
STM32 HAL us delay(微秒延时)的指令延时实现方式及优化
STM32 HAL us delay(微秒延时)的指令延时实现方式及优化STM32的HAL库,直接提供了1ms延时的实现函数HAL_Delay()。其原理是系统在上电后时钟配置阶段,配置了1ms产生一次中断,然后对一个32位寄存器uwTick逐次加1。HAL_Delay(x)函数执行时,会读取当前的uwTick值,并循环读取不断增加的uwTick值,直到uwTick增加了x后退出循环。要实现us级
STM32 HAL us delay(微秒延时)的指令延时实现方式及优化
STM32的HAL库,直接提供了1ms延时的实现函数HAL_Delay()。其原理是系统在上电后时钟配置阶段,配置了1ms产生一次中断,然后对一个32位寄存器uwTick逐次加1。HAL_Delay(x)函数执行时,会读取当前的uwTick值,并循环读取不断增加的uwTick值,直到uwTick增加了x后退出循环。
要实现us级延时,可以从中断方式进行,如修改系统时钟中断配置,将系统时钟1ms中断改为1us中断,也可以用一个TIM定时器产生1us中断来计数实现1us级延时。但如果系统的业务时序比较紧张,太频繁的中断可能引入某些不良时序风险。在这种情况下,采用指令延时实现1us级延时是一种方式,但是需要注意,指令延时不是时钟延时,并非一个指令延时对应一个时钟延时,通常一个指令周期需要多个时钟周期实现,因此系统时钟的配置频率不同,也会影响一个指令周期的实现时间。采用循环语句进行指令延时的实现时,循环语句里的循环与否判断部分,也会产生指令周期的执行延时,需要综合考虑进去。因此,采用指令延时实现更精确1us级别延时需要进行特殊的设计。本代码采用的初步测定–优化–应用的方式:
us级延时设计
__IO float usDelayBase;
void PY_usDelayTest(void)
{
__IO uint32_t firstms, secondms;
__IO uint32_t counter = 0;
firstms = HAL_GetTick()+1;
secondms = firstms+1;
while(uwTick!=firstms) ;
while(uwTick!=secondms) counter++;
usDelayBase = ((float)counter)/1000;
}
void PY_Delay_us_t(uint32_t Delay)
{
__IO uint32_t delayReg;
__IO uint32_t usNum = (uint32_t)(Delay*usDelayBase);
delayReg = 0;
while(delayReg!=usNum) delayReg++;
}
上面的设计,实现了基本的us级延时函数的设计,分为系数测定函数和延时函数,系数测定函数测定1ms内特定语句的执行次数。其中HAL_GetTick()就是读取uwTick值并作为返回值的函数,和直接调用uwTick一样。

其中,循环执行的语句包含uwTick的读取,secondms的读取,一次不等于的比较,一次counter的加法。退出循环后的counter对应延时1ms时间要执行这种指令类型的次数。usDelayBase则是对应延时1us时间要要执行这种指令类型的次数,暂时以浮点形式表现。
在延时实现函数里,将要延时的us数乘以usDelayBase,得到要执行的特定类型指令的次数。然后执行特定类型指令形式的延时,即下面的方式:

这样,就实现了1us级别的延时。
us级延时设计优化
实际上,上面1us延时的实现,还存在一点小的偏差,可以通过下面的函数设计和执行,对usDelayBase进行进一步校准优化。
void PY_usDelayOptimize(void)
{
__IO uint32_t firstms, secondms;
__IO float coe = 1.0;
firstms = HAL_GetTick();
PY_Delay_us_t(1000000) ;
secondms = HAL_GetTick();
coe = ((float)1000)/(secondms-firstms);
usDelayBase = coe*usDelayBase;
}
上述校正原理是,采用us延时函数延时1000000即1秒,那么对应的系统时钟的1ms延时数理论值是1000,而存在us延时函数偏差累积时,得到的不是1000,这个时候可以产生偏差校正系数coe,从而用coe*usDelayBase得到矫正后的usDelayBase。
us延时函数优化
上述已实现的us延时函数,对1us的延时,已很接近1us,但并非100%等于1us,因此如延时数比较大,如30分钟20秒100毫秒50微秒的延时,就会产生一定的累积时间偏差。对于us级精度又要实现长时间延时,用下面的优化函数,原理是将大于等于1ms的部分,用系统时钟的1ms延时函数代替实现,将小于1ms的微秒部分,用微秒延时函数实现。
void PY_Delay_us(uint32_t Delay)
{
__IO uint32_t delayReg;
__IO uint32_t msNum = Delay/1000;
__IO uint32_t usNum = (uint32_t)((Delay%1000)*usDelayBase);
if(msNum>0) HAL_Delay(msNum);
delayReg = 0;
while(delayReg!=usNum) delayReg++;
}
这样,就保证了长延时和短延时都具有良好的us精度。
另外,HAL库的HAL_Delay()如果没有调整中断优先级,不能用在各中断的中断处理函数中,在没有长延时us级高精度要求情况下,可以把本文中的PY_Delay_us_t()函数用在任意场合包括各中断处理函数中,如PY_Delay_us_t(1000)等同于HAL_Delay(1)的非中断方式实现。
使用方式
- 先定义上述的全局变量usDelayBase和4个函数。
- 在main函数进入while循环之前,执行 PY_usDelayTest(); 和 PY_usDelayOptimize();
- 在需要进行us延时的时候,执行PY_Delay_us(x)或 PY_Delay_us_t(x); 其中x为要延时的微秒数。如执行PY_Delay_us(12) ; 为延时12微秒;PY_Delay_us(1020) ; 为延时1毫秒20微秒。
GPIO驱动注意事项
在利用延时进行GPIO驱动时(譬如定时进行GPIO输出翻转),需要注意GPIO的驱动延时,也即MCU从开始到执行完GPIO的管脚输出驱动有一定延时(几us),在这个延时后才会继续执行后面的代码。因此在采用TIM定时器中断和本方案指令延时驱动GPIO翻转时,就需要注意时序的区别,如果设置成像定时器中断里驱动GPIO翻转一样的延时,则采用指令延时的真实延时会加长,而解决办法就是相应的减少指令延时的时间,图示如下:
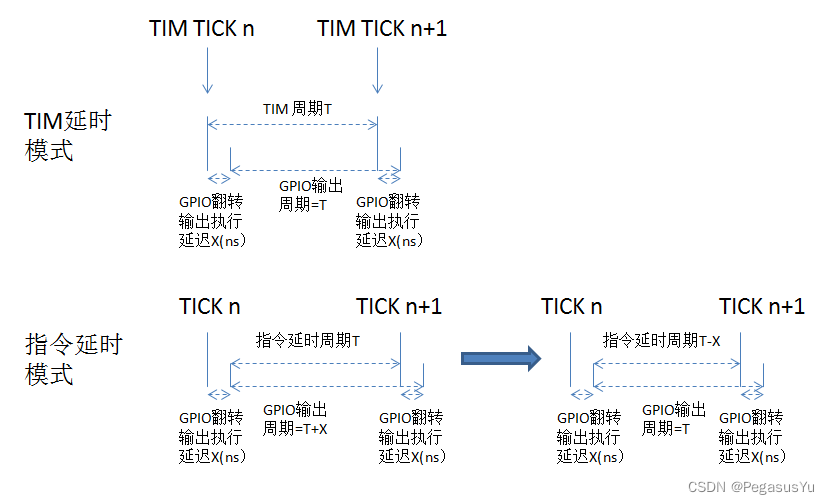
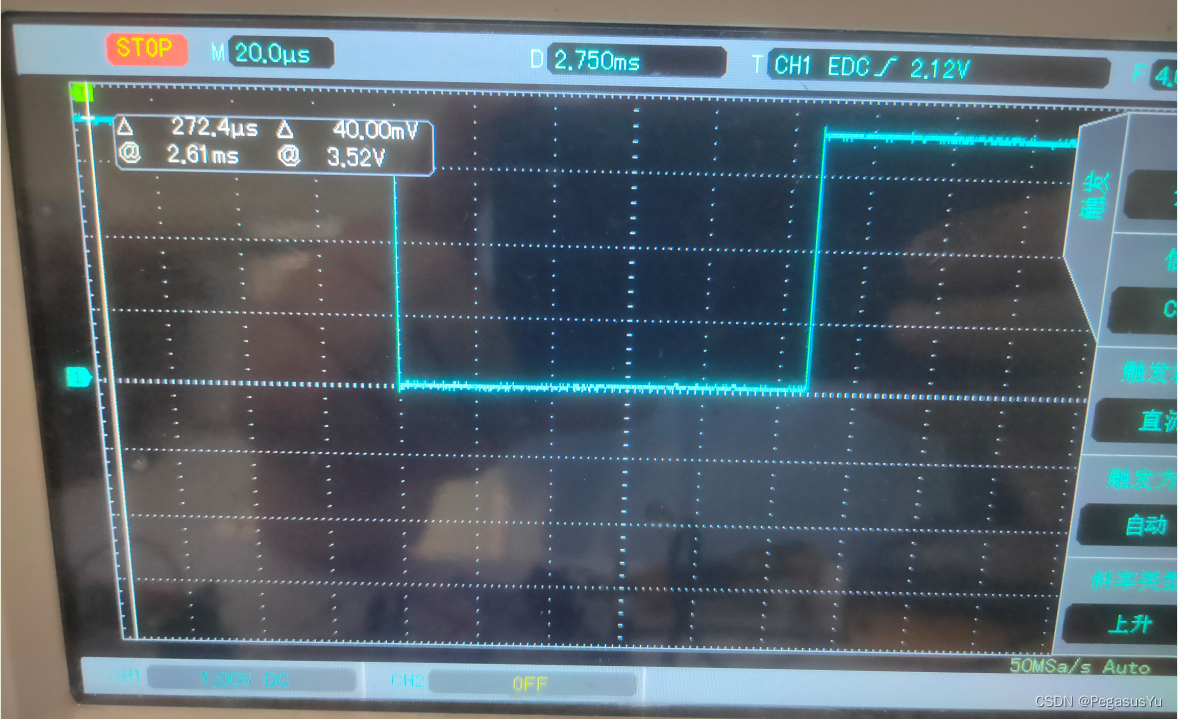
以STM32G030F6P6为例,主频设置为64MHz,驱动100us延时GPIO翻转的波形为:
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_0);
PY_Delay_us_t(100);
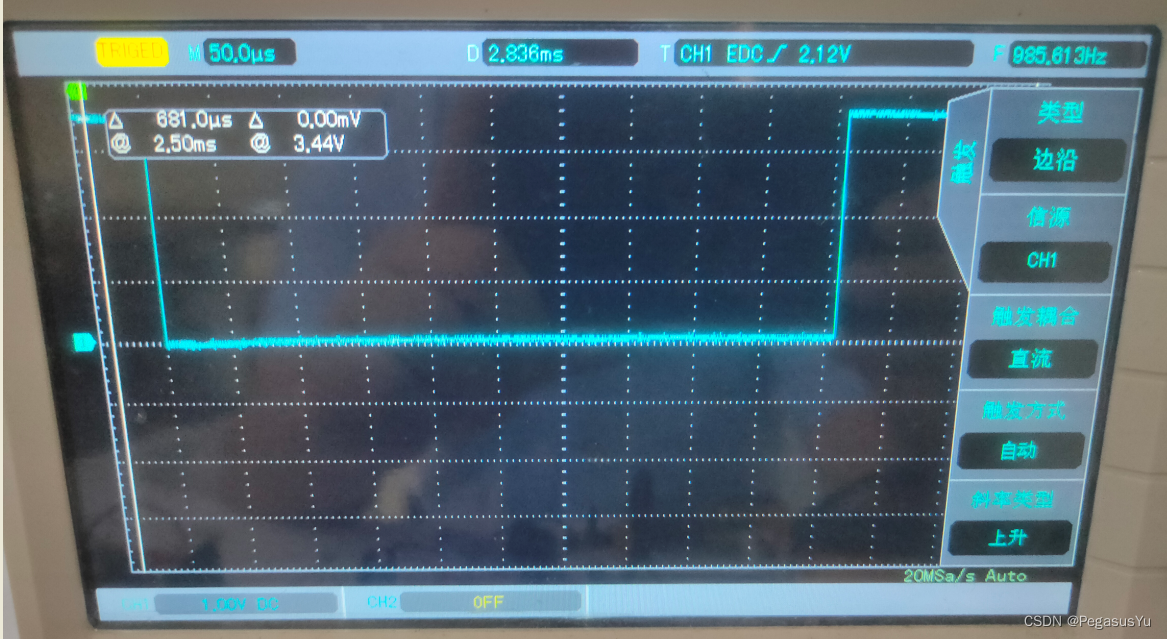
驱动500us延时GPIO翻转的波形为:
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_0);
PY_Delay_us_t(500);
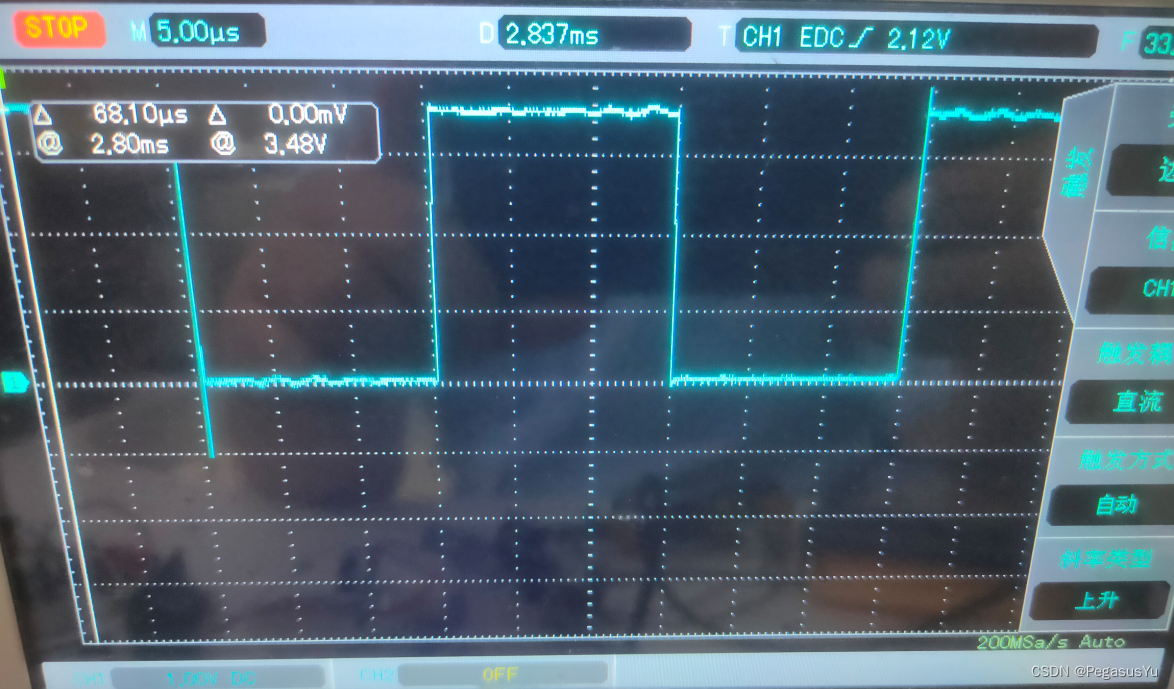
可以看出有一个大约8us的GPIO输出延时,如果想要输出15us的翻转延时,则需要设置延时为15-8=7us:
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_0);
PY_Delay_us_t(7);
波形验证:
易用性及扩展性
- 初始阶段执行 PY_usDelayTest() 和 PY_usDelayOptimize()是为了测得浮点参数值usDelayBase。实际上,如果要节约初始阶段的执行时间,可以单独用一个同样工程环境的测试工程,测试出usDelayBase,然后在正式工程中将usDelayBase定义为常量,则使用PY_Delay_us(x)或 PY_Delay_us_t(x)前不再产生初始阶段的时间占用,不需要定义和调用PY_usDelayTest()和 PY_usDelayOptimize()。 PY_Delay_us_t(x)的方式也应用于UCOS, FREE-RTOS, RT-THREAD等嵌入式操作系统的微秒延时实现,不受操作系统接管时钟系统的影响。为了避免操作系统调度打断延时过程,还可用__disable_irq()与__enable_irq()来保护延时过程PY_Delay_us_t(x)的执行精度。
- 在主频高的情况下,指令延时的规格精度可以继续升级,譬如半微秒级(semi-us)延时的函数设计就可以如下代码实现:
__IO float semiusDelayBase;
void PY_semiusDelayTest(void)
{
__IO uint32_t firstms, secondms;
__IO uint32_t counter = 0;
firstms = HAL_GetTick()+1;
secondms = firstms+1;
while(uwTick!=firstms) ;
while(uwTick!=secondms) counter++;
semiusDelayBase = ((float)counter)/2000;
}
void PY_Delay_semius_t(uint32_t Delay)
{
__IO uint32_t delayReg;
__IO uint32_t semiusNum = (uint32_t)(Delay*semiusDelayBase);
delayReg = 0;
while(delayReg!=semiusNum) delayReg++;
}
void PY_semiusDelayOptimize(void)
{
__IO uint32_t firstms, secondms;
__IO float coe = 1.0;
firstms = HAL_GetTick();
PY_Delay_semius_t(2000000) ;
secondms = HAL_GetTick();
coe = ((float)1000)/(secondms-firstms);
semiusDelayBase = coe*semiusDelayBase;
}
void PY_Delay_semius(uint32_t Delay)
{
__IO uint32_t delayReg;
__IO uint32_t msNum = Delay/2000;
__IO uint32_t semiusNum = (uint32_t)((Delay%2000)*semiusDelayBase);
if(msNum>0) HAL_Delay(msNum);
delayReg = 0;
while(delayReg!=semiusNum) delayReg++;
}
使用方式一致,通过执行 PY_semiusDelayTest(); 和 PY_semiusDelayOptimize();获得浮点参数值semiusDelayBase,就可以通过PY_Delay_semius(x)或 PY_Delay_semius_t(x)调用半微秒精度延时,如PY_Delay_semius_t(3)为延迟1.5微秒。
–End–

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)