读取记事本里面的内容,并按照要求存放
读取记事本里面的内容,并按照要求存放代码实现#!/usr/bin/env python# -*- encoding: utf-8 -*-'''@Filename :try.py@Description :@Datatime :2021/11/17 09:58:49@Author :qtxu@Version :v1.0@Function :'''def _read_data(input_file,i
·
读取记事本里面的内容,并按照要求存放
代码实现
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@Filename :try.py
@Description :
@Datatime :2021/11/17 09:58:49
@Author :qtxu
@Version :v1.0
@Function :
'''
def _read_data(input_file,input_par_file):
"""Read a BIO data!"""
"""input_file: contains the original words,labels which formatter is word,O,label"""
""" input_par_file: contains the back-translation words not labels"""
rf = open(input_file,'r')
rf_par = open(input_par_file, 'r')
lines = [];words = [];labels = []
labels_op = []
par_text = []
for line in rf:
# here we dont do "DOCSTART" check
if len(line.strip()) == 0 :
l = ' '.join([label for label in labels if len(label) > 0])
# l_op = ' '.join([label for label in labels_op if len(label) > 0])
w = ' '.join([word for word in words if len(word) > 0])
lines.append((l,w))
words=[]
labels = []
labels_op = []
else:
word = line.strip().split(' ')[0] # the first str is word in the dataset
label = line.strip().split(' ')[-1] # the last str is label in the dataset
# label_op = line.strip().split(' ')[1]
words.append(word)
labels.append(label)
# labels_op.append(label_op)
for line in rf_par:
if (len(line.strip()) != 0):
par_text.append(line.strip())
rf.close()
rf_par.close()
return lines,par_text
if __name__ == "__main__":
input_file="/home/qtxu/BERT-par/data/15res/train.txt"
input_par_file = "/home/qtxu/BERT-par/data/15res/15res_train_par_cut.txt"
lines, par_txt = _read_data(input_file, input_par_file)
print(lines)
print(par_txt)
解读
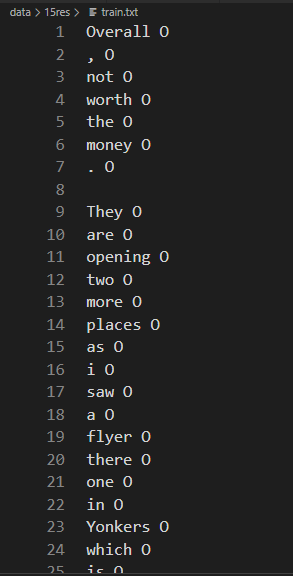
其中,input_file 记事本数据存放格式:
input_par_file 记事本数据存放格式

lines, 数据存放格式

par_txt 数据存放格式


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)