普罗米修斯容器化监控、PromQL的使用、Grafana添加普罗米修斯数据源模板
一、普罗米修斯容器化普罗米修斯容器化就是在kubernetes中安装。#1.下载普罗米修斯配置清单[root@k8s-master-01 ~]# git clone -b release-0.5 --single-branch https://github.com/prometheus-operator/kube-prometheus.git正克隆到 'kube-prometheus'...rem
·
一、普罗米修斯容器化
普罗米修斯容器化就是在kubernetes中安装。
#1.下载普罗米修斯配置清单
[root@k8s-master-01 ~]# git clone -b release-0.5 --single-branch https://github.com/prometheus-operator/kube-prometheus.git
正克隆到 'kube-prometheus'...
remote: Enumerating objects: 8081, done.
remote: Counting objects: 100% (32/32), done.
remote: Compressing objects: 100% (25/25), done.
remote: Total 8081 (delta 9), reused 14 (delta 5), pack-reused 8049
接收对象中: 100% (8081/8081), 4.61 MiB | 1.67 MiB/s, done.
处理 delta 中: 100% (4885/4885), done.
#一定要先执行/setup/里面的yaml文件,要不然服务器就会起不来
[root@k8s-master-01 ~]# cd kube-prometheus/manifests/setup/
[root@k8s-master-01 setup]# kubectl apply -f ./
#2.查看
[root@gdx1 setup]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-848d669f6d-wpmdp 2/2 Running 0 85s
#3.部署普罗米修斯
[root@k8s-master-01 setup]# cd ..
[root@k8s-master-01 manifests]# pwd
/root/kube-prometheus/manifests
[root@k8s-master-01 manifests]# kubectl apply -f ./
[root@k8s-master-01 manifests]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 15m
alertmanager-main-1 2/2 Running 0 15m
alertmanager-main-2 2/2 Running 0 15m
grafana-5d9d5f67c4-5rxjl 1/1 Running 0 15m
kube-state-metrics-7fddf8779f-p45wx 3/3 Running 0 15m
node-exporter-bw5fp 2/2 Running 0 15m
node-exporter-n4dgm 2/2 Running 0 15m
node-exporter-w6pzz 2/2 Running 0 15m
prometheus-adapter-cb548cdbf-6cmdw 1/1 Running 0 15m
prometheus-k8s-0 3/3 Running 1 15m
prometheus-k8s-1 3/3 Running 1 15m
prometheus-operator-6478d8fc6d-x5w9l 2/2 Running 0 16m
[root@k8s-master-01 manifests]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.106.104.168 <none> 80:32146/TCP,443:32516/TCP 4d
ingress-nginx-controller-admission ClusterIP 10.98.140.148 <none> 443/TCP 4d
[root@k8s-master-01 manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.110.81.241 <none> 9093/TCP 15m
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 15m
grafana ClusterIP 10.111.57.238 <none> 3000/TCP 15m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 15m
node-exporter ClusterIP None <none> 9100/TCP 15m
prometheus-adapter ClusterIP 10.105.251.120 <none> 443/TCP 15m
prometheus-k8s ClusterIP 10.99.136.60 <none> 9090/TCP 15m
prometheus-operated ClusterIP None <none> 9090/TCP 15m
prometheus-operator ClusterIP None <none> 8443/TCP 17m
#4.做域名解析
[root@k8s-master-01 manifests]# vim prometheus-ingress.yaml
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: prometheus-k8s
namespace: monitoring
spec:
rules:
- host: "www.prometheus-k8s.monitoring.cluster.local.com"
http:
paths:
- backend:
serviceName: prometheus-k8s
servicePort: 9090
path: /
---
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: grafana
namespace: monitoring
spec:
rules:
- host: "www.grafana.monitoring.cluster.local.com"
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
path: /
[root@k8s-master-01 manifests]# kubectl apply -f prometheus-ingress.yaml
[root@k8s-master-01 manifests]# kubectl get pods -n monitoring #所有全都running状态
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 41m
alertmanager-main-1 2/2 Running 0 41m
alertmanager-main-2 2/2 Running 0 41m
grafana-5d9d5f67c4-94xp6 1/1 Running 0 41m
kube-state-metrics-7fddf8779f-8gjl5 3/3 Running 0 41m
node-exporter-9k288 2/2 Running 0 41m
node-exporter-fkvh4 2/2 Running 0 41m
node-exporter-v2ztd 2/2 Running 0 41m
prometheus-adapter-cb548cdbf-pm6f9 1/1 Running 0 41m
prometheus-k8s-0 3/3 Running 1 41m
prometheus-k8s-1 3/3 Running 1 36s
prometheus-operator-848d669f6d-wpmdp 2/2 Running 0 47m
[root@k8s-master-01 manifests]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.106.104.168 <none> 80:32146/TCP,443:32516/TCP 4d1h
ingress-nginx-controller-admission ClusterIP 10.98.140.148 <none> 443/TCP 4d1h
#5.配置主机host文件,浏览器访问
192.168.15.33 www.grafana.monitoring.cluster.local.com www.prometheus-k8s.monitoring.cluster.local.com


二、PromQL
普罗米修斯官网连接:Query functions | Prometheus
https://prometheus.io/docs/prometheus/latest/querying/functions/
QL顾名思义,Query language即查询语言。Prometheus作为强大的开源监控系统,最大的依赖便是PromQL。是监控数据个性化查询、展示的基础。所以要掌握Prometheus,掌握PromQL是必备的前提。
- 瞬时向量:包含该时间序列中最新的⼀个样本值
- 区间向量:⼀段时间范围内的数据
1.简单运算
1)查询5分钟以内数据
http_request_total[5m]

#1.在主节点查看解析的域名
[root@k8s-master-01 manifests]# kubectl run test -it --rm --image=busybox:1.28.3
If you don't see a command prompt, try pressing enter.
/ # nslookup prometheus-k8s.monitoring
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: prometheus-k8s.monitoring
Address 1: 10.110.249.255 prometheus-k8s.monitoring.svc.cluster.local
#2.将http://prometheus-k8s.monitoring.svc.cluster.local:9090填入下图位置
在grafana添加普罗米修斯数据源


2)查询30分钟之前5分钟之内的数据
offset:查看多少分钟之前的数据

3)等于查询
=:等于查询
4)不等于查询
!=:不等于查询
5)正则匹配
=~:正则匹配
6)正则取反
!~:正则取反
7)计算服务器内存空闲率



[root@k8s-master-01 manifests]# free -m
total used free shared buff/cache available
Mem: 3155 1846 137 18 1170 1413
Swap: 0 0 0
[root@k8s-master-01 manifests]# free -m
total used free shared buff/cache available
Mem: 1963 1205 71 109 686 714
Swap: 0 0 0
[root@k8s-master-01 manifests]# free -m
total used free shared buff/cache available
Mem: 1963 834 92 21 1035 1110
Swap: 0 0 0

#s:seconds 秒
#m:minutes 分
#h:hours 时
#d:days 天
#w:weeks 周
#y:years 年


2.聚合函数
1)逻辑运算
and:和
or:或
unless:排除
2)函数运算
sum:求和运算
min:最小值
max:最大值
avg:平均数
3)标准差:stddev


4)标准方差:stdvar

5)统计总个数:count

6)分类计算个数:count_volues

7)求某个位置上的数:quantile [0-1之间]

8)获取最小的两个值:bottomk

9)获取最大的两个值:topk

3.二进制运算符优先级
^
*,/,%
+, -
==,!=,<=,<,>=,>
and, unless
or
4.特殊查询
1)查询某个字段的个数
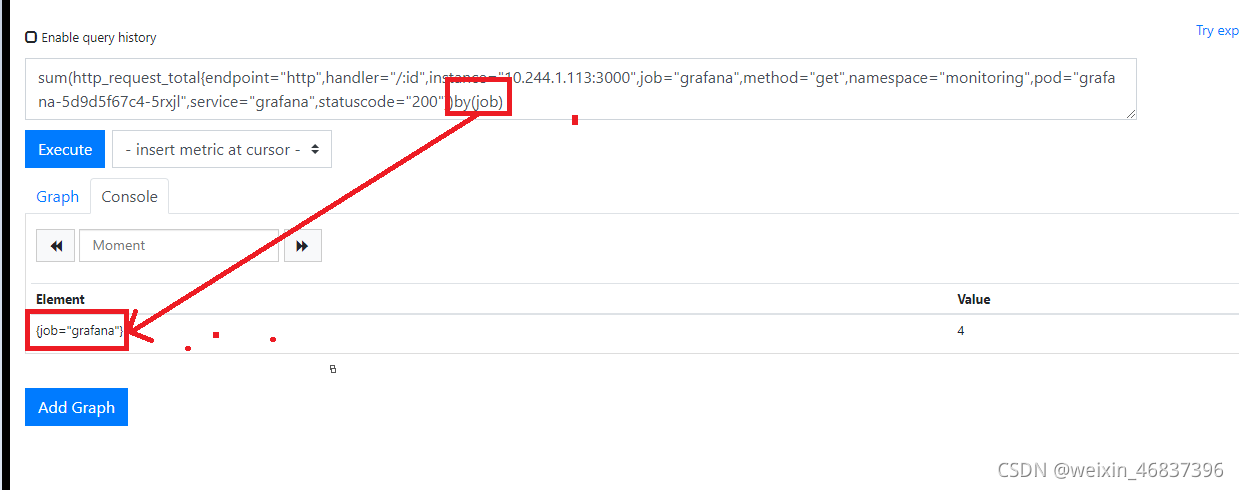
sum(http_request_total)by(job)

2)计算范围向量中时间序列的增加
#返回过去 5 分钟内测量的 HTTP 请求数量
increase(http_requests_total{job="api-server"}[5m])
3)计算范围向量中时间序列的每秒平均平均增长率
#返回过去 5 分钟内测量的 HTTP 请求的每秒速率
rate(http_requests_total{job="api-server"}[5m])
4)计算射程矢量中时间系列的每秒即时增长率
#返回 HTTP 请求的每秒速率,该请求在范围矢量中每个时间系列中查找两个最新的数据点最多 5 分钟
irate(http_requests_total{job="api-server"}[5m])
5)基于范围向量预测从现在开始到某个时间的资源消耗情况
#基于1天的数据推算未来4天的数据(使用简单的线性回归)
predict_linear(node_filesystem_files[1d],4*3600*24)
5.排序
1)升序

2)降序

3)创建一个新字段

6.四舍五入


三、Grafana添加普罗米修斯数据源模板
官网:https://grafana.com/grafana/dashboards



为了简单的话直接copy id to clipboard 如图所示:




补充
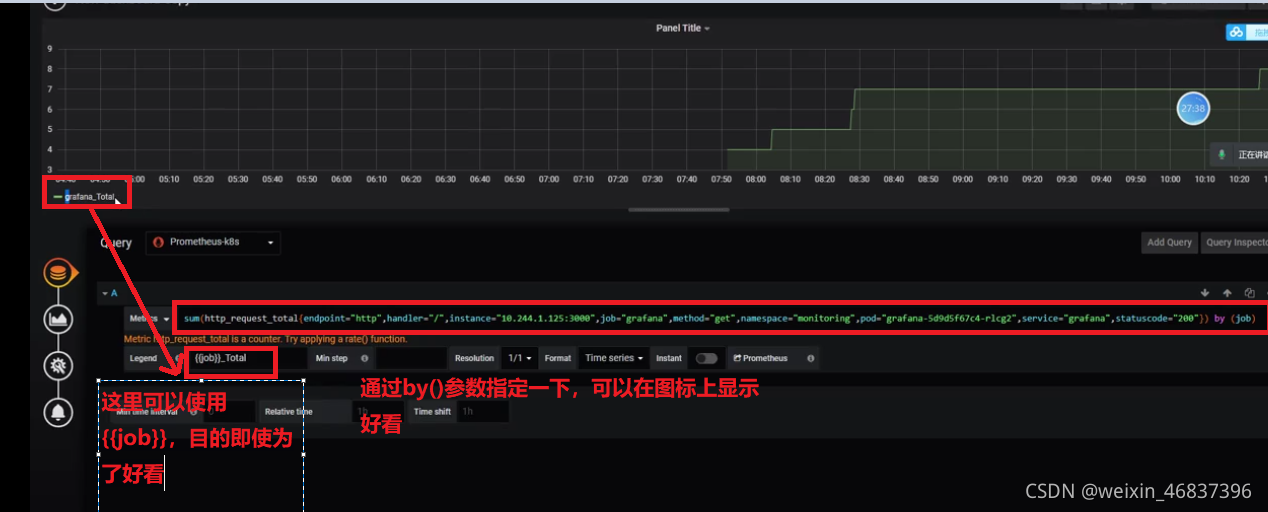
sum(http_request_total{endpoint="http",handler="/:id",instance="10.244.1.113:3000",job="grafana",method="get",namespace="monitoring",pod="grafana-5d9d5f67c4-5rxjl",service="grafana",statuscode="200"})by(job)
```

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 1
1 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)