowan Hamilton于19世纪发明的,是不是很早?),齐次坐标的意义并没有如此简单,但我们在3D游戏编程中用到的仅仅是w=1的情况。为什么呢?因为w=1后,不会改变3D点的性质,而且还能简便计算。
给点增加齐次坐标之后,这个平移矩阵的问题就变成了一个4D的问题了:
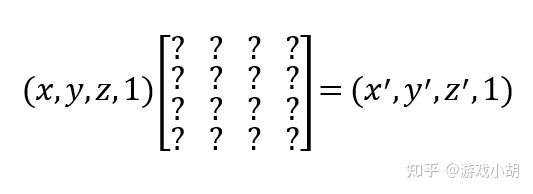
由于平移向量P是已知的,再根据矩阵乘法的特性,平移矩阵的推导并不难。我们拿x->x’的计算过程来推导一下。
x’是目标矩阵的第一列,也就是A点形成的1×4矩阵的第一行和平移矩阵的第一列分别相乘相加,假设平移矩阵第一列是c1、c2、c3、c4,那么可以得到如下的等式:
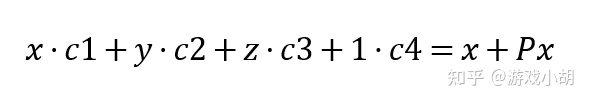
这个等式很容易解,很明显可以得到如下的答案:
c1=1
c2=0
c3=0
c4=Px
我们用这个方法可以很容易把平移矩阵的4列全部推导出来,最终形成的平移矩阵是下面这个样子的:

你看,增加了一个齐次坐标之后,这个平移矩阵不仅容易理解,而且还没有增加计算量,可以靠着计算机的矩阵加速来快速计算,最主要的是,平移的过程也变成了一个简单的矩阵乘法过程了。(在3D图形学中,平移问题引申出来的还有仿射空间的概念,有兴趣的朋友可以自己探索探索)
其实,程序员们基本上都有强迫症。旋转矩阵是3维的,为什么平移矩阵要4维?为了强迫症,程序员们把所有的变换矩阵都扩展到了4维,也就是说,全部增加了齐次坐标。推导过程很简单,我就直接把4维的变换矩阵全部列出来吧。

关于3D图形学中的这个矩阵变换,有很多人是一边疑惑一边学习的,他们最大的疑惑就是——为什么3D坐标非要用4D的矩阵?
那是因为那些人学习的时候没有一个思考的过程,他们的老师直接把变换矩阵教给了他们,而不去说明一下,当然会疑惑了。但是在这里,只要你一步一步跟着我上面的思路,就不会有这样的疑惑,因为道理很简单:为了让平移的过程简便化,也为了程序员们的“强迫症”。
四、关于投影矩阵
都说道这里了,干脆一口气把最后的投影矩阵也说了吧!
我们已经知道,投影过程是把3D内容投影到一个二维平面上,这个问题看起来毫无头绪,但生活中是有活生生例子的。
什么例子呢?就是——拍电影。
电影是显示在二维幕布或者屏幕上的,可显示的却是3D世界,说得严谨一些,显示的就是3D世界在摄像机的感光平面上的投影图像罢了!
也就是说,我们只需要模仿摄像机的工作模式,就能慢慢推导出投影的过程了。
好了,假设你来到了虚拟的3D世界,现在举着虚拟的摄像机在拍摄虚拟的3D世界。由于你是在虚拟世界中,你可以没有重力的影响,那么,你会有哪些动作呢?
你拿着摄像机,起码有如下的一些操作:
①移动;
②左右转动镜头;
③上下转动镜头。
我们不需要其他的操作了,因为其他的操作都能从这3个基本操作中合成出来。
但是,这么看的话,问题还是很复杂,因为摄像机要运动,计算的时候要怎么入手呢?
先放下这个问题,我们可以把问题进行简化:假设摄像机一直不动,投影矩阵是什么样的呢?
为了更简化问题,我们让摄像机处于世界坐标原点的位置,那么,投影的过程是什么样的呢?
这里有2个参数。
①摄像机是一个透镜组合(其实我们眼睛也是透镜组合),对于透镜,有一个成像的平面,这个平面距离透镜组(摄像机)是有一定距离的,我们把这个距离叫做视距(你可以直观感受到,你把一个物体靠近眼睛,太近的话,根本看不清,而且,当你眼睛看某个距离的物体时,那些更近的物体就会模糊,在摄像机的表现上就是前景虚化了)。而视距就是我们的第一个参数,假设是d。
②投影的时候有个视角的问题,就是摄像机能够看多宽的视野。视野不能太窄也不能太宽。玩过摄影的朋友应该知道,视野太窄的远摄镜头不适合拍摄视频,只适合打鸟;视野太宽的广角镜头也不适合拍摄视频,因为画面会变形,看起来不真实。最合适拍视频的就是正常视野的镜头,一般是50mm左右的镜头。在3D游戏中,为了数学计算的简便,我们一般取的是90°视野的虚拟摄像机,这样拍出来的画面不仅没什么畸变,而且数学计算很简单(直角在三角函数中就是很简便的)。
好了,现在假设三维世界中某个点p(x,y,z)要投影到这个视距为d、视角为90°的虚拟摄像机投影面上,要如何列方程呢?
首先,z坐标就没有了,因为在投影的过程中“降维”了,我们只需要计算这个条件下的x、y坐标就行。
如何计算这两个坐标呢?
我们只需要在x-z平面上和y-z平面上分别计算坐标就行。
拿x-z平面来看,可以画出如下的投影过程图:
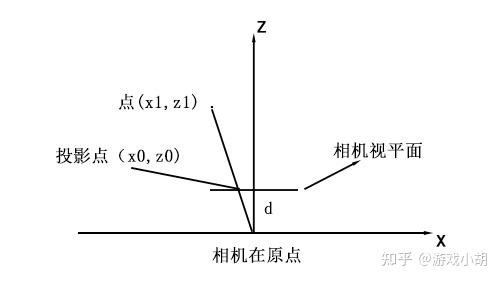
我们不需要z坐标,只需要x坐标,那么,很容易就能根据相似三角形列出方程:
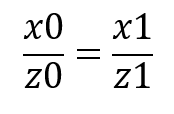
然后,在y-z平面也能很容易列出y坐标的方程:
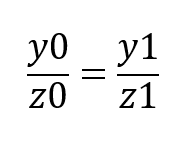
我们可以看到,z0就是视平面的距离d,这样从(x1,y1,z1)这个点投影到视平面上的(x0,y0)的方程就很容易列出来了,我们直接把矩阵加上去:
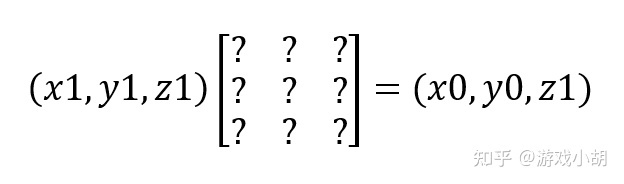
结合我们上面列的2个方程,我们很容易就能计算出这个矩阵的数值:
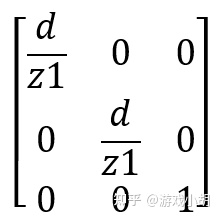
分母有个z1怎么办?矩阵需要通用,不可能每一次数学计算之前都重新计算一遍矩阵,那样的话,干脆不用矩阵算了,毕竟,投影的过程不是很复杂,用普通的数学计算方式性能也差不到哪里去。
不过,在一个3D程序中统一使用矩阵是有很多好处的,因为,可以把一系列的矩阵全部按顺序先乘起来,最后,原始坐标只要乘以一个矩阵就能变换到投影坐标了,性能提升是非常可观的。
既然如此,这个分母中的z1怎么办?
这里,就体现出齐次坐标的用处了。我们可以把投影矩阵写成如下4×4的样子:

这个相当于是把目标点(x0,y0)分别乘以z1倍,扩展到4维的时候,把齐次坐标w也乘以了z1倍,这样,这个矩阵就和z1没有关系了。
然后,我们在使用这个矩阵的时候,只要在计算过后通过重置齐次坐标w为1的操作,就能保证最后坐标的正确性。
也就是说,当摄像机位于零点,正对z轴,并且视距是d、视角是90°的时候,投影矩阵就是上面的那个样子。
没错吧?
实际上,还有一个小问题,那就是屏幕宽/高比的问题。我们计算的这个投影矩阵是基于正方形投影面来说的,而实际上,电脑屏幕或者其他屏幕很少有正方形的,宽度和高度基本上都不一样。也就是说,当正方形投影图像显示在长方形的屏幕上时,图像就会产生拉伸而显得不真实。
解决的方法其实很简单,就是在投影变换的时候,把y轴的投影按照屏幕的宽/高比进行缩放就可以了。
假设屏幕是4:3的,那么,在投影变换的时候,让y轴的投影乘以4:3的倍数,这样,y方向的内容就会相应变少,最后,这个正方形投影面映射到屏幕上的时候,图像就会变得正常了。
所以,真正的投影矩阵应该是下面这个样子:(a代表的是屏幕的宽/高比)

至此,投影矩阵的问题也解决了。
那么,问题真的解决了吗?
答案很明显是没有,因为,我们只是计算了一个特殊情况下的投影矩阵。我们玩3D游戏的时候,总不可能一直让摄像机在原点不动吧?真那样的话,还玩个啥?
解决方法其实也很简单:
我们把世界坐标系的原点移动到相机身上,然后,让这个坐标系的z轴朝着摄像机的方向不就行了吗?
没错,就是这样的解决方法。
相当于,把虚拟3D世界的所有物体再次旋转、移动一次,保证摄像机在零点并朝向z轴就行了。
这个过程是不是很熟悉?
没错,就是上面的旋转和平移操作,也是可以解出一个4×4矩阵来的。
而这个操作,被称为相机变换,也就是世界坐标到相机坐标的变换。
相机变换矩阵最麻烦的地方就在于旋转了,而其中的关键,就在于相机模型的建立。
这里,早期的那些披着程序员外衣的数学家们又开始了建模。通过不断地探索和思考,“数学家”们创建了2个可行的相机模型:
①欧拉相机模型;
②UVN相机模型。
什么是欧拉相机模式呢?就是通过欧拉角的启发来定义的相机模型。欧拉角有3个角度,分别定义了三维坐标系中某个点绕着3个轴的旋转角度,我们只要知道这3个角度,就能通过计算得到目标点的具体位置。
有了欧拉角的摄像机,就能通过欧拉角的分量来进行世界坐标的旋转了。
具体来说,欧拉相机模型有4个参数,分别是相机的位置和相机的3个欧拉角度。
但是,欧拉相机模型在实践中不是很好用。这个相机模型用的是角度,我们需要重新定义变量,在编程的时候并不是特别方便,而且在转化的时候也需要一定的计算量。
游戏的实时性那么高,披着程序员外衣的数学家们怎么可能甘心呢?
于是,这些数学家在欧拉相机模型的基础上改进得到了一个新的相机模型——UVN相机模型。
从数学本质上来看,两者的区别不大,欧拉模型用的是角度,而UVN模型用的是向量,而向量更适合矩阵计算,所以,现在大部分3D引擎的相机模型都是UVN相机模型。
那么,UVN是什么意思呢?其实很简单,它就是一个相机坐标系而已。
相机坐标变换的意义在于,要把玩家或者用户从虚拟世界转移到相机世界中,所有的虚拟物体都要以相机为基准重新定义一次。
想一想这个过程:
最开始的时候,我们的主角是虚拟3D物体本身,关于三角形和顶点的构建都是基于3D物体的本地坐标系的;
所有3D物体准备好之后,必须在虚拟3D世界中安排、组织好,虚拟3的世界成了主角,所以有了世界坐标系,从本地坐标到世界坐标的变换就是世界坐标变换;
同理,现在的主角是虚拟摄像机,而从世界坐标到相机坐标的变换就是相机坐标变换。
相机坐标系是什么样子的呢?
我们用的是左手系,那么,虚拟摄像机用的也是左手系。以虚拟摄像机的位置为原点,右方向、上方向、前方向为正方向,这样的三维正交坐标系就是相机坐标系。和左手系的XYZ坐标系一样,坐标轴有个名字:相机右方向是U轴,相机上方向是V轴,相机前方向是N轴。明白了吧?UVN的相机模型,其实就是一个相机坐标系。
这样的坐标系主要有3方面的好处:
①设置起来很方便;
②程序员理解起来也简单;
③坐标变换的矩阵也容易推导。
为什么设置起来方便呢?我们只需要4个向量就能描述这个摄像机了,分别是位置向量、右向量、上向量和目标向量,也就是说,4个不同意义的参数,数据格式是一样的!你说,是不是很方便?
那么,程序员理解起来为什么简单呢?因为,这样的相机坐标系可以理解成一架灵活的战斗机,虚拟摄像机的移动和旋转完全可以理解成战斗机的移动和旋转。
把虚拟摄像机理解成一架战斗机,现在,战斗机悬停在虚拟3D世界中的某个位置上,战斗机有哪些操作呢?
①战斗机可以沿着N轴方向移动,这个操作被称为移动(move);
②战斗机可以沿着V轴方向移动,这个操作被称为飞行(fly);
③战斗机可以沿着U轴方向移动,这个操作被称为平移(strafe);
④战斗机可以改变飞行的方向,也就是自身绕着V轴旋转,这里有一个专有名词叫做偏航(yaw);
⑤战斗机可以向上方飞跃,也能向下方俯冲,相当于是点头的操作,也有一个专有名词叫做倾斜(pitch);
⑥战斗机可以绕着N轴一直旋转,是一种很酷的飞行方式,这个专有名词叫做滚转(roll)。
根据这6个名词,程序员就很容易理解虚拟摄像机的移动和旋转了,也能通过战斗机的比喻来彻底记住这个过程。
最后,是变换矩阵比较容易推导。
坐标变换的目的是把xyz坐标系中的点p变换到uvn坐标系中的点p’。坐标要如何变换呢?方法与世界坐标变换类似——先旋转后平移。
点p是xyz坐标系的,现在先不管虚拟摄像机的位置,把uvn坐标系和xyz坐标系的原点重合,你发现了什么?
没错,p’点相当于是xyz坐标系在uvn坐标系上的投影!而投影的计算非常简单,靠着向量的点积就能解决。
也就是说,点p在xyz坐标系中的向量OP分别乘以uvn的单位向量,就能得到p’点在uvn坐标系上的分量值。
比如,点p的向量是p,uvn的单位向量分别是u、v、n,那么p’点的坐标就是
(p·u,p·v,p·n)。
为了和世界坐标变换矩阵一样,我们的点也需要是4维的,所以,p’点的正确坐标应该是:
(p·u,p·v,p·n,1)。
我们可以把这个过程转变成矩阵相乘的过程,就可以得到如下的旋转矩阵:

其中的xyz分别代表的是单位向量在UVN坐标系中的分量大小。
旋转矩阵已经有了,接下来就是平移矩阵。上面已经推导过平移矩阵了,我们可以直接用。假设虚拟摄像机在世界坐标的位置向量是Pos,由于我们已经把UVN坐标系移动到了原点,所以,这个位置的移动是负的,也就是说,在UVN坐标系中,所有物体都应该平移-Pos的距离(注意负号)。
根据前面的平移矩阵,我们很容易写出这个四维的平移矩阵:
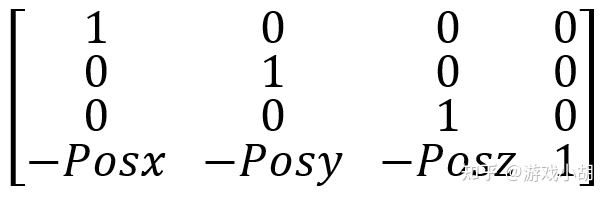
然后,我们只需要把旋转矩阵和平移矩阵相乘,就能得到UVN相机模型的相机变换矩阵了:

矩阵最后一行是相机位置向量和单位向量的点乘,最后的结果是一个数值,记得有个负号。
最后,要使用这一系列矩阵的时候,按照
旋转矩阵×平移矩阵×缩放矩阵×相机矩阵×投影矩阵
的过程先计算好一个总体的变换矩阵,然后,直接用原始的坐标乘以这个变换矩阵就OK了!当然,别忘了最后要用w坐标来一次齐次计算。
好了,关于矩阵在计算机3D图形处理方面的应用介绍就说完了。我想,你应该能明白矩阵的用处了吧?
转载自知乎-游戏小胡
https://www.zhihu.com/question/22047061/answer/2079759458

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 72
72 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)