grep,awk,sed使用小结
使用grep在文件中搜索文本(1)在stdin中搜索匹配特定模式的文本行:[root@m01 ~]# echo -e "jfjfjfjfjaaa" | grep aajfjfjfjfjaaa[root@m01 ~]#(2)在文件中搜索匹配特定模式的文本行:```python[root@m01 ~]# grep ftype filestat.shftype=`file -b "$line" | cu
使用grep在文件中搜索文本
(1)在stdin中搜索匹配特定模式的文本行:
[root@m01 ~]# echo -e "jfjfjfjfjaaa" | grep aa
jfjfjfjfjaaa
[root@m01 ~]#
(2)在文件中搜索匹配特定模式的文本行:
```python
[root@m01 ~]# grep ftype filestat.sh
ftype=`file -b "$line" | cut -d, -f1`
let statarray["$ftype"]++;
for ftype in "${!statarray[@]}";
echo $ftype : ${statarray["$ftype"]}
或者

(3)在多个文件中搜索匹配特定模式的文本行:
[root@m01 ~]# grep "do" IFS_test.sh filestat.sh
IFS_test.sh:do
IFS_test.sh:done;
filestat.sh:do
filestat.sh:done <<< "`find $path -type f -print`"
filestat.sh:do
filestat.sh:done
[root@m01 ~]#
(4)选项–color可以在输出行中着重标记出匹配到的模式。尽管该选项在命令行中的放置位置没有强制要求,不过惯常作为第一个选项出现:

(5)grep命令默认使用基础正则表达式。这是先前描述的正则表达式的一个子集。选项-E可以使grep使用扩展正则表达式。也可以使用默认启用扩展正则表达式的egrep命令:

或者

(6)选项-o可以只输出匹配到的文本:
[root@m01 ~]# echo this is a line. | egrep -o "[a-z]+\."
line.
[root@m01 ~]#
(7)选项-v可以打印出不匹配match_pattern的所有行:

选项-v能够反转(invert)匹配结果。
(8)选项-c能够统计出匹配模式的文本行数:需要注意的是-c只是统计匹配行的数量,并不是匹配的次数。例如:
[root@m01 ~]# echo -e "dfdfsdafsd222fdfsdf9999\n44444fgsdgsdg" | egrep -c "[0-9]"
2
[root@m01 ~]#
egrep命令只输出2,这是因为只有两个匹配行。在单行中出现的多次匹配只被计为一次。
(9)要统计文件中匹配项的数量,可以使用下面的技巧:
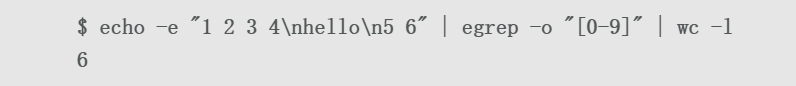
(10)选项-n可以打印出匹配字符串所在行的行号:
[root@m01 ~]# grep cpu_code -n disk.py
5:cpu_code_runtime = psutil.cpu_times(percpu=True)
6:cpu_code = psutil.cpu_count()
7:cpu_code_logical = psutil.cpu_count(logical=False)
9:cpu_code_percent = psutil.cpu_percent(percpu=True)
16:print("每个cpu占用时间:{}".format(cpu_code_runtime))
17:print("cpu逻辑数量:{}".format(cpu_code))
18:print("cpu物理数量:{}".format(cpu_code_logical))
20:print("每个cpu占比:{}".format(cpu_code_percent))
[root@m01 ~]#
如果涉及多个文件,该选项也会随输出结果打印出文件名。
(11)选项-b可以打印出匹配出现在行中的偏移。配合选项-o可以打印出匹配所在的字符或字节偏移:
[root@m01 ~]# echo aaa bbb ccc ddd | egrep -b -o "b"
4:b
5:b
6:b
[root@m01 ~]#
字符在行中的偏移是从0开始计数,不是1。
(12)选项-l可以列出匹配模式所在的文件
grep用法补充内容
1.递归搜索多个文件
[root@m01 ~]# grep "text" . -R -n
匹配到二进制文件 ./centos7_with_nettools.tar.gz
[root@m01 ~]#
命令中的 . 表示指定当前目录也可以指定其他目录,参数可以在目录之前或者之后。例如:
[root@m01 ~]# grep "text" /home/oldboy/tools/ -R -n
/home/oldboy/tools/nginx-1.19.2/conf/mime.types:3: text/html html htm shtml;
/home/oldboy/tools/nginx-1.19.2/conf/mime.types:4: text/css css;
2.忽略模式中的大小写
选项-i可以在匹配模式时不考虑字符的大小写
3.使用grep匹配多个模式
选项-e可以指定多个匹配模式:

上述命令会打印出匹配任意一种模式的行,每个匹配对应一行输出。例如:
[root@m01 ~]# echo aaa bbb ccc ddd eee ffff | grep -o -e "aaa" -e "eee"
aaa
eee
[root@m01 ~]#
可以将多个模式定义在文件中。选项-f可以读取文件并使用其中的模式(一个模式一行):

例如:
[root@m01 ~]# echo aaa bbb ccc ddd eee ffff | grep -o -f test.txt
aaa
eee
[root@m01 ~]#
4.在grep搜索中指定或排除文件
grep可以在搜索过程中使用通配符指定(include)或排除(exclude)某些文件。使用–include选项在目录中递归搜索所有的 .c和 .cpp文件:
[root@m01 ~]# grep "/bin/bash" . -r --include=*.{sh,py}
./filestat.sh:#!/bin/bash
./pwd.sh:#!/bin/bash
./IFS_test.sh:#!/bin/bash
./IFS_test.sh:line="root:x:0:0:root:/root:/bin/bash"
./并行.sh:#/bin/bash
./remove_duplicates.sh:#!/bin/bash
注意,some{string1,string2,string3}会被扩展成somestring1 somestring2somestring3。
使用选项–exclude在搜索过程中排除所有的README文件:
[root@m01 ~]# grep "/bin/bash" . -r --exclude=*.{sh,py}
匹配到二进制文件 ./centos7_with_nettools.tar.gz
./output.session:#!/bin/bash
选项–exclude-dir可以排除目录吗,如果需要从文件中读取排除文件列表,使用–exclude-from FILE。
5.使用0值字节后缀的xargs与grep
xargs命令可以为其他命令提供命令行参数列表。当文件名作为命令行参数时,建议用0值字节作为文件名终结符,而非空格。因为一些文件名中会包含空格字符,一旦它被误解为终结符,那么单个文件名就会被视为两个(例如,New file.txt被解析成New和file.txt两个文件名)。这个问题可以利用0值字节后缀来避免。我们使用xargs从命令(如grep和find)中接收stdin文本。这些命令可以生成带有0值字节后缀的输出。为了指明输入中的文件名是以0值字节作为终结,需要在xargs中使用选项-0。
[root@backup ~]# echo "111"> file1.txt
[root@backup ~]# echo "222"> file2.txt
[root@backup ~]# echo "333"> file3.txt
选项-l告诉grep只输出有匹配出现的文件名。选项-Z使得grep使用0值字节(\0)作为文件名的终结符。这两个选项通常都是配合使用的。xargs的-0选项会使用0值字节作为输入的分隔符:
[root@backup ~]# grep "111" file* -lZ | xargs -0 rm
[root@backup ~]# ll
总用量 24
-rw-------. 1 root root 1257 9月 11 2020 anaconda-ks.cfg
-rw-r--r--. 1 root root 853 3月 26 16:06 disk.py
-rw-r--r-- 1 root root 4 6月 4 18:01 file2.txt
-rw-r--r-- 1 root root 4 6月 4 18:02 file3.txt
-rw-r--r-- 1 root root 3 5月 19 10:46 test1.txt
-rw-r--r-- 1 root root 6 5月 19 10:44 test1.txt.2282.2021-05-19@10:46:35~
[root@backup ~]#
6.grep的静默输出
如果不打算查看匹配的字符串,而只是想知道是否能够成功匹配。这可以通过设置grep的静默选项(-q)来实现。在静默模式中,grep命令不会输出任何内容。它仅是运行命令,然后根据命令执行成功与否返回退出状态。0表示匹配成功,非0表示匹配失败。
下面是一个实现功能的脚本:
#!/bin/bash
#Filename: silent_grep.sh
#Desc: Testing whether a file contain a text or not
if [ $# -ne 2 ]; then
echo "Usage: $0 match_text filename"
exit 1
fi
match_text=$1
filename=$2
grep -q "$match_text" $filename
if [ $? -eq 0 ]; then
echo "The text exists in the file"
else
echo "Text does not exist in the file"
fi
脚本测试结果如下:
[root@backup ~]# ./silent_grep.sh 2222 2222.txt
The text exists in the file
[root@backup ~]#
也可以使用命令行的方式:
[root@backup ~]# grep -q 2222 2222.txt
[root@backup ~]# echo $?
0
[root@backup ~]#
7.打印出匹配文本之前或之后的行
基于上下文的打印是grep的一个挺不错的特性。当grep找到了匹配模式的行时,它只会打印出这一行。但我们也许需要匹配行之前或之后的n行。这可以通过控制选项-B和-A来实现。
选项-A可以打印匹配结果之后的行
选项-B可以打印匹配结果之前的行
选项-A和-B可以结合使用,或者也可以使用选项-C,它可以分别打印出匹配结果之前及之后的n行
如果有多个匹配,那么使用--作为各部分之间的分隔
使用sed替换文本
sed是stream editor(流编辑器)的缩写。它最常见的用法是进行文本替换。这则攻略中包括了大量sed命令的常见用法。


sed指令执行前需要先根据条件定位需要处理的数据行,如果没有指定定位条件,则默认sed会对所有数据行执行特定的指令。sed支持的数据定位方法如表6-3所示。

例如:
sed可以使用另一个字符串来替换匹配模式。模式可以是简单的字符串或正则表达式:

sed也可以从stdin中读取输入:

sed默认只打印出被替换的文本,可以将其用于管道中。
(1)选项-i会使得sed用修改后的数据替换原始文件:

(2)之前的例子只替换了每行中模式首次匹配的内容。g标记可以使sed执行全局替换:
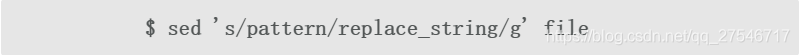
/#g标记可以使sed替换第N次出现的匹配:
fff@fff-PC:~/Desktop$ sed 's/a/h/g' test.txt
lhlhlhlhlh
fff@fff-PC:~/Desktop$ sed 's/a/h/2g' test.txt
lalhlhlhlh
fff@fff-PC:~/Desktop$ sed 's/a/h/3g' test.txt
lalalhlhlh
fff@fff-PC:~/Desktop$ sed 's/a/h/4g' test.txt
lalalalhlh
fff@fff-PC:~/Desktop$
sed命令会将s之后的字符视为命令分隔符。这允许我们更改默认的分隔符/:
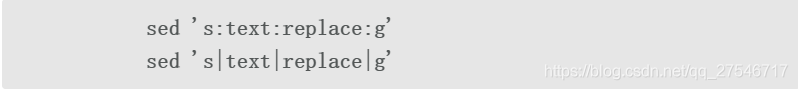
如果作为分隔符的字符出现在模式中,必须使用\对其进行转义:

sed命令可以使用正则表达式作为模式,另外还包含了大量可用于文本处理的选项。
1.移除空行
空行可以用正则表达式 ^$ 进行匹配。最后的/d告诉sed不执行替换操作,而是直接删除匹配到的空行:

2.直接在文件中替换
如果将文件名传递给sed,它会将文件内容输出到stdout。要是我们想就地(inplace)修改文件内容,可以使用选项-i:

例如,使用指定的数字替换文件中所有3位数的数字:

上面的单行命令只替换了所有的3位数字。正则表达式\b[0-9]{3}\b用于匹配3位数字。[0-9]表示数字取值范围是从0到9。{3}表示匹配之前的数字3次。{3}中的\用于转义{和}。\b表示单词边界。
更好的测试方法:有一种值得推荐的做法是先使用不带-i选项的sed命令,以确保正则表达式没有问题,如果结果符合要求,再加入-i选项将更改写入文件。另外,你也可以使用下列形式的sed:

这时的sed不仅替换文件内容,还会创建一个名为file.bak的文件,其中包含着原始文件内容的副本。
3.已匹配字符串标记(&)
在sed中,我们可以用&指代模式所匹配到的字符串,这样就能够在替换字符串时使用已匹配的内容:
fff@fff-PC:~/Desktop$ echo "aaa bbb ccc ddd" | sed 's/\w\+/[&]/g'
[aaa] [bbb] [ccc] [ddd]
fff@fff-PC:~/Desktop$
在这个例子中,正则表达式\w+匹配每一个单词,然后我们用[&]替换它。&对应于之前所匹配到的单词。
4.子串匹配标记(\1)

这条命令将digit 7替换为7。(pattern)用于匹配子串,在本例中匹配到的子串是7。子模式被放入使用反斜线转义过的()中。对于匹配到的第一个子串,其对应的标记是\1,匹配到的第二个子串是\2,往后以此类推。

([a-z]+)匹配第一个单词,([A-Z]+)匹配第二个单词。\1和\2分别用来引用这两个单词。这种引用形式叫作向后引用(back reference)。在替换部分,它们的次序被更改为\2 \1,因此就呈现出了逆序的结果。
5.组合多个表达式
可以利用管道组合多个sed命令,多个模式之间可以用分号分隔,或是使用选项-ePATTERN:

它等同于

或者

(个人认为,管道符的样式,可读性要好一点)
例子:

6.引用
sed表达式通常用单引号来引用。不过也可以使用双引号。shell会在调用sed前先扩展双引号中的内容。如果想在sed表达式中使用变量,双引号就能派上用场了。
fff@fff-PC:~/Desktop$ test=test
fff@fff-PC:~/Desktop$ echo test txt | sed "s/$test/hello/g"
hello txt
fff@fff-PC:~/Desktop$
$test的求值结果是hello。
使用awk进行高级文本处理
awk命令可以处理数据流。它支持关联数组、递归函数、条件语句等功能。

awk脚本的结构如下:


awk支持使用正则进行模糊匹配,也支持字符串和数字的精确匹配,并且支持逻辑与和逻辑或。awk比较符号如表7-2所示。

awk命令也可以从stdin中读取输入。awk脚本通常由3部分组成:BEGIN、END和带模式匹配选项的公共语句块(common statement block)。这3个部分都是可选的,可以不用出现在脚本中。awk以逐行的形式处理文件。BEGIN之后的命令会先于公共语句块执行。对于匹配PATTERN的行,awk会对其执行PATTERN之后的命令。最后,在处理完整个文件之后,awk会执行END之后的命令。
使用案例:
简单的awk脚本可以放在单引号或双引号中:

或者

下面的命令会输出文件行数:

工作原理
awk命令的工作方式如下。
(1)首先执行BEGIN { commands } 语句块中的语句。
(2)接着从文件或stdin中读取一行,如果能够匹配pattern,则执行随后的commands语句块。重复这个过程,直到文件全部被读取完毕。
(3)当读至输入流末尾时,执行END { commands } 语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行。这是一个可选的语句块,诸如变量初始化、打印输出表格的表头等语句通常都可以放在BEGIN语句块中。
END语句块和BEGIN语句块类似。它在awk读取完输入流中所有的行之后被执行。像打印所有行的分析结果这种常见任务都是在END语句块中实现的。
最重要的部分就是和pattern关联的语句块。这个语句块同样是可选的。如果不提供,则默认执行{ print },即打印所读取到的每一行。awk对于读取到的每一行都会执行该语句块。这就像一个用来读取行的while循环,在循环体中提供了相应的语句。
每读取一行,awk就会检查该行是否匹配指定的模式。模式本身可以是正则表达式、条件语句以及行范围等。如果当前行匹配该模式,则执行{ }中的语句。
模式是可选的。如果没有提供模式,那么awk就认为所有的行都是匹配的:
root@fff-PC:~# echo -e "line1\nline2" | awk 'BEGIN{print "start"} {print } END{print "end"}'
start
line1
line2
end
当使用不带参数的print时,它会打印出当前行。
print能够接受参数。这些参数以逗号分隔,在打印参数时则以空格作为参数之间的分隔符。在awk的print语句中,双引号被当作拼接操作符(concatenationoperator)使用。例如:
root@fff-PC:~# echo | awk '{ var1="v1";var2="v2";var3="v3"; print var1,var2,var3; }'
v1 v2 v3
root@fff-PC:~#
echo命令向标准输出写入一行,因此awk的 { } 语句块中的语句只被执行一次。如果awk的输入中包含多行,那么 { } 语句块中的语句也就会被执行相应的次数。拼接的使用方法如下:
root@fff-PC:~# echo | awk '{ var1="v1";var2="v2";var3="v3"; print var1 "-" var2 "=" var3; }'
v1-v2=v3
root@fff-PC:~#
{ }就像一个循环体,对文件中的每一行进行迭代。(我们通常将变量初始化语句(如var=0;)放入BEGIN语句块中。在END{}语句块中,往往会放入用于打印结果的语句。)
补充内容
awk命令与诸如grep、find和tr这类命令不同,它功能众多,而且拥有很多能够更改命令行为的选项。awk命令是一个解释器,它能够解释并执行程序,和shell一样,它也包括了一些特殊变量。
1.特殊变量以下是awk可以使用的一些特殊变量。
❏ NR:表示记录编号,当awk将行作为记录时,该变量相当于当前行号。
❏ NF:表示字段数量,在处理当前记录时,相当于字段数量。默认的字段分隔符是空格。
❏ $0:该变量包含当前记录的文本内容。
❏ $1:该变量包含第一个字段的文本内容。
❏ $2:该变量包含第二个字段的文本内容

我们可以用print $NF打印一行中最后一个字段,用 $(NF-1)打印倒数第二个字段,其他字段以此类推。awk也支持printf()函数,其语法和C语言中的同名函数一样。
下面的命令会打印出每一行的第二和第三个字段:

我们可以使用NR统计文件的行数:

这里只用到了END语句块。每读入一行,awk都会更新NR。当到达文件末尾时,NR中的值就是最后一行的行号。你可以将每一行中第一个字段的值按照下面的方法累加:

2.将外部变量值传递给awk
借助选项-v,我们可以将外部值(并非来自stdin)传递给awk:
root@fff-PC:~# var=1000
root@fff-PC:~# echo $var
1000
root@fff-PC:~# echo | awk -v VARIABLE=var '{print VARIABLE}'
var
root@fff-PC:~# echo | awk -v VARIABLE=#var '{print VARIABLE}'
#var
root@fff-PC:~# echo | awk -v VARIABLE=$var '{print VARIABLE}'
1000
root@fff-PC:~#
还有另一种灵活的方法可以将多个外部变量传递给awk。例如:

当输入来自于文件而非标准输入时,使用下列命令:
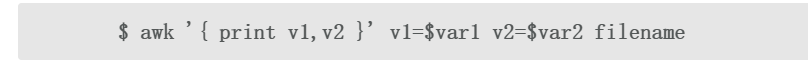
在上面的方法中,变量以键-值对的形式给出,使用空格分隔(v1= v a r 1 v 2 = var1v2= var1v2=var2),作为awk的命令行参数紧随在BEGIN、{}和END语句块之后。
3.用getline读取行
awk默认读取文件中的所有行。如果只想读取某一行,可以使用getline函数。它可以用于在BEGIN语句块中读取文件的头部信息,然后在主语句块中处理余下的实际数据。
该函数的语法为:getline var。
变量var中包含了特定行。如果调用时不带参数,我们可以用 $0、$1和$2访问文本行的内容。
例如:
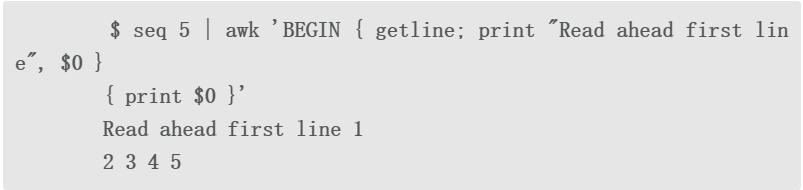
4.使用过滤模式对awk处理的行进行过滤
我们可以为需要处理的行指定一些条件:

5.设置字段分隔符

在BEGIN语句块中可以用OFS="delimiter"设置输出字段分隔符。
6.从awk中读取命令输出
awk可以调用命令并读取输出。把命令放入引号中,然后利用管道将命令输出传入getline:

下面的代码从/etc/passwd文件中读入一行,然后显示出用户登录名及其主目录。在BEGIN语句块中将字段分隔符设置为:,在主语句块中调用了grep。
root@fff-PC:~# echo | awk 'BEGIN {FS=":"} {"grep fff /etc/passwd" | getline; print $1,$6}'
fff /home/fff
7.awk的关联数组
除了数字和字符串类型的变量,awk还支持关联数组。关联数组是一种使用字符串作为索引的数组。你可以通过中括号中索引的形式来分辨出关联数组:

就像用户定义的简单变量一样,你也可以使用等号为数组元素赋值:

8.在awk中使用循环
在awk中可以使用for循环,其格式与C语言中的差不多:

另外awk还支持列表形式的for循环,也可以显示出数组的内容:

下面的例子展示了如何将收集到的数据存入数组并显示出来。这个脚本从/etc/password中读取文本行,以:作为分隔符将行分割成字段,然后创建一个关联数组,数组的索引是登录ID,对应的值是用户名:
root@fff-PC:~# awk 'BEGIN {FS=":"} {nam[$1]=$5} END {for (i in nam) {print i,nam[i]}}' /etc/passwd
dnsmasq dnsmasq,,,
man man
sync sync
irc ircd
mail mail
sys sys
fff
nm-openvpn NetworkManager OpenVPN,,,
tss TPM2 software stack,,,
news news
9.awk内建的字符串处理函数
awk有很多内建的字符串处理函数。
❏ length(string):返回字符串string的长度。
❏ index(string, search_string):返回search_string在字符串string中出现的位置。
❏ split(string, array, delimiter):以delimiter作为分隔符,分割字符串string,将生成的字符串存入数组array。
❏ substr(string, start-position, end-position) :返回字符串string中以start-position和end-position作为起止位置的子串。
❏ sub(regex, replacement_str, string):将正则表达式regex匹配到的第一处内容替换成replacment_str。
❏ gsub(regex, replacement_str, string):和sub()类似。不过该函数会替换正则表达式regex匹配到的所有内容。
❏ match(regex, string):检查正则表达式regex是否能够在字符串string中找到匹配。如果能够找到,返回非0值;否则,返回0。match()有两个相关的特殊变量,分别是RSTART和RLENGTH。变量RSTART包含了匹配内容的起始位置,而变量RLENGTH包含了匹配内容的长度。
10. awk条件判断
awk的单分支if判断语法格式如下,if判断后面如果只有一个动作指令,则花括号{}可以省略,如果if判断后面的指令为多条指令则需要使用花括号{}括起来,多个指令使用分号分隔。

awk的双分支if判断语法格式如下。
 awk的多分支if判断语法格式如下。
awk的多分支if判断语法格式如下。

if属于判断指令,而在awk中所有的动作指令都必须在写在{ }中。
单分支if语句的案例:

双分支if语句的案例

上面的命令逐行分析第三列用户UID的值是否小于1000,如果小于1000则执行x++,否则执行y++,当所有数据行都读取完毕后,通过END将最终变量x和变量y的值打印输出,即普通用户和系统用户的个数。

逐行匹配ls -l /etc/命令的输出结果,如果第1列以-开头则执行x++(文件个数计数器),否则执行y++(目录个数计数器),在所有数据行都统计完毕后,通过END将变量x和变量y的值打印输出,即/etc/目录下面普通文件的个数和子目录的个数(这里不包含隐藏文件或目录)。
多分支if语句的案例


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)