
Prometheus监控docker容器
@Prometheus(普罗米修斯)监控Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区 。使用prometheus的特性易管理性Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储不依赖分布式存储,单服务器节点是自治的高
@
Prometheus(普罗米修斯)监控
Prometheus是最初在SoundCloud上构建的开源系统监视和警报工具包 。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发人员和用户社区 。
使用prometheus的特性
- 易管理性
Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储
-
不依赖分布式存储,单服务器节点是自治的
-
高效
单一Prometheus可以处理数以百万的监控指标;每秒处理数十万
的数据点
-
易于伸缩
Prometheus提供多种语言 的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中
-
通过服务发现或静态配置发现目标
-
良好的可视化
除了自带的可视化web界面,还有另外最新的Grafana可视化工具也提供了完整的Proetheus支持,基于 Prometheus提供的API还可以实现自己的监控可视化UI
docker搭建prometheus监控
环境:
- 全部关闭防火墙,禁用selinux
| 主机 | IP | 安装组件 |
|---|---|---|
| machine | 172.16.46.111 | NodeEXporter、cAdvisor、 Prometheus Server、Grafana |
| node01 | 172.16.46.112 | NodeEXporter、cAdvisor |
| node02 | 172.16.46.113 | NodeEXporter、cAdvisor |
安装prometheus组件说明:
Prometheus Server:普罗米修斯的主服务器,端口号9090
NodeEXporter:负责收集Host硬件信息和操作系统信息,端口号9100
cAdvisor:负责收集Host上运行的容器信息,端口号占用8080
Grafana:负责展示普罗米修斯监控界面,端口号3000
altermanager:等待接收prometheus发过来的告警信息,altermanager再发送给定义的收件人
部署node-EXporter,收集硬件和系统信息
#3台主机都要安装
docker run -d -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
PS:注意,为了网络的高效率,我们的网络使用的是host
验证收集效果

部署安装cAdvisor,收集节点容器信息
#3台都要安装
docker run -v /:/rootfs:ro -v /var/run:/var/run/:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisor
验证收集效果传递
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tH4l32UL-1629090497750)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1597400808355.png)]](https://img-blog.csdnimg.cn/b493be59745f4f8fa40e4b355fdd9adb.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzgxNTE0MA==,size_16,color_FFFFFF,t_70)
部署prometheus-server服务
先启动一个prometheus服务,目的是复制他的配置文件,修改配置文件,prometheus挂载这个文件
mkdir /prometheus
docker run -d --name test -P prom/prometheus
docker cp test:/etc/prometheus/prometheus.yml /prometheus
#编辑prometheus配置文件,在static_configs下面修改为
#以下添加的ip都将会被监控起来
- targets: ['localhost:9090','localhost:8080','localhost:9100','172.16.46.112:8080','172.16.46.112:9100','172.16.46.113:8080','172.16.46.113:9100']
重新运行prometheus服务
收集cAdvisor和nodexporter的信息到prometheus
docker rm -f test
docker run -d --name prometheus --net host -p 9090:9090 -v /prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
访问测试
进入首页会看到


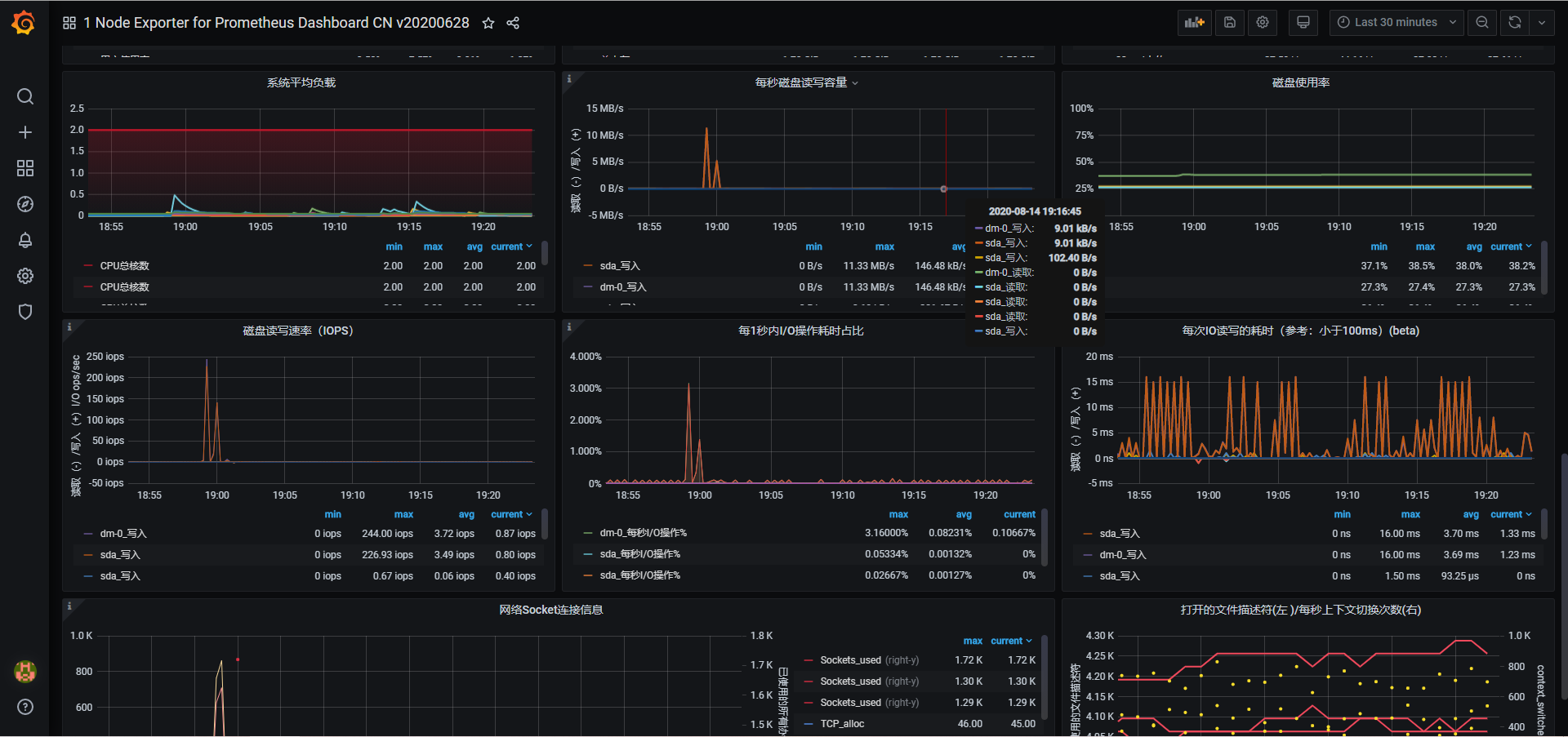
在这里会出现简单的图形展示,和显然,这样看的话还得根据条件筛选着看,而且界面很简单,所以我们还要接入grafana

在prometheus服务器上部署grafana
grafana主要概念
- 插件:扩展功能作用,完成不能完成的事
- 数据源:连接数据源,通过数据源提供数据 来出图
- dashboard:展示面板,出什么样的图
grafana在zabbix应用参考: https://blog.csdn.net/weixin_43815140/article/details/106109605
部署grafana
mkdir /grafana
chmod 777 -R /grafana
docker run -d -p 3000:3000 --name grafana -v /grafana:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=123.com" grafana/grafana

访问测试
默认的用户名和密码:
username:admin
password:123.com

登录进去,添加数据源

连接prometheus

点击save&test开始开始连接

看到以上说明连接成功,不过还需要dashboard来展示图案
prometheus提供3种自带的方案

import后看一下效果

看起来效果比原来好的太多了,不过
grafana官网提供了更多的模板让我们选择 官网模板根据我们的需求可以在官网挑选一款合适自己环境的模板不是很难。

导入模板的2种方式
- 下载JSON文件到本地,uoload上传导入
- 直接输入ID,load就会自动加载到这个模板

我们就导入上面的模板为例


小微调试以后,会出现

不过这只是监控的宿主机资源信息,如果我们想看docker容器的信息
在官网查找与docker有关的模板导入并使用
找到一款全部适合的(ID:11600)


配置Alertmanager报警
启动 AlertManager 来接受 Prometheus 发送过来的报警信息,并执行各种方式的报警。
alertmanager与prometheus工作流程如下

- prometheus收集监测的信息
- prometheus.yml文件定义rules文件,rules里包括了告警信息
- prometheus把报警信息push给alertmanager ,alertmanager里面有定义收件人和发件人
- alertmanager发送文件给邮箱或微信
告警等级

同样以 Docker 方式启动 AlertManager
同prometheus一样,先启动一个test容器,拷贝下来alertmanager的配置文件
mkdir /alertmanager
docker run -d --name test -p 9093:9093 prom/alertmanager
docker cp test:/etc/alertmanager/alertmanager.yml /alertmanager
cp alertmanager.yml alertmanager.yml.bak
AlertManager 默认配置文件为 alertmanager.yml,在容器内路径为
/etc/alertmanager/alertmanager.yml
这里 AlertManager 默认启动的端口为 9093,启动完成后,浏览器访问http://:9093 可以看到默认提供的 UI 页面,不过现在是没有任何告警信息的,因为我们还没有配置报警规则来触发报警

配置alertmanager邮箱报警
查看alertmanager的配置文件

简单介绍一下主要配置的作用:简单介绍一下主要配置的作用:
global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
inhibit_rules: 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的报警(目标)。
配置邮箱报警,首先我们邮箱需要开启SMTP服务,并获取唯一标识码



编辑alertmanager.yml文件
编辑报警媒介等相关信息
global:
resolve_timeout: 5m
smtp_from: 'Sunny_lzs@foxmail.com' #定义发送的邮箱
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: 'Sunny_lzs@foxmail.com'
smtp_auth_password: 'iwxrdwmdgofdbbdc'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'Sunny_lzs@foxmail.com' #定义接收的邮箱
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
重启alertmanager容器
docker rm -f test
docker run -d --name alertmanager -p 9093:9093 -v /alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager

prometheus添加alertmanager报警规则
接下来,我们需要在 Prometheus 配置 AlertManager 服务地址以及告警规则,新建报警规则文件 node-up.rules 如下
mkdir /prometheus/rules
cd /prometheus/rules
vim node-up.rules
groups:
- name: node-up
rules:
- alert: node-up
expr: up{job="prometheus"} == 0
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"

修改prometheus.yml文件,添加rules规则

PS:这里 rule_files 为容器内路径,需要将本地 node-up.rules 文件挂载到容器内指定路径,修改 Prometheus 启动命令如下,并重启服务。
docker rm -f prometheus
docker run -d --name prometheus -p 9090:9090 -v /prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /prometheus/rules:/usr/local/prometheus/rules --net host prom/prometheus
在prometheus上查看相应的规则

触发报警发送邮件
关掉其中一个服务就ok
[root@docker02 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8d1cc177b58e google/cadvisor "/usr/bin/cadvisor -…" 4 hours ago Up 4 hours cadvisor
b2417dbd850f prom/node-exporter "/bin/node_exporter …" 4 hours ago Up 4 hours gallant_proskuriakova
[root@docker02 ~]# docker stop 8d1cc177b58e
8d1cc177b58e
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LVtZrbJC-1629090497787)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1597414593884.png)]](https://img-blog.csdnimg.cn/06e834e55ed54fe8af7982574d936bb4.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzgxNTE0MA==,size_16,color_FFFFFF,t_70)
查看邮件

Alertmanager自定义邮件报警
上面虽然已经可以做出报警,但是我们想让报警信息更加直观一些
alertmanager支持自定义邮件模板的
首先新建一个模板文件 email.tmpl
mkdir /alertmanager/template
vim email.tmpl
{{ define "email.from" }}Sunny_lzs@foxmail.com{{ end }}
{{ define "email.to" }}Sunny_lzs@foxmail.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert<br>
告警级别: {{ .Labels.severity }} 级<br>
告警类型: {{ .Labels.alertname }}<br>
故障主机: {{ .Labels.instance }}<br>
告警主题: {{ .Annotations.summary }}<br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
修改alertmanager文件

重建altermanager
[root@docker01 ~]# docker rm -f alertmanager
[root@docker01 ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /alertmanager/template:/etc/alertmanager-tmpl prom/alertmanager
测试

PS:模板里面的{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}是我们添加东八区时间以后的样子.
扩展案例:添加主机CPU,内存,磁盘等报警监控规则
recording_rules规则: 记录规则允许您预先计算经常需要的或计算开销较大的表达式,并将它们的结果保存为一组新的时间序列。查询预先计算的结果通常比每次需要执行原始表达式时要快得多
alert_rules规则: 警报规则允许您基于Prometheus表达式语言表达式定义警报条件,并向外部服务发送关于触发警报的通知
PS: 记录和警报规则的名称必须是有效的指标名称
因为我们已经定义了规则存放在/prometheus/rules/*.rules结尾的文件
所以,我们可以把所有的规则写到这里
在prometheus.yml同级目录下创建两个报警规则配置文件node-exporter-record-rule.yml,node-exporter-alert-rule.yml。第一个文件用于记录规则,第二个是报警规则。
#prometheus关于报警规则配置
rule_files:
- "/usr/local/prometheus/rules/*.rules"
PS:*.rules里面的job一定要与prometheus里面对应
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'node-exporter'
添加记录
#关于node-exporter-record.rules
groups:
- name: node-exporter-record
rules:
- expr: up{job="node-exporter"}
record: node_exporter:up
labels:
desc: "节点是否在线, 在线1,不在线0"
unit: " "
job: "node-exporter"
- expr: time() - node_boot_time_seconds{}
record: node_exporter:node_uptime
labels:
desc: "节点的运行时间"
unit: "s"
job: "node-exporter"
##############################################################################################
# cpu #
- expr: (1 - avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:total:percent
labels:
desc: "节点的cpu总消耗百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[5m]))) * 100
record: node_exporter:cpu:idle:percent
labels:
desc: "节点的cpu idle百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="iowait"}[5m]))) * 100
record: node_exporter:cpu:iowait:percent
labels:
desc: "节点的cpu iowait百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="system"}[5m]))) * 100
record: node_exporter:cpu:system:percent
labels:
desc: "节点的cpu system百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="user"}[5m]))) * 100
record: node_exporter:cpu:user:percent
labels:
desc: "节点的cpu user百分比"
unit: "%"
job: "node-exporter"
- expr: (avg by (environment,instance) (irate(node_cpu_seconds_total{job="node-exporter",mode=~"softirq|nice|irq|steal"}[5m]))) * 100
record: node_exporter:cpu:other:percent
labels:
desc: "节点的cpu 其他的百分比"
unit: "%"
job: "node-exporter"
##############################################################################################
##############################################################################################
# memory #
- expr: node_memory_MemTotal_bytes{job="node-exporter"}
record: node_exporter:memory:total
labels:
desc: "节点的内存总量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:free
labels:
desc: "节点的剩余内存量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:used
labels:
desc: "节点的已使用内存量"
unit: byte
job: "node-exporter"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemAvailable_bytes{job="node-exporter"}
record: node_exporter:memory:actualused
labels:
desc: "节点用户实际使用的内存量"
unit: byte
job: "node-exporter"
- expr: (1-(node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:used:percent
labels:
desc: "节点的内存使用百分比"
unit: "%"
job: "node-exporter"
- expr: ((node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:free:percent
labels:
desc: "节点的内存剩余百分比"
unit: "%"
job: "node-exporter"
##############################################################################################
# load #
- expr: sum by (instance) (node_load1{job="node-exporter"})
record: node_exporter:load:load1
labels:
desc: "系统1分钟负载"
unit: " "
job: "node-exporter"
- expr: sum by (instance) (node_load5{job="node-exporter"})
record: node_exporter:load:load5
labels:
desc: "系统5分钟负载"
unit: " "
job: "node-exporter"
- expr: sum by (instance) (node_load15{job="node-exporter"})
record: node_exporter:load:load15
labels:
desc: "系统15分钟负载"
unit: " "
job: "node-exporter"
##############################################################################################
# disk #
- expr: node_filesystem_size_bytes{job="node-exporter" ,fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:total
labels:
desc: "节点的磁盘总量"
unit: byte
job: "node-exporter"
- expr: node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:free
labels:
desc: "节点的磁盘剩余空间"
unit: byte
job: "node-exporter"
- expr: node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"} - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"}
record: node_exporter:disk:usage:used
labels:
desc: "节点的磁盘使用的空间"
unit: byte
job: "node-exporter"
- expr: (1 - node_filesystem_avail_bytes{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:disk:used:percent
labels:
desc: "节点的磁盘的使用百分比"
unit: "%"
job: "node-exporter"
- expr: irate(node_disk_reads_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:read:count:rate
labels:
desc: "节点的磁盘读取速率"
unit: "次/秒"
job: "node-exporter"
- expr: irate(node_disk_writes_completed_total{job="node-exporter"}[1m])
record: node_exporter:disk:write:count:rate
labels:
desc: "节点的磁盘写入速率"
unit: "次/秒"
job: "node-exporter"
- expr: (irate(node_disk_written_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:read:mb:rate
labels:
desc: "节点的设备读取MB速率"
unit: "MB/s"
job: "node-exporter"
- expr: (irate(node_disk_read_bytes_total{job="node-exporter"}[1m]))/1024/1024
record: node_exporter:disk:write:mb:rate
labels:
desc: "节点的设备写入MB速率"
unit: "MB/s"
job: "node-exporter"
##############################################################################################
# filesystem #
- expr: (1 -node_filesystem_files_free{job="node-exporter",fstype=~"ext4|xfs"} / node_filesystem_files{job="node-exporter",fstype=~"ext4|xfs"}) * 100
record: node_exporter:filesystem:used:percent
labels:
desc: "节点的inode的剩余可用的百分比"
unit: "%"
job: "node-exporter"
#############################################################################################
# filefd #
- expr: node_filefd_allocated{job="node-exporter"}
record: node_exporter:filefd_allocated:count
labels:
desc: "节点的文件描述符打开个数"
unit: "%"
job: "node-exporter"
- expr: node_filefd_allocated{job="node-exporter"}/node_filefd_maximum{job="node-exporter"} * 100
record: node_exporter:filefd_allocated:percent
labels:
desc: "节点的文件描述符打开百分比"
unit: "%"
job: "node-exporter"
#############################################################################################
# network #
- expr: avg by (environment,instance,device) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:bit:rate
labels:
desc: "节点网卡eth0每秒接收的比特数"
unit: "bit/s"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:bit:rate
labels:
desc: "节点网卡eth0每秒发送的比特数"
unit: "bit/s"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_receive_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:packet:rate
labels:
desc: "节点网卡每秒接收的数据包个数"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:packet:rate
labels:
desc: "节点网卡发送的数据包个数"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netin:error:rate
labels:
desc: "节点设备驱动器检测到的接收错误包的数量"
unit: "个/秒"
job: "node-exporter"
- expr: avg by (environment,instance,device) (irate(node_network_transmit_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m]))
record: node_exporter:network:netout:error:rate
labels:
desc: "节点设备驱动器检测到的发送错误包的数量"
unit: "个/秒"
job: "node-exporter"
- expr: node_tcp_connection_states{job="node-exporter", state="established"}
record: node_exporter:network:tcp:established:count
labels:
desc: "节点当前established的个数"
unit: "个"
job: "node-exporter"
- expr: node_tcp_connection_states{job="node-exporter", state="time_wait"}
record: node_exporter:network:tcp:timewait:count
labels:
desc: "节点timewait的连接数"
unit: "个"
job: "node-exporter"
- expr: sum by (environment,instance) (node_tcp_connection_states{job="node-exporter"})
record: node_exporter:network:tcp:total:count
labels:
desc: "节点tcp连接总数"
unit: "个"
job: "node-exporter"
#############################################################################################
# process #
- expr: node_processes_state{state="Z"}
record: node_exporter:process:zoom:total:count
labels:
desc: "节点当前状态为zoom的个数"
unit: "个"
job: "node-exporter"
#############################################################################################
# other #
- expr: abs(node_timex_offset_seconds{job="node-exporter"})
record: node_exporter:time:offset
labels:
desc: "节点的时间偏差"
unit: "s"
job: "node-exporter"
#############################################################################################
- expr: count by (instance) ( count by (instance,cpu) (node_cpu_seconds_total{ mode='system'}) )
record: node_exporter:cpu:count
关于报警文件
#关于node-exporer-alert.rules
groups:
- name: node-exporter-alert
rules:
- alert: node-exporter-down
expr: node_exporter:up == 0
for: 1m
labels:
severity: 'critical'
annotations:
summary: "instance: {{ $labels.instance }} 宕机了"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} 关机了, 时间已经1分钟了。"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-cpu-high
expr: node_exporter:cpu:total:percent > 80
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu 使用率高于 {{ $value }}"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} CPU使用率已经持续三分钟高过80% 。"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-cpu-iowait-high
expr: node_exporter:cpu:iowait:percent >= 12
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率高于 {{ $value }}"
description: "instance: {{ $labels.instance }} \n- job: {{ $labels.job }} cpu iowait使用率已经持续三分钟高过12%"
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-load-load1-high
expr: (node_exporter:load:load1) > (node_exporter:cpu:count) * 1.2
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} load1 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-memory-high
expr: node_exporter:memory:used:percent > 85
for: 3m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-high
expr: node_exporter:disk:used:percent > 88
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} disk 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-read:count-high
expr: node_exporter:disk:read:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops read 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-write-count-high
expr: node_exporter:disk:write:count:rate > 3000
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} iops write 使用率高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-disk-read-mb-high
expr: node_exporter:disk:read:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 读取字节数 高于 {{ $value }}"
description: ""
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
- alert: node-exporter-disk-write-mb-high
expr: node_exporter:disk:write:mb:rate > 60
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 写入字节数 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-filefd-allocated-percent-high
expr: node_exporter:filefd_allocated:percent > 80
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 打开文件描述符 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netin-error-rate-high
expr: node_exporter:network:netin:error:rate > 4
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入的错误速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netin-packet-rate-high
expr: node_exporter:network:netin:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包进入速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-netout-packet-rate-high
expr: node_exporter:network:netout:packet:rate > 35000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 包流出速率 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-network-tcp-total-count-high
expr: node_exporter:network:tcp:total:count > 40000
for: 1m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} tcp连接数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-process-zoom-total-count-high
expr: node_exporter:process:zoom:total:count > 10
for: 10m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} 僵死进程数量 高于 {{ $value }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
- alert: node-exporter-time-offset-high
expr: node_exporter:time:offset > 0.03
for: 2m
labels:
severity: info
annotations:
summary: "instance: {{ $labels.instance }} {{ $labels.desc }} {{ $value }} {{ $labels.unit }}"
description: ""
value: "{{ $value }}"
instance: "{{ $labels.instance }}"
配置企业微信报警
新建一个存放wechat.tmpl的目录
mkdir /alertmanager/template/
cd /alertmanager/template/
vim wechat.tmpl
## 带恢复告警的模版 注:alertmanager.yml wechat_configs中加上配置send_resolved: true
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
===alertmanager监控报警===
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
告警应用:{{ $alert.Annotations.summary }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
触发阀值:{{ $alert.Annotations.value }}
告警详情: {{ $alert.Annotations.description }}
触发时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
===========end============
{{ end }}
{{ end }}
修改alertmanager里面的收件人
global:
resolve_timeout: 5m
wechat_api_corp_id: 'ww2b0ab679438a91fc'
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'Zl6pH_f-u2R1bwqDVPfLFygTR-JaYpH08vcTBr8xb0A'
templates:
- '/etc/alertmanager/template/wechat.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_party: '2'
to_user: 'LiZhiSheng'
agent_id: 1000005
corp_id: 'ww2b0ab679438a91fc'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
api_secret: 'Zl6pH_f-u2R1bwqDVPfLFygTR-JaYpH08vcTBr8xb0A'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
prometheus配置不要变,我们还使用以前的rules规则
重启alertmanager
docker run -d --name alertmanager -p 9093:9093 -v /alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /alertmanager/template/:/etc/alertmanager/template prom/alertmanager
参数说明:
- corp_id: 企业微信账号唯一 ID, 可以在
我的企业中查看。 - to_party: 需要发送的组。
- to_user: 需要发送的用户
- agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
- api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
验证:
停掉一台docker容器

恢复消息如下


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)