语音识别SpeechRecognition中文包对应文件名的处理
背景:win8.1, python 3.9.7 自带idle, 模块SpeechRecognition-3.8.(pip install SpeechRecognition安装默认版本)现象:1. 在网站CMU Sphinx - Browse /Acoustic and Language Models/Mandarin at SourceForge.net下载cmusphinx-zh-cn-5.2
背景:
win8.1, python 3.9.7 自带idle, 模块SpeechRecognition-3.8.(pip install SpeechRecognition安装默认版本)
现象:
1. 在网站 CMU Sphinx - Browse /Acoustic and Language Models/Mandarin at SourceForge.net
下载cmusphinx-zh-cn-5.2.tar.gz后,发现包中的文件/文件夹名字和模块自带的en-US文件夹下的文件/文件夹不同名。
CMU Sphinx - Browse /Acoustic and Language Models/Mandarin at SourceForge.netSpeech Recognition Toolkit![]() https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/2. 在尝试运行练习小程序后,发现有错误提示,说找不到文件或文件夹。
https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/Mandarin/2. 在尝试运行练习小程序后,发现有错误提示,说找不到文件或文件夹。
解决办法:
1. 在en-US同目录下建立一个 zh-CN文件夹
2. 把cmusphinx-zh-cn-5.2.tar.gz解压后的文件/文件按照en-US中的文件/文件夹命名。其中readme 可以不更改为License.
3. 运行后,中文正常输出。(有的中文还是辨认不出来。和是否能运行无关了)
4. 小程序和图片附在这里,方便参考。
5.语音文件,可以自己录制一个 demo_audio.wav,也可以找一个简单一点的
附件:
1. 中文语言包解压后的内容

2. 模块自带英文语言包内容
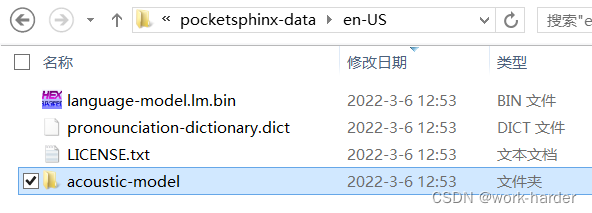
3. 语音识别小程序
# speech_recognition的安装: pip install SpeechRecognition
import speech_recognition as sr
audio_file = "demo_audio.wav"
r = sr.Recognizer()
#打开语音文件,放在本目录下
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
#将语音文件内容转换为文本
print("文本内容:",r.recognize_sphinx(audio,language="zh-CN"))

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)