sklearn——数据降维
sklearn——数据一.特征选择1.特征选择是什么特征选择就是单纯地从所有特征中选择一部分特征作为训练所使用的特征。这些特征在选择前和选择后数值可能会发生变化,也可能不发生变化。但是在特征选择后特征维数肯定比特征选择前低。2.主要方法(三大武器)①Filter(过滤式):VarianceThreshold②Embedded(嵌入式):正则化、决策树③Wrapper:包裹式二.sklearn特征选
·
sklearn——数据
一.特征选择
1.特征选择是什么
特征选择就是单纯地从所有特征中选择一部分特征作为训练所使用的特征。这些特征在选择前和选择后数值可能会发生变化,也可能不发生变化。但是在特征选择后特征维数肯定比特征选择前低。
2.主要方法(三大武器)
①Filter(过滤式):VarianceThreshold
②Embedded(嵌入式):正则化、决策树
③Wrapper:包裹式
二.sklearn特征选择API
1.VarianceThreshold
#导入库
from sklearn.feature_selection import VarianceThreshold
import numpy as np
其中VarianceThreshold可以以方差为阈值进行降维。
#实例化
var=VarianceThreshold(threshold=0)#以方差小于等于0为阈值降维,特征方差小于等于0的将被去掉
#转化、降维
var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
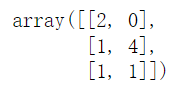
2.PCA(主成分分析)
PCA是一种分析简化数据集的技术,它会以原有的数据集损失一部分信息为代价进行降维,并且降维后的数据集与原有数据集数值将会不同。
当特征数量达到上百的时候将可以使用PCA特征降维。
#导入库
from sklearn.decomposition import PCA
#实例化
pca=PCA(n_components=0.92)
#n_components可以为整数,也可以为小数,一般使用小数,表示保留的信息占总信息的百分比,一般为0.90-0.95
#降维
pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
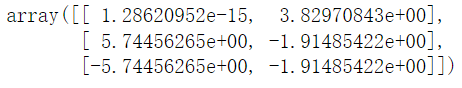
三.数据集划分
将所有数据划分为训练集、验证集。训练集用来训练模型,验证集用来验证模型的效果。训练集、验证集比例一般为7:3或者8:2。
1.sklearn数据集划分API
#导入库
from sklearn.model_selection import train_test_split
2.sklearn数据集API


#导入库
from sklearn.datasets import load_iris
li=load_iris()
li.data

li.target

x_train,x_test,y_train,y_test=train_test_split(li.data,li.target,test_size=0.3)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)