

Snowflake 简单介绍与使用
目录Snowflake 入门1. Snowflake 简介multi-cluster & shared-data三层架构数据存储层(Database Storage)虚拟仓库层(Virtual Warehouse)云服务层(Cloud Services)易用性持续可用性支持半结构化和非结构化数据安全性弹性2. Snowflake 使用方法注册使用加载数据演示3. 总结参考文献Snowfla
目录
Snowflake 入门
本文参考了 Snowflake 于 2016 年发表的论文 《The snowflake elastic data warehouse》[1] 以及官方文档 [2]。
1. Snowflake 简介
Snowflake 是一个多租户,事务型,安全,高度可扩展的弹性数据仓库系统,是一个原生于云端,专注于数据仓库的 SaaS 方案提供商,Snowflake 从 2012 年底开始计划实施,现在已经成为数据仓库解决方案提供商中的佼佼者,2020年正式上市,并一举成为纽交所最大的云计算服务公司 IPO,更是获得了巴菲特旗下的伯克希尔-哈撒韦公司超过5.5亿美元的投资。这也是巴菲特54年来首次“打新股”。
Snowflake 是为了解决传统数据仓库不能在云上弹性伸缩,数据的来源格式更加广泛等问题而出现的,它不是基于 Hadoop,PostgreSQL等工具的,它的处理引擎和大部分工具都是从头自研的。
multi-cluster & shared-data
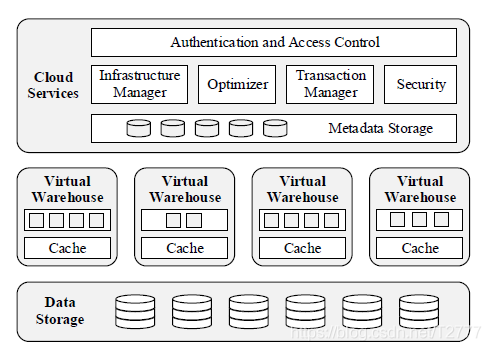
Snowflake 采用的是一种 multi-cluster (多集群),shared data 的架构,是传统 shared-disk 和 shared-nothing 数据库体系结构的混合体,实现了存储与计算的分离,克服了纯粹的 shared-nothing 架构的由于存储和计算紧密耦合导致在节点关系变化和升级时容易产生的问题。 Snowflake 是一个面向服务的体系架构,由高度容错和独立可扩展的三个服务层组成,不同服务层通过 RESTful接口通信,Snowflake的云原生性体现在它的三层架构都完全部署在云上,用户可以在 Amazon Web Services(AWS),Google Cloud Platform (GCP), Microsoft Azure (Azure) 中选择云平台和区域。
三层架构
数据存储层(Database Storage)
首先是数据存储层(Database Storage),Snowflake 中的数据是按照内部优化,加密,压缩的列式存储方式组织的,数据存放在云提供商的存储平台如 Amazon S3上,数据一致性问题自然也由云提供商服务解决,例如 S3 实现的强一致性。数据存储层采用的类似于 shared-disk 架构,可以在无关计算资源的情况下进行自动扩容,用户无需干预,表结构自动水平划分为固定大小不可变的微分区(micro partition),一个micro partition 就是一个表文件,当虚拟仓库中节点的本地磁盘空间耗尽时,数据存储层还用来存储由查询(比如大量 join 操作)生成的溢出的临时数据以及查询结果,使得系统可以计算任意大的查询并简化了查询处理。
三层架构演示图:
虚拟仓库层(Virtual Warehouse)
其次是虚拟仓库层(Virtual Warehouse)也称作查询处理层(Query Processing),虚拟仓库层由云提供商提供的 MPP (大规模并行处理) 集群计算实例如Amazon EC2实例集群组成,数据仓库中可以包含一个集群,组成集群的实例称为工作节点(worker node),用户可以根据需要选择虚拟仓库的大小,充分利用云的弹性优势,不同大小的虚拟仓库包含的节点数不同,当然计费也不同,下面是仓库的尺寸所对应的节点数和积分计费方式:

用户可以根据需要在任意时刻创建、销毁或者改变一个 VW 的大小,对数据库不会产生影响,是临时的、特定于用户的。用户可以创建多集群的 VW 以满足更高的计算需求。每个查询只在一个 VW 上运行,worker 节点不会在不同 VW 之间共享,具有良好的计算资源隔离性特点,每个 VW 可以运行多个并发查询,多个 VW 也可以并发执行并且访问相同的共享表,每一个 worker 节点在本地磁盘上缓存一部分查询得到的表数据,采用一致性哈希策略将查询的表数据分配给各个worker节点,访问同一表文件的后续查询或并发查询将在同一 worker 上执行,采用 LRU (最近最少访问)最终替换缓存策略,通过 file stealing (文件窃取)以及允许其它 worker 节点直接从数据存储层下载当前节点负责范围内的表文件,解决负载 skew (倾斜)的问题。虚拟仓库层的这些特点保障了虚拟仓库层的类似 shared-nothing 性质,VW 层进行查询处理时是基于列的(更有效地利用了 CPU 缓存和 SIMD 指令,可压缩),向量化的(小批量流水线),基于 push 的,没有缓冲池。
云服务层(Cloud Services)
最后是云服务层(Cloud Services),云服务层也运行在云提供商提供的计算实例上,云服务层负责了访问控制,查询优化,事务管理,管理虚拟仓库等功能,在多用户间共享体现了多租户性。云服务层的查询优化采用自顶向下的基于成本的 Cascades-style;在并发控制上,通过快照隔离(Snapshot Isolation,SI)实现 ACID 事务,Snowflake 还使用快照来实现 Time Travel 和数据库对象的高效克隆。Snowflake 不是基于 B+ 树或者类似结构形式的索引来实现的,它采用的是一种剪枝(pruning)的方法,系统维护相应数据块,例如表文件等数据分布信息,特别是块内的最小值和最大值,可以用于确定给定查询所可能不需要的数据块,这种元数据通常比实际数据小几个数量级,存储开销小,访问速度快。同时云服务层每个服务都被复制以实现高可用性和扩展性,单个服务节点的故障不会导致数据丢失或可用性下降。
易用性
Snowflake 提供了全面的 SQL 支持,标准的接口支持,友好的用户界面,纯粹的 SaaS 体验,用户不需要进行调优,不需整理存储,不需要进行物理设计,根据需要获得弹性计算支持,可以从本地和云上导入数据,监视管理相关信息,易用性好。
持续可用性
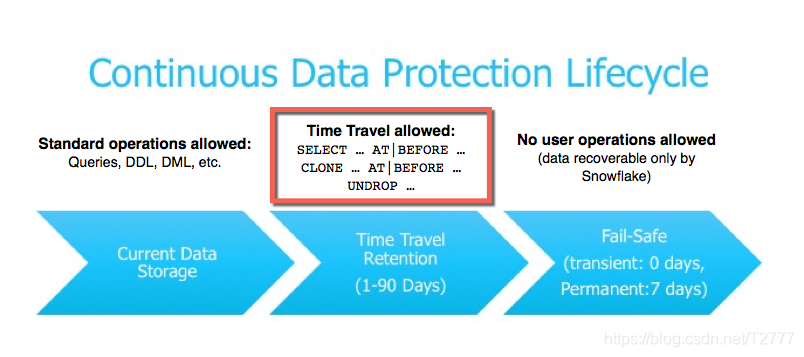
从持续可用性(Continuous Availability)来说,即令系统始终处于运行状态,Snowflake 在体系结构的所有层级上都能容忍节点故障,在数据存储层跨多个数据中心进行复制,云服务层的元数据存储也是如此,在一个节点发生故障时,其它节点可以在不影响最终用户的情况下接管任务。虚拟仓库层为了高吞吐量,不分布在多个数据中心,在查询失败时,会选择替换结点等方式重新执行。在软件升级时,将新版本的服务和以前的版本一起部署,然后逐渐切换到新版本,相应用户的新查询都被定向到新版本,直到所有以前的查询结束,以前版本的所有服务都将被终止和停用。
Snowflake 还提供了 Time Travel 机制允许在一定时间范围内对历史数据进行访问(即已更改或删除的数据),支持数据 Clone 来进行灾难恢复和故障转移,使用 Fail-Safe 机制确保发生系统故障或其它灾难性事件时保护历史数据。
支持半结构化和非结构化数据
Snowflake 支持半结构化和 Schema-Less 数据处理,用户可以将 Json,XML 等格式的输入数据直接加载到变量列中,Snowflake 处理解析和类型推断,以混合列格式存储数据。
安全性
在安全性上,Snowflake 提供了基于用户角色的细粒度访问控制,使用加密型强的 AES-256 加密,基于分层密钥模型实现了端到端的数据加密和安全性。
弹性
在弹性上,存储和计算资源可以自动,独立无缝地伸缩,不会影响数据可用性以及并发查询的性能,用户只需为实际使用的资源付费。
2. Snowflake 使用方法
Snowflake 是一个 OLAP 系统,官网:https://www.snowflake.com/
注册
Snowflake 提供了免费试用的机会,我们可以注册一个试用账号,有试用时间限制,会免费获得一些积分来使用,用完为止。注册地址:https://signup.snowflake.com/
最好使用 outlook 邮箱注册,国内邮箱可能发生注册失败的情况,注册成功后选择 Snowflake 的版本,下面的三种都可以选择,这里选择了 Enterprise 版,云提供商选择 AWS,地区选择亚洲。

注册成功后进入到 Snowflake 使用界面:

使用
免费账号有一些free credits,当使用虚拟仓库加载或执行操作时会消耗,在免费使用期间存储是不消耗点数的,不用的时候最好挂起。
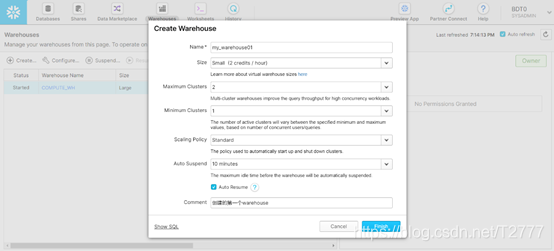
仓库可以手动创建,并且调整大小,不同的消耗点数不同,这里设置10分钟自动挂起,可以选择多个cluster,更多的cluster会使得吞吐率上升,每次执行时都可以指定用哪个数据仓库进行执行。
将用户角色改为 accountadmin后可以看到多了account功能,可以查看自己的积分点数credits使用情况:

Snowflake 自带了几个样例数据库以及样例查询,比如测试数据库性能的标准测试样例 TPC-H 以及 TPCDS,可以进行测试:
TPC-H是决策支持基准。它由一套面向业务的临时查询和并发数据修改组成。选择查询和填充数据库的数据具有广泛的行业范围相关性。该基准测试说明了决策支持系统,该系统可检查大量数据,高度复杂地执行查询并为关键业务问题提供答案。
- TPCH_SF1:由基本行大小(几百万个元素)组成
- TPCH_SF10:由基本行大小x 10组成。
- TPCH_SF100:由基本行大小x 100(几亿个元素)组成。
- TPCH_SF1000:由基本行大小x 1000(数十亿个元素)组成。
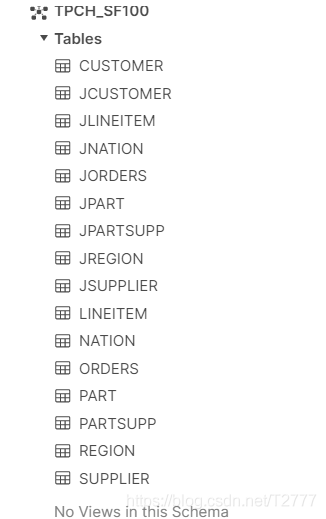
样例数据库中共有 16 个表,以 J 开头的其实就是半结构化数据存储,Json 格式的:

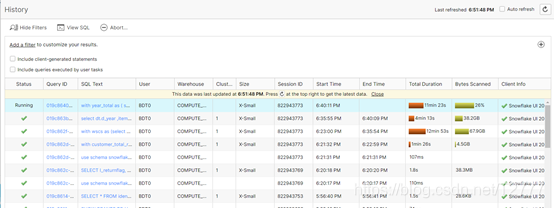
可以查看执行历史:
加载数据演示
在web端新建database,这里就像使用常见的本地数据库如 MySQL 和 SQLServer 一样。
新建database:
create database my_db01;创建完成database后,不用创建 schema了,因为有一个默认的schema叫做 public

执行下面的命令创建表:
create table flight_record ( Hour string, Req string,
Airport string, CNT string );删除可以用:
drop table flight_record;接着到表中选择加载数据,加载数据需要用到虚拟仓库,同样消耗点数:

我们可以将本地准备好的 FightRecord.csv文件导入

注意csv的每一行的名称顺序都要和表的列的名称和顺序保持一致。文件是我本地的一个测试文件FlightRecord.csv,有15000行数据。
file format 可以选择跳过:
导入成功:
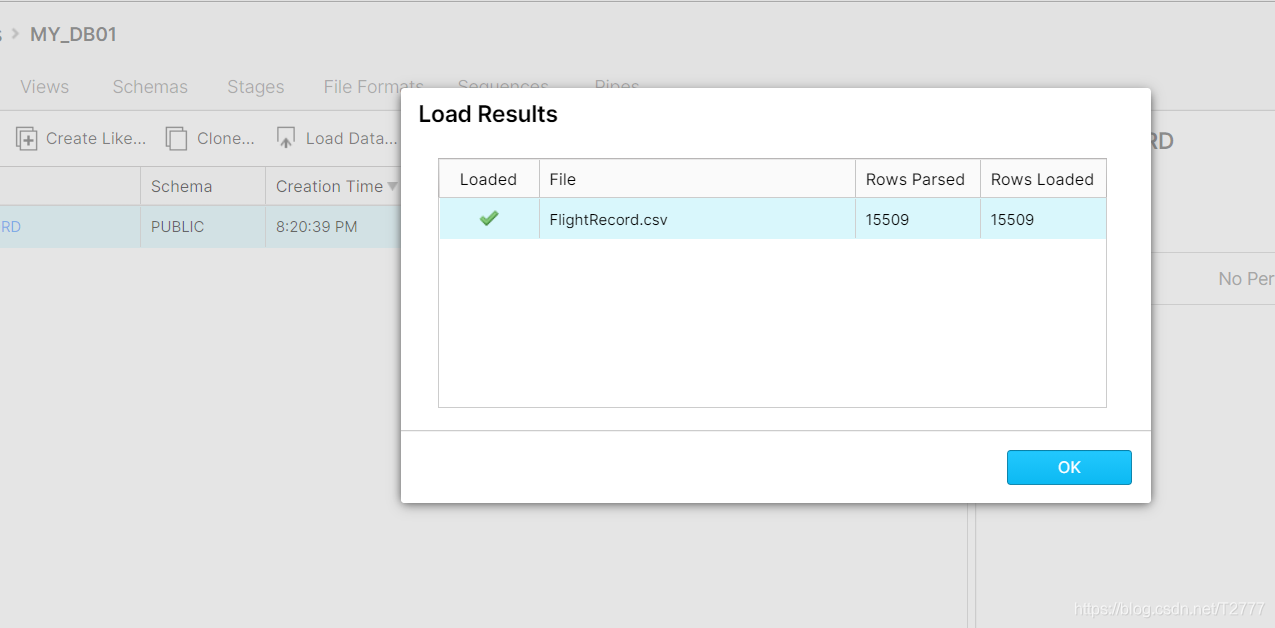
这个过程会因为使用 warehouse 而消耗点数:

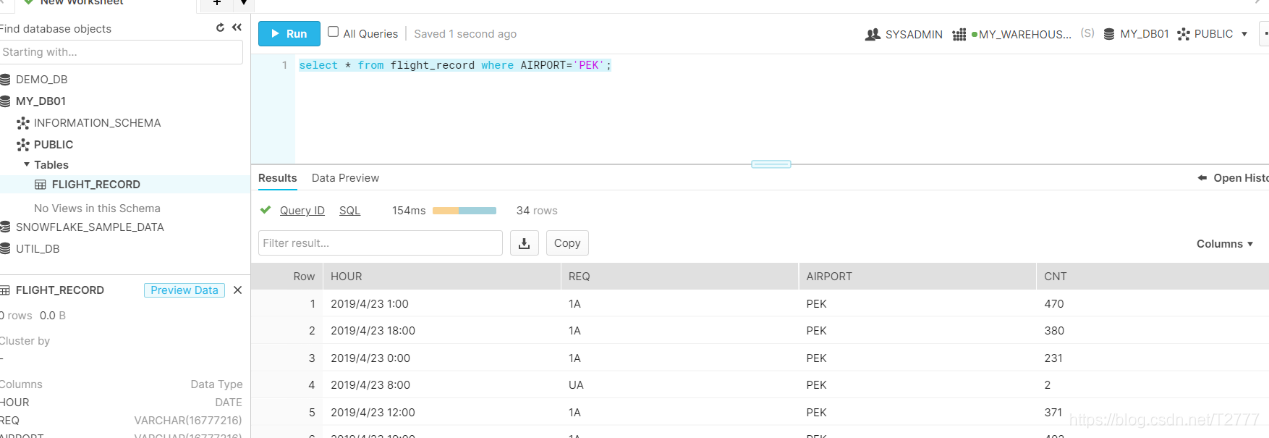
完成数据加载后就可以执行查询了:
3. 总结
本文简单介绍了 Snowflake 的基本架构和原理,以及 Snowflake 的简单使用方法,Snowflake 处于发展阶段,目前的盈利状况其实并不是很好,云原生既是优点也是缺点,AWS 等云提供商也有自己的相似产品。Snowflake 没有正式进入中国,考虑到外国互联网公司在中国屡屡碰壁,加上没有什么技术壁垒,国内也不乏优秀的云 AP 类产品,对它未来的发展我持保留态度🧑🏻。
参考文献
[1]B. Dageville, T. Cruanes, M. Zukowski, V. Antonov, A.Avanes, J. Bock, J. Claybaugh, D. Engovatov, M. Hentschel, J. Huang, A. W. Lee, A. Motivala, A. Q. Munir, S. Pelley, P. Povinec, G. Rahn, S. Triantafyllis, and P. Unterbrunner. The snowflake elastic data warehouse. In Proc. 2016 Int. Conf. on Management of Data, SIGMOD ’16, 2016.
[2]“Snowflake,”https://docs.snowflake.com/,2021.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)