【ICLR2020 论文笔记】可用于文本推理的模块神经网络( Neural Module Networks + NLP + reasoning)
Neural Module Networks for Reasoning over Text ; Nitish Gupta, Kevin Lin, Dan Roth, Sameer Singh & Matt Gardner; University of Pennsylvania, Philadelphia, University of California, Berkeley, Unive
Neural Module Networks for Reasoning over Text ; Nitish Gupta, Kevin Lin, Dan Roth, Sameer Singh & Matt Gardner; University of Pennsylvania, Philadelphia, University of California, Berkeley, University of California, Irvine, Allen Institute for AI
原文:https://arxiv.org/pdf/1912.04971v2.pdf
源码:https://github.com/nitishgupta/nmn-drop ** (official)本身基于 AllenNLP 工具
另附一个 pytorch 实现:https://github.com/COMP6248-Reproducability-Challenge/COMP6248-Reproducability-Challenge-NMN-Drop-for-Reasoning-Over-Text
文章目录
1 introduction
本文同理针对需要多跳推理的问题;这里首先解释一下几个概念:
- KBQA:基于知识图谱的问答(KBQA) = knowledge base question answering,也就是在三元组上进行推理和查找最后得到答案
- 机器阅读理解:多针对自然语言形式的文章,而非已经提取的三元组的形式
- 多跳推理问题:可以直观地理解为需要多次跳转,将不同的信息进行进一步整合才能得到答案的问题(多跳阅读理解也就是基于自然语言形式的文章,同理知识图谱领域也存在多跳推理)。这里还是用 CogQA (论文笔记戳这里) 的图举个例子:
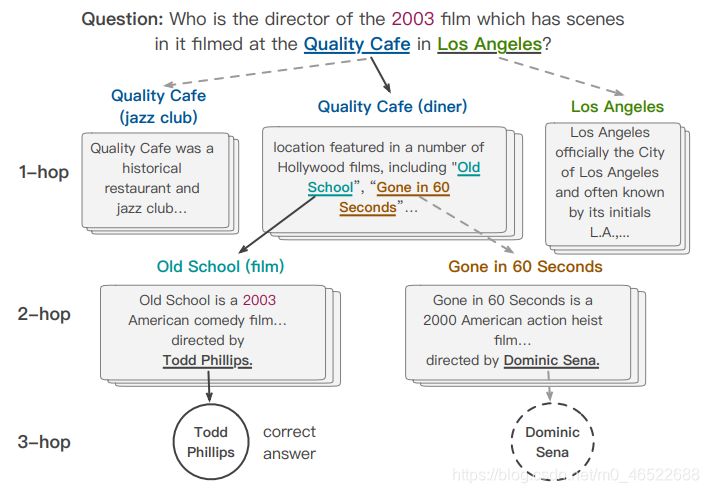
这个问题本身问的是导演,但是没有给出电影的名字,首先需要后面的信息去推断是哪一部电影,才能进一步去寻找该电影的导演。也就是说这里问题的解决需要一个中间的推理步骤(也就是得到 //电影名称// 的中间步骤,这里的电影名称也可以称为 bridge entity)才能得到最终的答案
然而,除去上面此类需要查找中间实体来进行类似于 “多步搜索” 的问题,多跳阅读理解问题同时涉及符号推理问题(例如排序 / 数数问题
举个例子:

这里不仅是需要寻找对应的 bridge entity,不仅是需要得到一条连接初始实体和最后的答案实体的推理链,而是需要进行信息提取 + 排序 再得到最终的答案。
由此总结,多跳推理问题的解决主要包括以下几个步骤:
- 理解复杂问题的结构:考虑上面的例子,此时问题 = 谁 + 第二季度(限定) + 最长,首先需要模型理解这个问题的结构 → 也就是(先找到第二季度限定)下的所有得分 → 再比较 → 得到最长
- 从问题精确提取信息:还是上面的例子,这里需要模型能够精确提取到 lengths / kickers / filed goal 等词汇,并从文中确实地找到相关信息
- 执行符号推理:上面的问题也就是需要对提取到的数字作排序操作 + 得到最长的 → 对应得到最后的答案
综上,本文尝试将 模块化的神经网络 Neural module networks (NMNs; Andreas et al., 2016) 用于解决多跳推理问题。
(实际上 NMNs 已经在 VQA(视觉问答)领域取得了一定的成果(例如 CLEVR),但是针对 nlp 领域的应用还十分有限
2 模块神经网络 Neural Module Networks
先说说所谓的模块神经网络
还是考虑上面给出的问题:
Who kicked the longest field goal in the second quarter?
按照正常人类的思维,读到问题后需要的步骤为:
- 先找出所有的 field goal 的实例
- 再找出其中符合限定 in second quarter 的
- 找到它们的 lengths(来自于 longest)
- 再比较得到其中最长的(比较 / 排序
- 找到谁踢的作为最终答案
而 NMNs 读到上述问题后,会将问题拆解为几个可执行的模块,比如上面的问题可以拆解为:
r
e
l
o
c
a
t
e
(
f
i
n
d
−
m
a
x
−
n
u
m
(
f
i
l
t
e
r
(
f
i
n
d
(
)
)
)
)
relocate(find-max-num(filter(find())))
relocate(find−max−num(filter(find())))
先执行最内部的 find = 找到所有的 field goal 的示例,再 filter(符合 in second quarter 的限定)再 find-max-num 取最大值,再找到是谁踢的(relocate)
综上,将 NMN 应用于推理问答,需要:
-
定义 Modules 模块,这里可能的模块限定于预先定义好的几种,具体的功能在后面介绍:

-
得到上下文表示:这里采用 预训练模型 + embedding 的形式得到问题和上下文的 embedding,分别用 BERT 和 双向 GRU 两种方式实现
-
实现 问题分解 Question Parser:也就是将问题分解为上述定义好的可执行模块,这里同时利用到了 encoder-decoder 和注意力机制
-
训练 模块执行器:也就是训练得到每一个模块,以实现将规定各式的输入给定时(比如给定数字,给定文本,给定日期形式的输入),可以得到我想要找到的输出
综上,此时整体模型的框架如下图所示:

3 整体模型
3.1 问题分解 question parser
首先通过双向 GRU 或 BERT 得到问题的 embedding,利用 GRU 的最后一层的 ht 或 BERT 中的 [CLS] 的 embedding 作为输入,也就是说这里的输入应该是整个问题句子的语义信息
这里选择 LSTM 作为 decoder(见原文附录2,但是 encoder 具体用的是什么好像没有点名,下次读读源码),将我们定义好的 10 种模块作为 vocabulary 来实现问题的分解(具体做法将每一个模块都转化为一个 100 维的 embedding),中间涉及注意力机制的计算是 decoder 和 encoder 的隐藏层之间的
具体 question parser 的结构原文没有给明,还需要读读源码看。总体的结构是 encoder + decoder 的形式,将 10 种模块转化为 embedding 作为最后的 decoder 部分输出用到的 vocabulary
注意这里使用 LSTM 还有别的原因,因为定义的 10 个模块本身存在输入和输出的格式限制(比如 find-num 的输出一定要是 N,但是 find-num 的输入一定要是文段 P,此时如果 find-num → 输出 N → 后面再跟着一个 find-num,则此时的分解就是非法的。而 LSTM 存在(将前一个已经生成的模块再作为下一个生成的输入利用)的特点,此时可以利用 LSTM 的这个特性控制不要生成问题的非法分解。
3.1 定义模块 module
这里共预先定义了 10 种模块,NMN 也就是用这 10 种模块来表示问题,分别训练每一种模块,再同通过按分解顺序依次执行对应的模块得到最后的答案:
注意这里定义的模块可以分为两种:
- 自然语言推理:也就是从文中找到信息的步骤
- 符号推理:也就是通过得到的信息来进行客观意义上的推理得到最后的答案(比如计算差值,计数,取最大值,排序等等
这里两种类型的模块分别定义了五种:

这里的 In 和 Out 表示:

以下分别介绍每一个模块:
-
f i n d ( Q ) → P find(Q) \rightarrow P find(Q)→P:也就是输入问题,找到和问题相关的语段;具体利用注意力机制:先计算对应文段的各个 token 和问题的各个 token 之间的相似度矩阵,记作 S;对应的 S 的 i,j 位置元素定义为: S i j = w f T [ Q i . ; P j . ; Q i . ∘ P j . ] S_{ij} = w_f^T[Q_i. ; P_j. ; Q_i. \circ P_j.] Sij=wfT[Qi.;Pj.;Qi.∘Pj.]这里的 wfT 是待学习参数;对应的 o 是 elementwise 的乘法;对应得到 S 矩阵后通过 softmax 得到文段和问题之间的注意力矩阵 A,通过注意力的方法从给定的上下文文段中得到最后的输出 P
-
f i l t e r ( Q , P ) → P filter(Q,P) \rightarrow P filter(Q,P)→P:也就是通过问题中的限定条件来从给定的 P 中筛选出一部分符合的 P 文段;举例就是上面的问题中实现 in second quarter 的限定条件的部分。实际理解也就是 mask 掉一部分 P 中的内容(不符合的就 mask 掉),则此时计算文段 P 的第 j 个 token 对应的 masking score: M j = σ ( w f i l t e r T [ q ; P j . ; q ∘ P j . ] ) M_j = \sigma(w_{filter}^T[q ; P_j. ; q\circ P_j.]) Mj=σ(wfilterT[q;Pj.;q∘Pj.])这里的小 q 通过问题的 embedding = Q 来计算: q = ∑ i Q i Q i . ∈ R d q = \sum_i Q_i Q_i. \in R^d q=∑iQiQi.∈Rd,对应的 σ 是 sigmoid 函数,同理 wfT 是可学习参数,最后对应的输出 P 通过下式得到: P f i l t e r = n o r m a l i z e ( M ∘ P ) P_{filter} = normalize(M \circ P) Pfilter=normalize(M∘P)
-
r e l o c a t e ( Q , P ) → P relocate(Q,P) \rightarrow P relocate(Q,P)→P:也就是依据问题重新定位,举例就是依照上面的例子,找到 longest 的 field score 后需要找到 who kick;首先计算 P 对 P 的注意力矩阵: R i j = w r e l o c a t e T [ ( q + P i . ) ; P j . ; ( q + P i . ) ∘ P j . ] R_{ij} = w_{relocate}^T [(q+P_i.) ; P_j. ; (q+P_i.)\circ P_j.] Rij=wrelocateT[(q+Pi.);Pj.;(q+Pi.)∘Pj.] q = ∑ i Q i Q i . ∈ R d q = \sum_i Q_i Q_i. \in R^d q=i∑QiQi.∈Rd得到 R 后经过 softmax,最后的输出通过 P l o c a t e d = ∑ i P i R i . P_{located} = \sum_i P_i R_i. Plocated=∑iPiRi. 得到
-
f i n d − n u m ( P ) → N / f i n d − d a t e ( P ) → D find-num(P)\rightarrow N / find-date(P) \rightarrow D find−num(P)→N/find−date(P)→D:同理是计算对应的文段 P 和文段中的数字 / 日期部分之间的相似度矩阵。以数字为例,假设此时文段 P 中存在 N t o k e n N_{token} Ntoken 个数字,每一个数字也就是一个 token,则此时计算对应的相似度矩阵 S n u m S^{num} Snum: S i j = P i . T W n u m P n j . S_{ij} = P_i.^T W_{num} P_{n_j}. Sij=Pi.TWnumPnj. 这里的 Pnj 也就是第 j 次提到的数字对应的 token;对 S 作 softmax 后得到 A,并通过 T = ∑ i P i A i . n u m T = \sum_i P_i A_i.^{num} T=∑iPiAi.num 得到每一个提及对应为答案的概率,再得到最后的输出。注意这里如果两次提及都是相同的数字,需要将两次提及对应的概率相加;比如此时提及为 2234,对应的概率为 0.1 0.4 0.3 0.2,则此时答案为 234 的概率分别为 0.5 0.3 0.2;对应日期同理
-
c o u n t ( P ) → C count(P) \rightarrow C count(P)→C:这部分挺复杂的,建议直接看原文部分可能更清楚一些 … 本质的思想是计算注意力向量中连续相同的多个值的 span 大小,比如如果这里的向量为 0.3 0.3 0.2 0.4,则输出为 2(因为两个相同的 0.3 存在)。首先利用(一个奇怪的初值)[1,2,5,10] 作为权重来得到 P s c a l e d ∈ R m ∗ 4 P_{scaled}\in R^{m*4} Pscaled∈Rm∗4,再扔进一个双向 GRU 得到隐藏状态 ht,再通过单层前馈和 sigmoid 得到对应的 c v c_v cv,也就是 c v = ∑ σ ( F F ( c o u n t G R U ( P s c a l e d ) ) ) c_v = \sum \sigma(FF(countGRU(P_{scaled}))) cv=∑σ(FF(countGRU(Pscaled)))这里用到正态假设,认为最后的答案是以 cv 为均值,方差为 0.5 的数,则此时对应计算答案 c: p ( c ) ∝ e x p ( − ( c − c v ) 2 / 2 v 2 ) p(c) \propto exp(-(c-c_v)^2/2v^2) p(c)∝exp(−(c−cv)2/2v2)
-
c o m p a r e − n u m − l t ( P 1 , P 2 ) → P compare-num-lt(P1, P2) \rightarrow P compare−num−lt(P1,P2)→P:此时要求输出的 P 是较小的一个。首先将 P1 和 P2 扔进 find-num 的那个模块中,对应得到数字 N1 和 N2。注意这里的 find-num 得到的模块是(多个数字提及)和(其对应的概率)的形式,则此时计算概率:
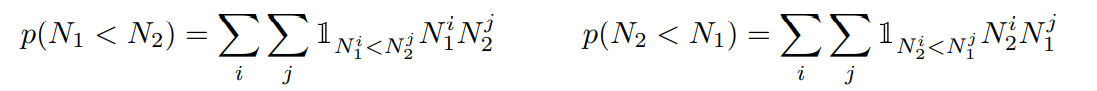
对应得到最终的输出 Pout: P o u t = p ( N 1 < N 2 ) ∗ P 1 + p ( N 2 < N 1 ) ∗ P 2 P_{out} = p(N_1<N_2) * P_1 + p(N_2<N_1)*P_2 Pout=p(N1<N2)∗P1+p(N2<N1)∗P2,随着训练不断进行,对应的两个 P 会不断接近边界 0/1,则此时对应的 Pout 也就是 P1 和 P2 二者其一 -
对应的 c o m p a r e − n u m − g t , c o m p a r e − d a t e − l t , c o m p a r e − d a t e − g t compare-num-gt , compare-date-lt, compare-date-gt compare−num−gt,compare−date−lt,compare−date−gt 和上面的处理方法相似,在此不再赘述
-
t i m e − d i f f ( P 1 , P 2 ) time-diff(P_1, P_2) time−diff(P1,P2):同理先通过 find-date 得到两个 P 对应的 D1 和 D2,同理这里的 D1 和 D2 是带有概率的日期列表,则计算 D1i 和 D2j 之间的差值,再对应乘上相关的概率,求加权平均。对应的概率计算: p ( t d ) = ∑ i , j 1 ( d i − d j = t d ) D 1 i D 2 j p(t_d) = \sum_{i,j} 1_{(d_i-d_j = t_d)} D_1^i D_2^j p(td)=∑i,j1(di−dj=td)D1iD2j
-
f i n d − m a x − n u m ( P ) find-max-num(P) find−max−num(P):同理先通过 find-num 提取出数字列表,注意这里实际上是得到了文段中每一个数字提及对应的概率,记作 T,也就是第 j 个提及对应一个概率 Tj;再计算 Tmax,这里是通过抽样的方式实现的,原文比较清楚:

最后通过 P i = ∑ j T j m a x / T j P i A i j . P_i = \sum_j T_j^{max} / T_j P_i A_{ij}. Pi=∑jTjmax/TjPiAij. 计算出我的输出结果 P -
s p a n ( P ) → S span(P) \rightarrow S span(P)→S:也就是输出两个向量,分别表示每一个 token 是 start 或 end 的概率,训练方式和 count 相似,详细部分见原文的附录部分。
3.3 模型训练
注意到前面的模块是很复杂的,先需要训练问题分解部分,还要再训练模块本身的功能,如果直接利用端到端训练会很难
这里使用 auxiliary training 的方式来完成模型训练。
-
模块功能的无监督训练:针对 find-num / find-date / relocate 三个模块,本身的作用也就是从 P 文段中提取信息,这里希望在数字 / 日期提及周围的 token 能够得到更高的关注,则此时控制窗口大小 W = 10,希望在提及 mention 的窗口范围内的 token 能够有更高的 attention,对应损失函数设置为:
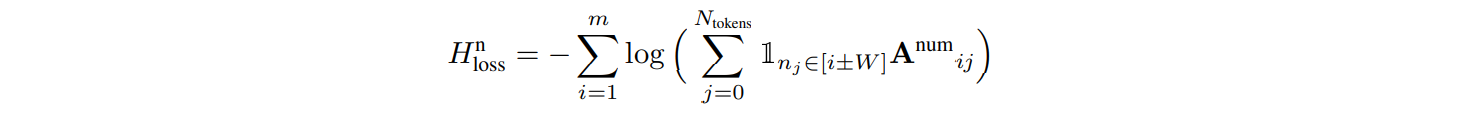 此时这三个模块对应在一起训练,此时对应的总损失函数 = 三个模块对应的损失函数的加和
此时这三个模块对应在一起训练,此时对应的总损失函数 = 三个模块对应的损失函数的加和 -
问题分解的有监督训练:这里由于本文使用的是 DROP 数据集,并没有任何关于问题分解的标签可用,这里作者直接选取了约 10% 的问题人工手动分解为几个模块来训练 question parser 部分。则此时的训练部分和带 LSTM 的 encoder + decoder 模型相同
-
模型输出的监督学习:这里存在真实答案所以可以直接进行监督学习。同时考虑到对于(最短的是什么?)类似的问题,对于 find-num 模块,真实答案只是帮助模块确认了是否找到了最小的那个 num,对于其他的 num 的寻找不存在监督作用,长此以往的训练会导致 find-num 就只倾向于找到较小的 num,而导致整体模型的有偏。为了缓解这一问题,这里对约 5% 的可能出现类似情况的问题加入噪音,比如对于 (A 的最短 xxx 是多少) 的问题,我们认为离 A 最近的一个数字本身也应该作为 find-num 的一个输出存在。将这样的噪音加入训练集,和真实答案一同进行模型的监督学习
4 experiment 实验部分
这里使用的是 AllenNLP 的 DROP 数据集来进行实验
DROP 本身是一个融合了实体查找(也就是自然语言推理部分,本身是 bridge 实体的提取和信息的综合)和符号推理(也就是客观推理部分,比如排序,求最大值etc)的数据集,这里选用 DROP 来进行实验
注意由于这里的推理能力是很有限的(本身只是定义了 10 种类型的 module),原文作者筛选了 20000 个符合相关类型的问题来作测试(也就是集中于讨论 数字类,比较,日期计算 etc 之类的问题)
此时得到的问题本身可以分为六类:

实验结果:

可以看到这里的提升还是比较明显的,同时初始的问题和文段的 embedding 对应的预训练模型对于整体模型效果还是影响很大的(GRU 对应的模型效果非常不行),本身从模型构造的角度来说也能感觉得到它很依赖初始 embedding 的质量(比如不停进行相似度矩阵计算 etc)
同时问题暴露也比较明显。作者给出了三类较为典型的回答错误的问题:

最后胡说几句:
个人认为还是模块设计本身对整体模型带来巨大限制;1)10个预设置的模块只能帮助模型解决数学类的符号推理问题,对于需要利用逻辑规则等的,更自然语言或人类常识方向的推理,由于其本身的多样性直接预设值模块是根本不可行的;2)LSTM 作为 decoder + 模块本身的输入输出限制 使得模块本身的组合有限(比如不能连着两个 find-num,只能是链状结构不能为树状;
但是对于类似于数值推理之类的,本身规则类别较少的推理问题或许这是一个可借鉴的思路,预先设计模块 + 把模块 embedding 了作为 vocabulary 来辅助 question parser 这种思路是真的很有意思hhh 一眼看上去会觉得 哇 的那种程度 …
还有就是模型太多的细节论文没讲清楚,特别是 question parser 部分和训练部分,正文动不动指向附录但是附录还是啥都没说明白 … 或者是我没读明白也说不定hhh(有机会还是看看源码吧(
阅读仓促,存在错误 / 不足欢迎指出!期待进一步讨论~
转载请注明出处。知识见解与想法理应自由共享交流,禁止任何商用行为!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)