
机器学习数据集划分方法
数据集划分方法划分基本准则:保持训练集和验证集之间的互斥性准则解释:测试样本尽量不在训练样本中出现,以保证验证集上的表现能代表模型的泛化能力留出法直接将数据集划分成两个互斥的集合,其中一个做训练集,一个做验证集常用划分比例: 7:3 、7.5:2.5 、8:2交叉验证法(cv)将数据集划分为k个大小相似的互斥子集,每一次以 k-1 个子集做训练,1个子集做验证,训练k次,最终返回的是k次训练结果的
·
数据集划分方法
划分基本准则:保持训练集和验证集之间的互斥性
准则解释:测试样本尽量不在训练样本中出现,以保证验证集上的表现能代表模型的泛化能力
留出法
直接将数据集划分成两个互斥的集合,其中一个做训练集,一个做验证集
常用划分比例: 7:3 、7.5:2.5 、8:2
交叉验证法(cv)
将数据集划分为k个大小相似的互斥子集,每一次以 k-1 个子集做训练,1个子集做验证,训练k次,最终返回的是k次训练结果的均值,因此交叉验证法又称为k折交叉法(k-fold)
数据集划分案例
用到房价预测数据:https://download.csdn.net/download/d1240673769/20910882
数据加载
# 基本数据读取
import pandas as pd
import matplotlib.pyplot as plt
# 样本数据读取
df = pd.read_excel('realestate_sample_preprocessed.xlsx')
# 根据共线性矩阵,保留与房价相关性最高的日间人口,将夜间人口和20-39岁夜间人口进行比例处理
def age_percent(row):
if row['nightpop'] == 0:
return 0
else:
return row['night20-39']/row['nightpop']
df['per_a20_39'] = df.apply(age_percent,axis=1)
df = df.drop(columns=['nightpop','night20-39'])
# 数据集基本情况查看
print(df.shape)
print(df.dtypes)
print(df.isnull().sum())

构建模型
构建模型
import numpy as np
from sklearn.linear_model import LinearRegression, LassoCV
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler, PowerTransformer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# 构建模型工作流
pipe_lm = Pipeline([
('sc',StandardScaler()),
('power_trans',PowerTransformer()),
('polynom_trans',PolynomialFeatures(degree=3)),
('lasso_regr', LassoCV(alphas=(
list(np.arange(8, 10) * 10)
),
cv=KFold(n_splits=3, shuffle=True),
n_jobs=-1))
])
print(pipe_lm)

留出法进行数据集划分
# 载入sklearn中数据集划分的方法
from sklearn.model_selection import train_test_split
# 将数据集划分成训练集和验证集:划分比例0.75训练,0.25验证
training, testing = train_test_split(df, test_size=0.25, random_state=1)
# 提取训练集中的x与y
x_train=training.copy()[['complete_year', 'area', 'daypop', 'sub_kde', 'bus_kde', 'kind_kde', 'per_a20_39']]
y_train=training.copy()['average_price']
# 提取验证集中的x与y
x_test=testing.copy()[['complete_year', 'area', 'daypop', 'sub_kde', 'bus_kde', 'kind_kde', 'per_a20_39']]
y_test=testing.copy()['average_price']
print('the shape of training set is: {}'.format(training.shape))
print('the shape of testing set is: {}'.format(testing.shape))
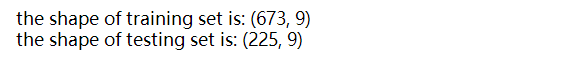
# 查看留出法验证集上模型的表现
import warnings
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
warnings.filterwarnings('ignore')
pipe_lm.fit(x_train,y_train)
y_predict = pipe_lm.predict(x_test)
print(f'mean squared error is: {mean_squared_error(y_test,y_predict)}')
print(f'mean absolute error is: {mean_absolute_error(y_test,y_predict)}')
print(f'R Squared is: {r2_score(y_test,y_predict)}')

交叉验证法进行数据集划分
## 交叉验证法进行数据集划分
from sklearn.model_selection import KFold
x = df[['complete_year', 'area', 'daypop', 'sub_kde', 'bus_kde', 'kind_kde', 'per_a20_39']]
y = df['average_price']
k = 10
kf = KFold(n_splits=k, shuffle=True)
查看交叉验证法模型表现
# 查看交叉验证法模型表现
mse = []
mae = []
r_s2=[]
for train_index, test_index in kf.split(df): # 拆分
x_traincv, x_testcv = x.loc[train_index], x.loc[test_index]
y_traincv, y_testcv = y.loc[train_index], y.loc[test_index]
pipe_lm.fit(x_traincv, y_traincv) # 训练
y_predictcv = pipe_lm.predict(x_testcv) # 预测
k_mse = mean_squared_error(y_testcv, y_predictcv)
mse.append(k_mse)
print('mean squared error is :{}'.format(k_mse))
k_mae = mean_absolute_error(y_testcv, y_predictcv)
mae.append(k_mae)
print('mean absoulte error is :{}'.format(k_mae))
k_r_s2 = r2_score(y_testcv, y_predictcv)
r_s2.append(k_r_s2)
print('R Squared error is :{}'.format(k_r_s2))
print('--------------------')

# 计算平均值
import numpy as np
print('mean squared error is {}'.format(np.array(mse).mean()))
print('mean absolute error is {}'.format(np.array(mae).mean()))
print('R Squared is {}'.format(np.array(r_s2).mean()))
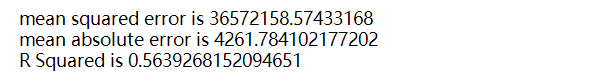
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)