
pytorch distributed 分布式训练
Pytorch 分布式训练 方法总结
·
PyTorch分布式
概念
PyTorch官网文档
PyTorch 分布式训练 知乎
pytorch分布式系列1——搞清torch.distributed.launch相关的环境变量



torch.distributed.launch方法,before pytorch1.9.0
初始化
设置–local_rank 参数
def make_parser():
parser = argparse.ArgumentParser(description='google universal embedding training file.')
# 设置好后,命令行不用自己给参数,程序自动适配
parser.add_argument('--local_rank', type=int, required=True)
args = parser.parse_args()
return args
init_process_grop
import torch.distributed as dist
if __name__ == '__main__':
args = make_parser()
# may not neccessary
rank = int(os.environ["RANK"])
world_size = int(os.environ['WORLD_SIZE'])
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=world_size, rank=rank)
torch.distributed.barrier() # may not neccessary(阻塞、同步)
模型
model = model.cuda()
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], broadcast_buffers=False, find_unused_parameters=False)
数据集
example
num_tasks = dist.get_world_size()
global_rank = dist.get_rank()
sampler = torch.utils.data.DistributedSampler(dataset, num_replicas=num_tasks, rank=global_rank, drop_last=True, shuffle=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, sampler=sampler, num_workers=4, drop_last=True)
or
def build_loader(args, df, is_train, is_test=False):
transform = build_transform(args, is_train)
dataset = PetFinderDataset(df, transform=transform)
num_tasks = dist.get_world_size()
global_rank = dist.get_rank()
# 无需打乱,无需并行
if is_test:
sampler = Data.SequentialSampler(dataset)
data_loader_config = config.val_loader
# 交给DistributedSampler处理
elif is_train:
sampler = Data.DistributedSampler(
dataset, num_replicas=num_tasks, rank=global_rank, shuffle=True
)
data_loader_config = config.train_loader
# validation 可以并行,提高效率,打不打乱都行吧
else:
indices = np.arange(global_rank, len(dataset), num_tasks)
sampler = SubsetRandomSampler(indices)
data_loader_config = config.val_loader
data_loader = Data.DataLoader(
dataset, sampler=sampler, **data_loader_config
)
return data_loader, dataset
# 自定义一下Sampler,加入set_epoch功能?
class SubsetRandomSampler(torch.utils.data.Sampler):
r"""Samples elements randomly from a given list of indices, without replacement.
Arguments:
indices (sequence): a sequence of indices
"""
def __init__(self, indices):
# super().__init__()
self.epoch = 0
self.indices = indices
def __iter__(self):
return (self.indices[i] for i in torch.randperm(len(self.indices)))
# return an iterator
def __len__(self):
return len(self.indices)
def set_epoch(self, epoch):
self.epoch = epoch
set_epoch():每个epoch开始训练时,需要调用一下,sampler的随机种子由epoch设定
for epoch in range(20):
data_loader_train.sampler.set_epoch(epoch)
train_one_epoch()
运行程序
python -m torch.distributed.launch --nproc_per_node 2 --master_port 12345 main0.py
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 0 --master_addr='10.100.37.21' --master_port='29500' train.py
坑
冻结部分参数训练
要设置DistributedDataparallel中的参数
find_unused_parameters=True
! 好像理解错了,如果有参数没有用到forward中,或与loss无关,才是unused parameters
训练集验证集的划分
自己把一整个数据集随机划分为训练集和验证集,一定要设置seed,保证不同进程中数据集是一致的。不然不同进程数据集不同,数据就泄露了,validation会不准确
…
…
…
torchrun方法(用于替代torch.distributed.launch)
PyTorch1.9.0版本之后
#单机双卡
torchrun --nproc_per_node=2 train.py --epoch 5 --batch_size 32
不用再设定–local_rank参数,改为
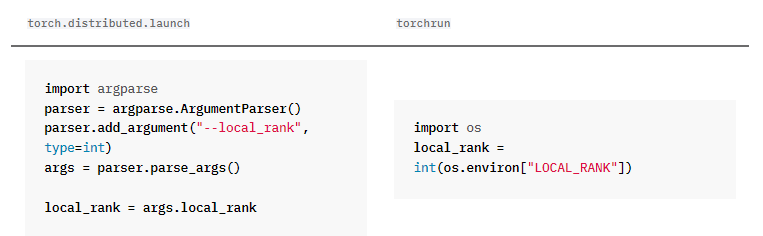
为了方便修改直接
args.local_rank = int(os.environ["LOCAL_RANK"])
两个十分必要的debug方法
分布式训练时有时报错不显示错误信息,非常难排错
用record装饰main函数

设置环境变量 CUDA_LAUNCH_BLOCKING
会拖慢训练进程!正式训练时一定要注释掉
if __name__ == '__main__':
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
main()
…
…
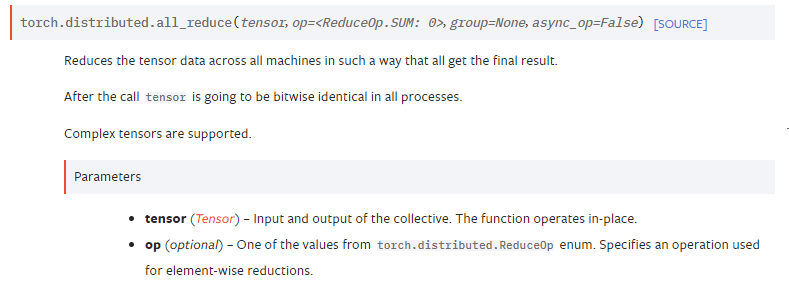
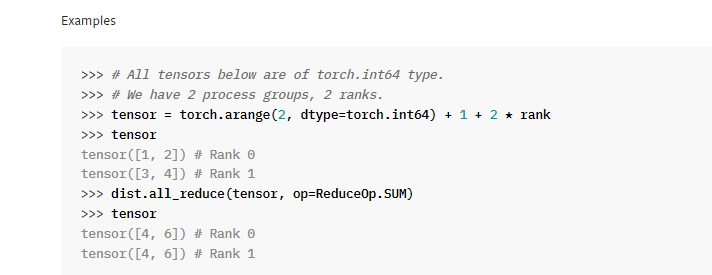
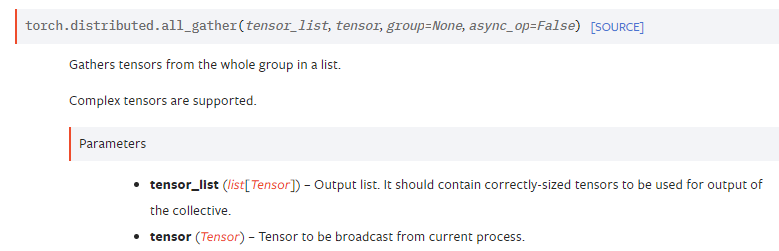
dist.all_gather & all_reduce
all_reduce()默认不同gpu中的指定tensor相加,梯度应该可以正常传递
all_gather()用于将不同gpu指定tensor收集起来放在指定list中,梯度无法正常传递,需要的话要做特殊处理
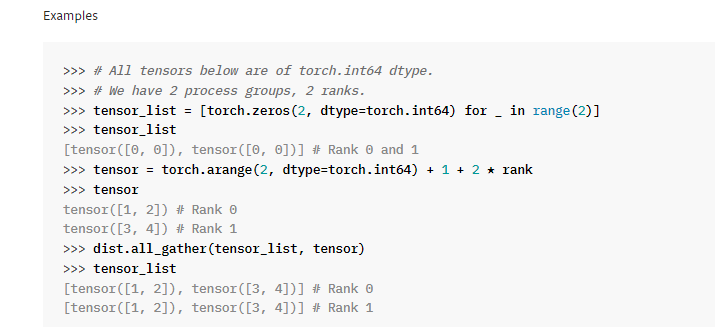
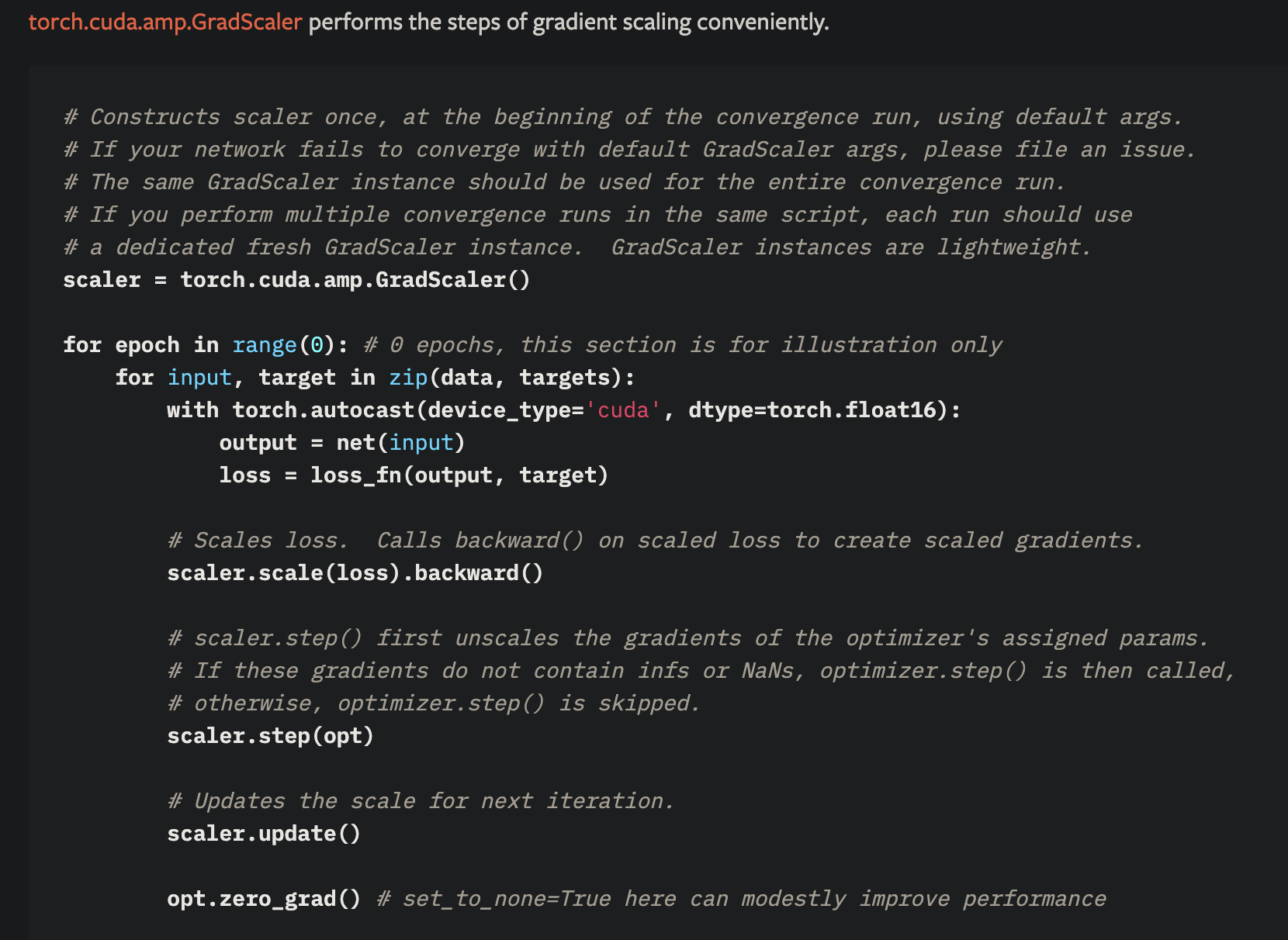
# # amp
from torch.cuda import amp
with amp.autocast():
pass
scaler = amp.GradScaler()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()

鸿蒙生态一站式服务平台。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)