
Pytorch版YOLOv4训练步骤(一)
想使用YOLOv4,参考argusswift博主的文章逐步实现了一下。从VOC、COCO到最后自己的数据集,记录一下过程。使用的代码GitHub:https://github.com/argusswift/YOLOv4-pytorch使用环境Nvida GeForce RTX 2080TItorch1.4.0+cu100torchvision0.5.0+cu100Python3.6Centos安装
想使用YOLOv4,参考argusswift博主的文章逐步实现了一下。从VOC到自己的数据集,记录一下过程。
这是第一篇,记录了从代码下载、环境配置到使用VOC数据集训练和测试的过程。下一篇将尝试使用自建数据集。
目录
使用的代码
GitHub:https://github.com/argusswift/YOLOv4-pytorch
使用环境
- Nvida GeForce RTX 2080TI
- torch1.4.0+cu100
- torchvision0.5.0+cu100
- Python3.6
- Centos
配置运行环境
-
刚刚下载完的程序,如果用pycharm打开,会提示没有配置解释器(我就理解为运行环境或者是虚拟环境,理解不准确,勿喷),点击下面图中1或2可以配置,再点击Interpreter Settings就进入了配置界面
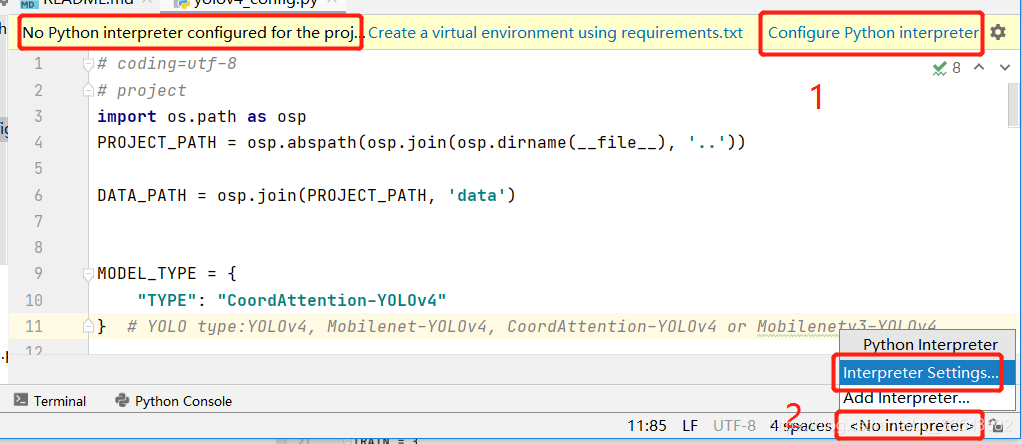
- 在弹出框中选择Show All

- 在弹出的已有的解释器中选择自己需要的,也可以点击加号添加。选择好之后点击OK,Pycharm会自动加载这个环境下已安装的包,点击Apply,OK,就可以使用这个环境了。

去掉VCS
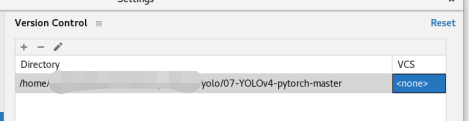
使用PyCharm打开工程后,右下角会弹出Invalid VCS root mapping

可以点击Configure在弹出框中将VCS选为<none>,就不会再提示了,这个应该是原工程用来Git同步的,去掉不影响使用

安装依赖
- pip install -r requirements.txt --user
- 在我测试时提示没有apex包,因此这个应该也是需要的,但是在requirements里面没有列出,安装方法如下
git clone https://github.com/NVIDIA/apex cd apex python setup.py install但是我直接clone不下来,所以直接通过github或者codechina下载下来压缩包,然后解压,不进入apex目录,直接用python setup.py install,即可安装
下载数据集
- Pascal VOC数据集:VOC 2012_trainval 、VOC 2007_trainval、VOC2007_test
- COCO2017数据集 :train2017_img、train2017_ann、val2017_img、val2017_ann、test2017_img、test2017_list
下载权重
原博主训练好的VOC结果
百度云盘,提取码 args
VOC训练过程
-
放置数据集
VOC数据集下载后为三个压缩包,
VOCtrainval_11-May-2012.tar
VOCtrainval_06-Nov-2007.tar
VOCtest_06-Nov-2007.tar
将三个压缩包解压后放到代码目录的data文件夹下
# 解压
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar放置后的代码目录如下:
YOLOv4-pytorch-master
|—— .github
|—— config
| |—— __init__.py
| |—— yolov4_config.py
|—— data
| |—— CBAM.png
| |—— det-result.jpg
| |—— heatmap.jpg
| |—— modelsize.jpg
| |—— results.jpg
| |—— SEnet.jpg
|—— eval
| |—— cocoapi_evaluator.py
| |—— evaluator.py
| |—— voc_eval.py
|—— model
| |—— backbones
| |—— head
| |—— layers
| |—— loss
| |—— __init__.py
| |—— build_model.py
| |—— YOLOv4.py
|—— utils
| |—— __init__.py
| |—— ...
|—— eval_coco.py
|—— eval_voc.py
|—— INSTALL.md
|—— install.sh
|—— onnx_transform.py
|—— README.md
|—— requirements.txt
|—— train.py
|—— video_test.py需要把VOC下载后的三个压缩包解压到data目录下,解压后data目录如下。即新增了三个文件夹VOCtest-2007、VOCtrainval-2007、VOCtrainval-2012。
|——data
| |——VOCtest-2007
| |——VOCdevkit
| |——VOC2007
| |——Annotations
| |——ImageSets
| |——JPEGImages
| |——SegmentationClass
| |——SegmentationObjct
| |——VOCtrainval-2007
| |——VOCdevkit
| |——VOC2007
| |——Annotations
| |——ImageSets
| |——JPEGImages
| |——SegmentationClass
| |——SegmentationObjct
| |——VOCtrainval-2012
| |——VOCdevkit
| |——VOC2012
| |——Annotations
| |——ImageSets
| |——JPEGImages
| |——SegmentationClass
| |——SegmentationObjct
| |—— CBAM.png
| |—— det-result.jpg
| |—— heatmap.jpg
| |—— modelsize.jpg
| |—— results.jpg
| |—— SEnet.jpg-
处理数据集
使用utils/voc.py(在pycharm中找到voc.py这个文件,右键选择Run ‘voc’)转换pascal voc *.xml格式到.txt格式(img_path xmin0 ymin0 xmax0 ymax0 class0, xmin1 ymin1 xmax1 ymax1 class1,……)
运行后data目录下多了两个文件test_annotation.txt和train_annotation.txt。
-
放置预训练模型
在项目目录下新建weight目录,将下载好的三个权重文件和原博主训练好的voc结果,放到weight目录下,放置后目录如下
YOLOv4-pytorch-master
|——weight
| |——mobilenetv2.pth
| |——mobilenetv3.pth
| |——voc_best.pt
| |——yolov4.weights-
确认运行的数据集和模型
查看config/yolov4_config.py中“DATA_TYPE”参数是什么,项目原先写的就是VOC,如果过没动过就不用改了。因为我要先用VOC数据集运行一下看能否跑通。
模型原先设置的是CoordAttention-YOLOv4,因为我下载了yolov4的权重,不确定这个权重是否适用于CoordAttention-YOLOv4所以把模型改成了YOLOv4,即MODEL_TYPE={"TYPE": "YOLOv4"}。修改之后和下面的图一样。

-
修改eval/evaluator.py
修改evaluator.py第226行

修改内容
self.val_data_path, "Annotations\\" + "{:s}.xml"
修改为
self.val_data_path, "Annotations" + os.sep + "{:s}.xml"原先Annotations后面为\\,这样在最后测试的时候会报找不到文件的错误
FileNotFoundError: [Errno 2] No such file or directory: '/home/yy/data/dataset/VOC/07-YOLOv4-pytorch-master/data/VOCtest-2007/VOCdevkit/VOC2007/Annotations\\000001.xml'这个比较坑,程序跑了1天半,跑了30个epoch,还没保存结果的时候报这个错误,导致全部白跑,而文件没放错,就是因为不同的系统对于默认分隔符的不同,所以一定要注意把这个"\\"改成os.sep,这个是根据使用的系统不同添加不同的分隔符,加了之后就不再报错了。
-
修改结果保存频次
原先的保存频次是YOLOv4训练30个epoch开始保存,其他的模型训练50次才保存。这对于我这种只是想先运行一下看能不能跑通的初学者来说不大友好,毕竟卡配置不高,VOC数据集跑一个epoch都差不多1.5个小时,等30个epoch后万一出点啥问题等于白跑,所以把30改成了1。本以为1个epoch之后就开始保存了,结果因为前面有epoch=0,等于运行到epoch=1开始保存,而且是从epoch=1开始,每个epoch都保存一次,会比较优劣,结果比上一次好的时候会把前面的结果覆盖。

-
训练
为了避免每次在终端中数据运行参数,在PyCharm中右上角点击train右侧的下三角,选择Edit Configurations

在弹出框中的Parameters输入运行参数
--gpu_id 0 --weight_path weight/yolov4.weights输入后点击OK

这样可以直接点击绿色三角运行训练了

运行6个epoch,显存溢出,但已经有保存的结果了,如何resume运行程序呢,就是修改运行输入参数,增加--resume
--gpu_id 0 --weight_path weight/yolov4.weights --resume不过我只是为了用VOC跑通,然后改为训练自己的程序,所以6个epoch已经有结果了,也可以不用训练了,为了验证之前是不是第6个epoch运行完成没问题,所以,我把yolov4_config.py中的"YOLO_EPOCHS": 50改为"YOLO_EPOCHS": 6,然后按上面添加--resume的方式运行一下程序,发现可以正常运行完,说明之前运行的结果已经处理完成。


-
测试
训练完成,下面看看能否测试。根据博主的说明,对于VOC数据集运行下面这个 ,$DATA_TEST是啥,目测会报错。
python eval_voc.py --weight_path weight/best.pt --gpu_id 0 --visiual $DATA_TEST --eval --mode det我按这个设置了eval_voc的运行输入参数,果然报错了,但还不是$DATA_TEST的错

找不到model,为什么呢。。。由于担心之前运行到epoch=6时显存溢出导致程序存的best.pt有问题,所以我把yolov4_config.py中的YOLO_EPOCHS": 6改为"YOLO_EPOCHS": 7,让程序再跑一个epoch,再用resume模式继续运行了一个epoch,看能否正常结束。


重新运行后,看上去是正常结束的,所以运行train.py是完整的,再按照之前的方式运行eval_voc.py,还是一样的报错,说明不是train的问题。看报错像是说chkpt没有"model"的键值,但是train.py中明明有存呀?根据debug报错,定位到是在__load_model_weights里面self.__model.load_state_dict(chkpt["model"])这一句出的问题,而chkpt是一个OrderedDict类,所以打印一下chkpt的所有键值,加了print(chkpt.keys()),发现真的没有"model"的键值,为啥呢?

于是仔细研究了train.py保存模型的代码,发现在保存last.py时,存的是chkpt,所以在last.py中有chkpt["model"],而在保存best.py时,存的是chkpt["model"],所以调用best.py时,里面是没有chkpt["model"]的。。。。omg。

所以要把eval_voc.py中的self.__model.load_state_dict(chkpt["model"])改为 self.__model.load_state_dict(chkpt),修改之后如下

再运行debug,可以正常load权重了,然后$DATA_TEST报错了,果不其然。。。

程序不认识$DATA_TEST,那么这个$DATA_TEST是啥呢,从字面看感觉可能是测试集的文件,所以我手动改成了下面这样,就是把$DATA_TEST改成了data/test_annotation.txt,也就是测试集的文件目录和标记结果。
--weight_path weight/best.pt --gpu_id 0 --visiual data/test_annotation.txt --mode det结果依然报错

这回说他不是个目录,那就换成测试集的目录试试。
--weight_path weight/best.pt --gpu_id 0 --visiual data/VOCtest-2007 --mode det还是报错
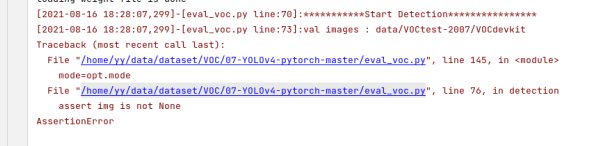
再次仔细看了eval_voc.py的主函数,发现--visiual有默认值呀,那可以去掉这项

结果依然报错。。。在仔细看发现default的目录和真实的目录不一样。少了VOCdevkit那一层,所以改运行输入为
--weight_path weight/best.pt --gpu_id 0 --visiual data/VOCtest-2007/VOCdevkit/VOC2007/JPEGImages --mode det再运行,终于成功

运行完成后,看日志感觉结果是存在了detection_result的目录下,但是实际看结果并没有生成对应的目录。。。。等于白跑。。。。手工新建了detection_result的目录,重新启动eval_voc.py,可以出结果了,因为只训练了7个epoch,有一些检测出来了,还有很多没有检测结果,反正只是用来测一下能不能跑通所以也无所谓了。




旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)