百度AnyQ之七——使用solr的api上传/删除数据
不打算用mysql,所以考虑直接调用接口逐条添加,这样服务器这边压力小一些,不用维护一个数据库,数据库可以在另一个地方维护,然后只给这边添加删除数据就好了。1. solr本身的接口1.0 查看solr的API还是以上传一个faq对为例,{"answer": "带上口罩吧,狗命要紧", "question": "别人都带口罩,我需要带吗?", "id": "101"}(注意:solr的solr_co
不打算用mysql,所以考虑直接调用接口逐条添加,这样服务器这边压力小一些,不用维护一个数据库,数据库可以在另一个地方维护,然后只给这边添加删除数据就好了。
1. solr本身的接口
1.0 查看solr的API
还是以上传一个faq对为例,
{"answer": "带上口罩吧,狗命要紧", "question": "别人都带口罩,我需要带吗?", "id": "101"}
(注意:solr的solr_core中的数据id序号是从1开始的,不是从0开始的)
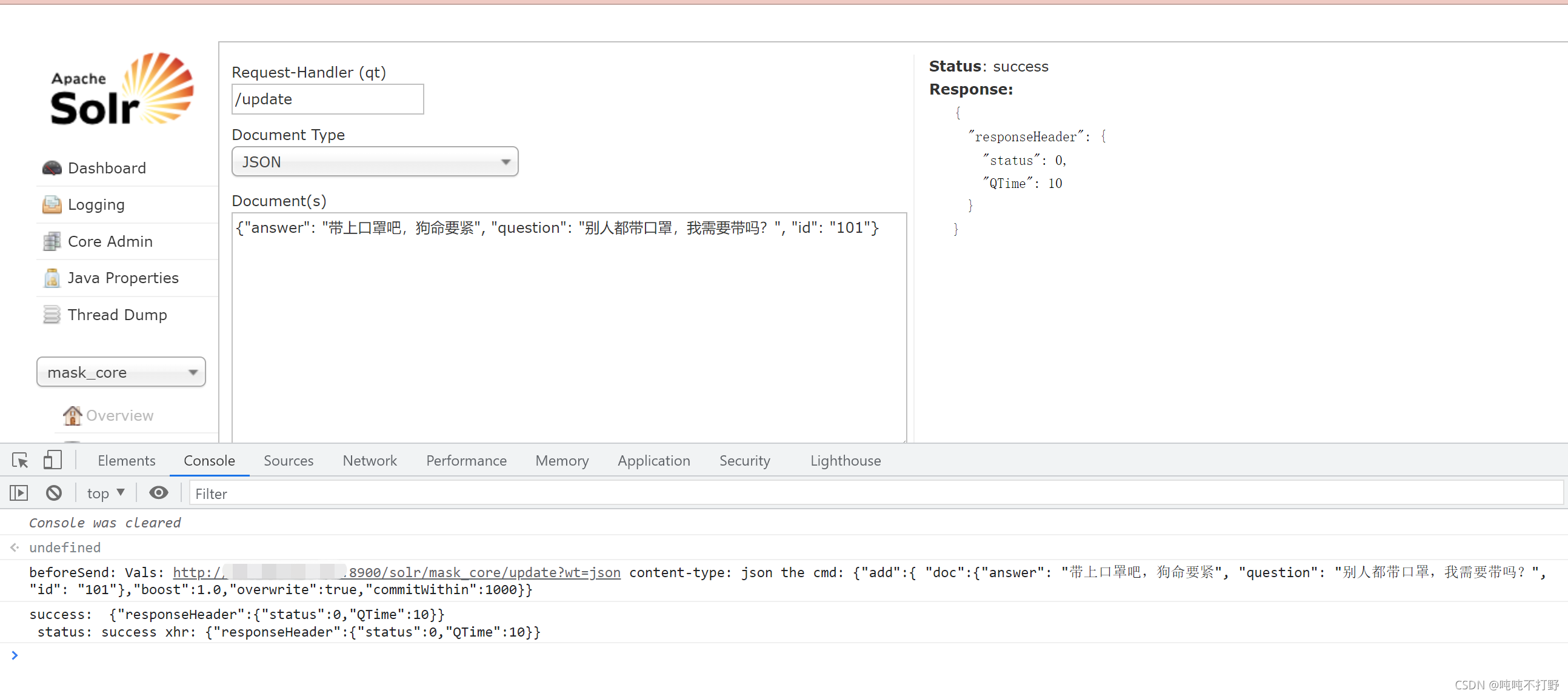
可以打开控制台,查看Console 控制台,可以看到相应的调用的接口。
(可以重复使用同一个faq内容,重复更新,自动覆盖,不会报错)
然后就考虑使用python的request方法去更新这个东西。
根据参考链接,可以知道,对于java,有solrj这样的库可以用来和solr交互。python其实也有一个solrpy,但是很老。
但是其实没必要多余使用一个库,从上面可以看出来api其实很简单,直接硬写就可以了。
1.1 上传文档
上传一个文档
感谢: python对solr进行查询、插入操作(GET\POST)
import json
import requests
url="http://XXXX:8900/solr/solr_core/update?wt=json"
question="计算机学院保研名额是多少?"
answer="每年会有一定的浮动,差不多10个吧"
data= {"add":{ "doc":{"answer": answer, "question": question, "id":101}}}
params= {"boost":1.0,"overwrite":"true","commitWithin":1000}
headers = {"Content-Type": "application/json"}
r = requests.post(url, json = data, params = params, headers = headers)
print(r.json())
这里有个比较恶心的地方,就是每次上传的时候都要有个id号。。
1.2 获取最大id号
关于如何获取这个id号,参考:Stack Overflow Getting maximum value of field in solr
一种方式是:
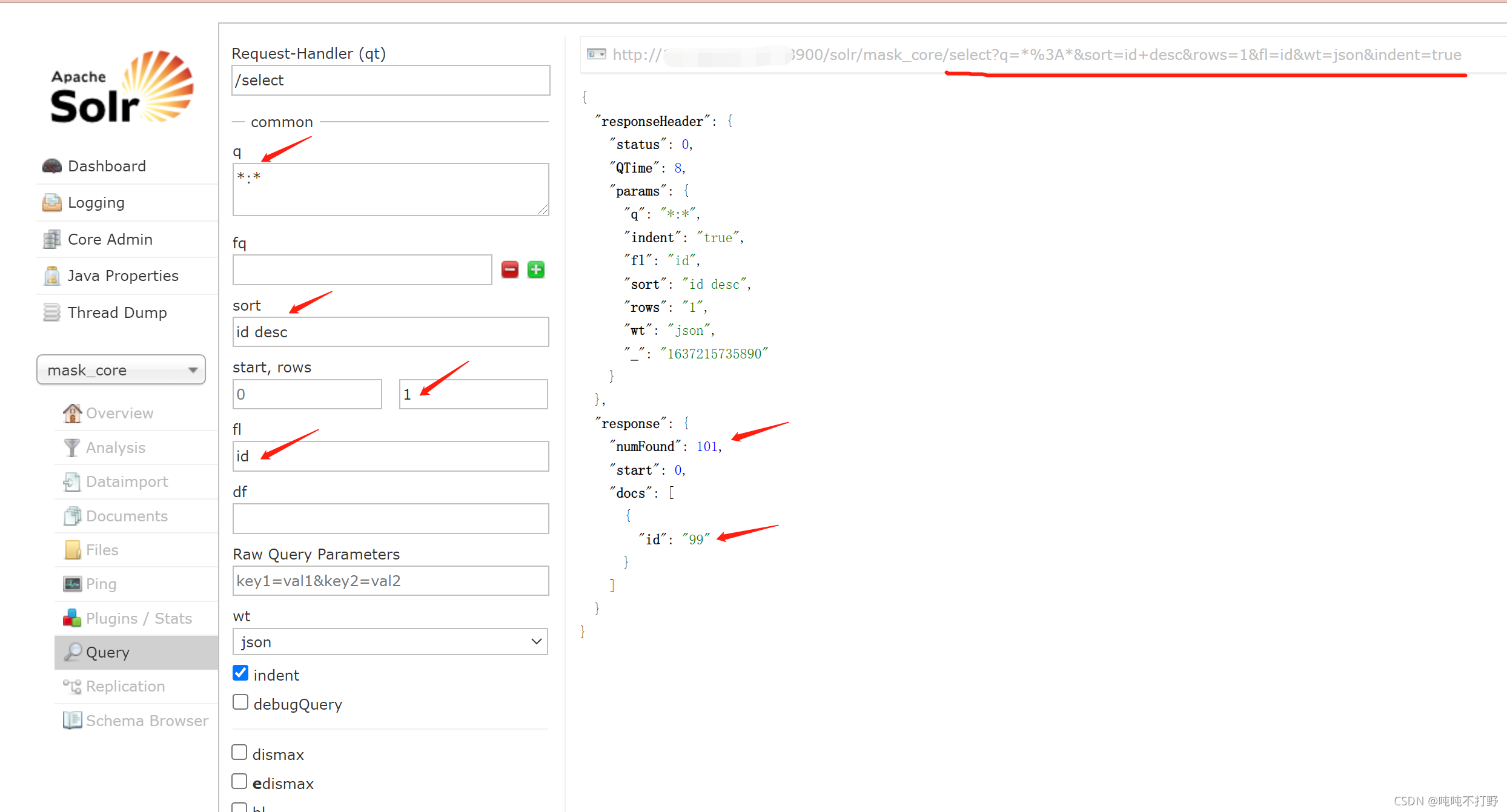
完整的请求url是:
url=http://XXX:8900/solr/mask_core/select?q=*%3A*&sort=id+desc&rows=1&fl=id&wt=json&indent=true
"""
q *:*
sort id空格desc(降序,asc 升序)
fl filed list 显示结果的哪一个域(哪一列属性)
"""
但是这里存在一个很奇怪的问题,也得亏我这个faq集超过100了,不然都遇不到这个bug。。。

- 所以这里id是一个字符串,没有办法直接按照数字的大小去排序。。。所以才会出现上面按照降序,结果最大的是99,而不是101的情况。
- 所以说solr不像mysql那些一样,提供了聚集函数,可以进行一些统计比较。。
- 所以不能指望排序了
但是其实不难注意到,response对象中有一个numFound参数,刚好就是当前solr_core中文档的数量。。。
参考:Stack Overflow Solr/Solrj: How can I determine the total number of documents in an index?
大部分都是进行最直接的q=*:*查询,然后取出返回值中的num_Found,类似:
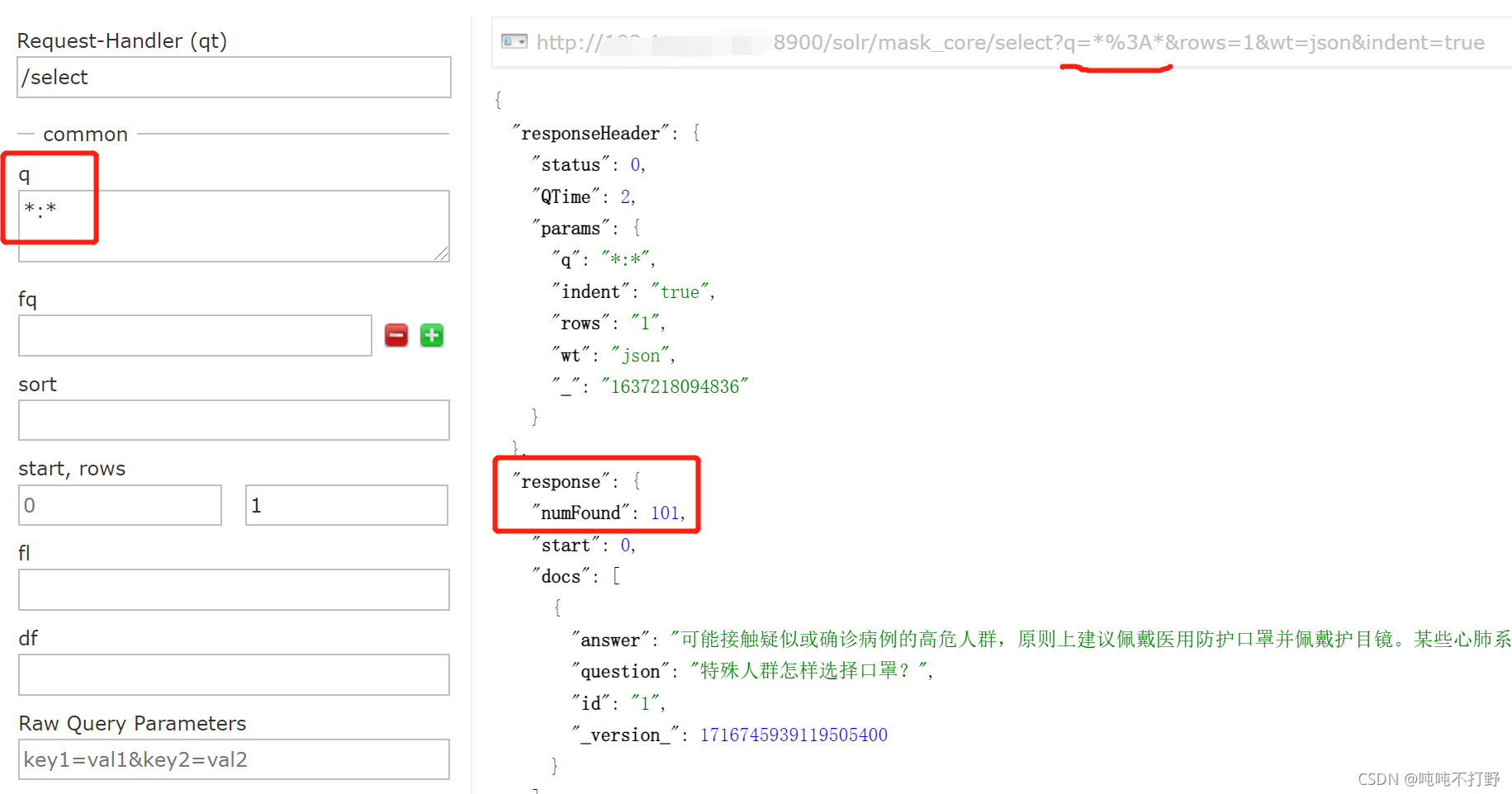
最终整体的代码:
def get_id():
url="http://192.168.20.137:8900/solr/mask_core/select"
param={"q":"*:*","rows":1,"wt":"json","indent":"true"}
res = requests.get(url,params=param)
id=res.json()['response']['numFound']
return int(id)
current_id=get_id()
但是这种方式会有一个问题。。。
- 如果不小心执行两次,但是内容相同,id不同,这条语句同样也会被插入,solr不会对问题和答案是否重复进行检查。。
- 同时如果手动删除其中一个重复内容,后面的id并不会跟着改变。。
- 这样的话,假如id=103和id=104的内容是重复的,我删除了id=103,那么此时num_Found其实是103,也就是说FAQ集有103个问答对,但是此时id其实是从104开始的。。。
- 所以最好不要删除faq问答对,或者可以在本地文件或者哪里存一个永远正确的最后一个id的序号。。
1.3 删除文档
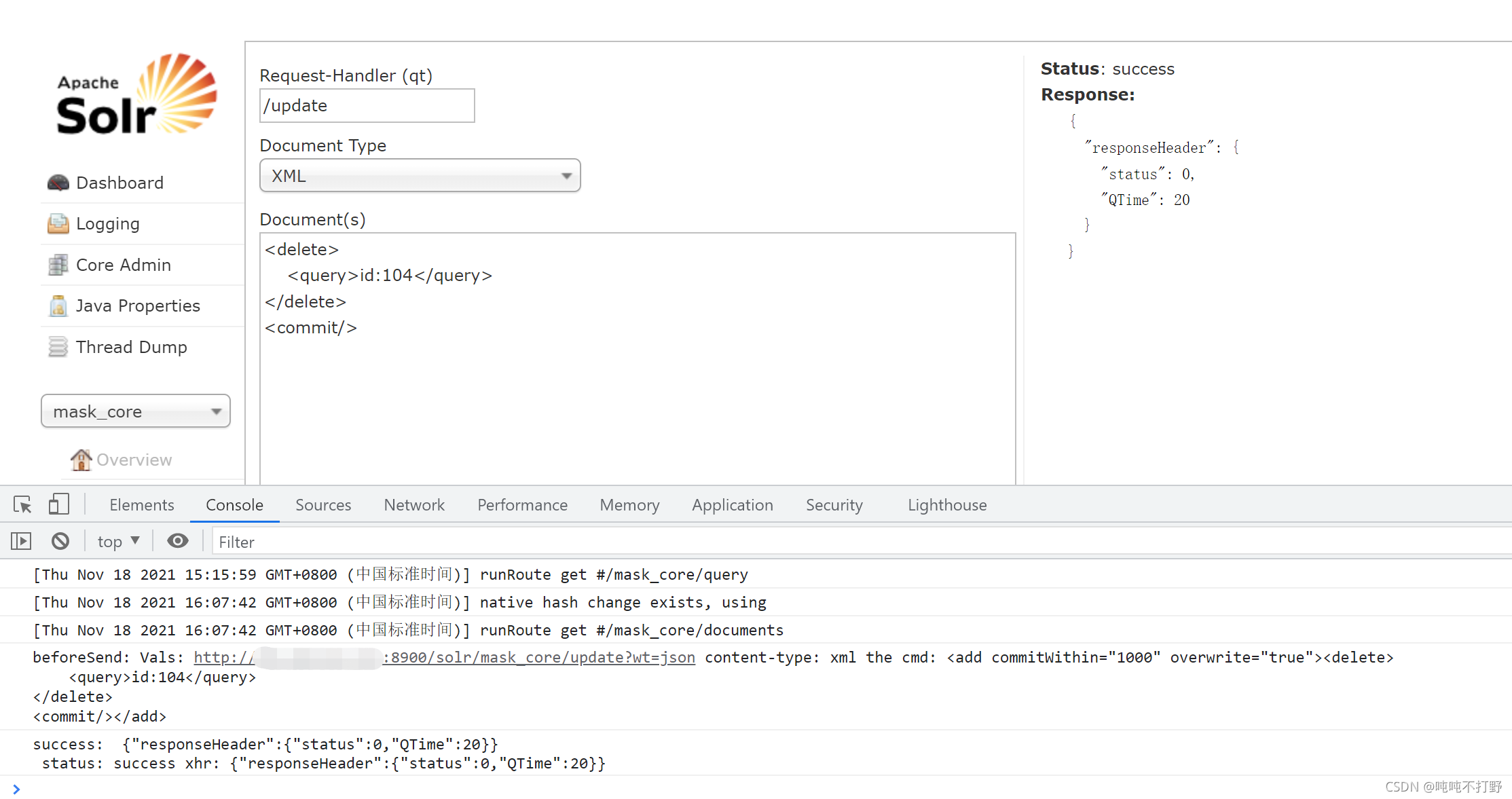
其实和上传差不多,就是content-type变成了XML
1.4 maxdoc和numdoc
参考:
- Difference between “Num Docs” and “Max Doc” in Solr
- (五)Lucene中maxDoc 和numDocs()方法的区别
- solr中numDocs和maxDoc的区别
并没有得到一个很好的答案,还是很模糊。
1.5 检索
其实删除里用的检索就是这个
2 anyq封装后的接口
在文件\AnyQ\tools\solr\solr_api.py中,可以看到以下内容:
import sys
import solr_tools
if sys.argv[1] == "add_engine":
solr_tools.add_engine(sys.argv[2], sys.argv[3], sys.argv[4],
shard=1, replica=1, maxshardpernode=5, conf='myconf')
elif sys.argv[1] == "set_schema":
solr_tools.set_engine_schema(sys.argv[2], sys.argv[3], sys.argv[4], sys.argv[5])
elif sys.argv[1] == "delete_engine":
solr_tools.delete_engine(sys.argv[2], sys.argv[3], sys.argv[4])
elif sys.argv[1] == "upload_doc":
solr_tools.upload_documents(sys.argv[2], sys.argv[3], sys.argv[4], sys.argv[5], num_thread=1)
elif sys.argv[1] == "clear_doc":
solr_tools.clear_documents(sys.argv[2], sys.argv[3], sys.argv[4])
进一步,在文件\AnyQ\tools\solr\solr_tools.py中,可以看到以下内容:
所以其实可以通过调用这个文件,去更新接口的。
anyq提供的接口中,
clear函数其实没有很多需要注意的点,其实就相当于在solr界面上执行:"<delete><query>*:*</query></delete>"upload接口是为一次传一个文件的一批设置的,所以有线程和锁。
如果只想每次传一个faq对,直接走solr提供的接口就好了

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)