opencv学习路径
第一章:机器学习与计算机视觉计算机视觉简介技术背景了解人工智能方向、热点计算机视觉简介cv简介cv技能树构建应用领域机器学习的数学基础线性与非线性变换概率学基础熵kl散度梯度下降法2. 计算机视觉与机器学习基础图像和视频图像的取样与量化滤波直方图上采样下采样卷积直方图均衡化算法最近邻差值单/双线性差值特征选择与特征提取特征选择方法filter等特征提取方法:PCA、LDA、SVD等边缘提取Cann
第一章:机器学习与计算机视觉
人工智能是追求目标,机器学习是实现手段,深度学习是其中一种方法。
机器学习步骤
通常学习一个好的函数,分为以下三步:
1、选择一个合适的模型,这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
2、判断一个函数的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
3、找出“最好”的函数,如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。

- 计算机视觉简介
技术背景
了解人工智能方向、热点
计算机视觉简介
cv简介
cv技能树构建

应用领域
机器学习的数学基础
线性与非线性变换
概率学基础
熵
把信息中排除了冗余后的平均信息量称为“信息熵”
kl散度
在信息理论中,相对熵等价于两个概率分布的信息熵(Shannon entropy)的差值
梯度下降法
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!
2. 计算机视觉与机器学习基础
图像和视频
图像的取样与量化: 数字化坐标值称为取样;数字化幅度值称为量化。
滤波:
1、均值滤波
用其像素点周围像素的平均值代替元像素值,在滤除噪声的同时也会滤掉图像的边缘信息。
2、中值滤波
中值滤波用测试像素周围邻域像素集中的中值代替原像素。
3、高斯滤波
加权平均更合理,距离越近的点权重越大,距离越远的点权重越小。
直方图:
直方图的横轴表示亮度,从左到右表示亮度从低到高。
直方图的纵轴表示像素数量,从下到上表示像素从少到多
上采样
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是:
放大原图像,从而可以显示在更高分辨率的显示设备上。
下采样
缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:
1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
卷积
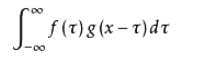
系统某一时刻的输出是由多个输入共同作用(叠加)的结果。
(1)原始图像通过与卷积核的数学运算,可以提取出图像的某些指定特征(features)。
(2)不同卷积核,提取的特征也是不一样的。
(3)提取的特征一样,不同的卷积核,效果也不一样。
直方图均衡化算法
图像直方图完全均匀分布的时候,此时图像的熵是最大的(随机变量每个值的概率都相同时,概率最大),图像对比度是最大的。
最近邻差值(图像插值)
插值是根据抽样函数或信号估计连续位置的数值
假设有一副图像A,像素为 m×n。如果要将其缩放为原来的a倍变成图像B,其像素为 am×an=M×N(*代表乘法运算),将会涉及到插值的问题,常见的插值方法有三种最邻近插值、双线性插值、双立方插值。
单/双线性差值
特征选择与特征提取
特征选择方法
filter等
特征提取方法:PCA、LDA、SVD等
边缘提取
Canny
Roberts
Sobel
Prewitt
Hessian特征
Haar特征
相机模型
小孔成像模型
相机模型
镜头畸变
透视变换
3. 计算机视觉与机器学习进阶
聚类算法
聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。
kmeans
层次聚类
密度聚类
谱聚类
坐标变换与视觉测量
左右手坐标系及转换
万向锁
旋转矩阵
四元数
欧拉角,旋转矩阵,轴角,四元素等
三维计算机视觉
立体视觉
多视几何
SIFT算法
尺度不变特征变换匹配算法是一种电脑视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量
三维计算机视觉与点云模型
PCL点云模型
spin image
三维重构
SFM算法
通过相机的移动来确定目标的空间和几何关系,是三维重建的一种常见方法。
图像滤波器
PLC
直通滤波
体素滤波
双边滤波器
条件滤波
半径滤波
图像增加噪声与降噪
4. OpenCV详解
OpenCV算法解析
线性拟合

最小二乘法
求解线性回归的方法,使得实际值和估计值差的平方和最小
RANSAC算法
随机抽样一致算法
哈希算法
DCT算法
汉明距离
图像相似度
第二章:深度学习与计算机视觉
- 神经网络
深度学习与神经网络
深度学习简介
基本的深度学习架构
神经元
激活函数详解(sigmoid、tanh、relu等)
上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数
感性认识隐藏层
如何定义网络层
损失函数
所有的机器学习算法都或多或少的依赖于对目标函数最大化或者最小化的过程,我们常常把最小化的函数称为损失函数,它主要用于衡量机器学习模型的预测能力
推理和训练
神经网络的推理和训练
bp算法详解
通过输入与输出之间的差值,调整网络的参数
归一化
Batch Normalization详解
批标准化让每一层的值在有效的范围内传递下去.
解决过拟合
1.神经网络的学习能力过强,复杂度过高
2.训练时间太久
3.激活函数不合适
4.数据量太少
dropout
softmax
手推神经网络的训练过程
从零开始训练神经网络
使用python从零开始实现神经网络训练
构建神经网络的经验总结
深度学习开源框架
pytorch
tensorflow
caffe
mxnet
keras
优化器详解(GD,SGD,RMSprop等

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)