
一文搞懂Flink State如何实战。ValueState实现最大状态值计算
一、什么是state流式计算场景,简单的说就说来一条数据就处理一条数据,对数据进行实时处理。这个时候就会自然而言的有一类需求,我的业务逻辑依赖之前我已经输入的数据。举一个场景就是Flink程序接收Kafka传输过来的数字,例如1到100的随机数。业务需求是输出收到的最大数字。比如按顺序收到的是0,10,2,3,4,5,应该输出的最大数是10。显然在这个处理过程中,需要一种机制来记录前面收到的信息。
一、什么是state

流式计算场景,简单的说就说来一条数据就处理一条数据,对数据进行实时处理。这个时候就会自然而言的有一类需求,我的业务逻辑依赖之前我已经输入的数据。
举一个场景就是Flink程序接收Kafka传输过来的数字,例如1到100的随机数。业务需求是输出收到的最大数字。比如按顺序收到的是0,10,2,3,4,5,应该输出的最大数是10。显然在这个处理过程中,需要一种机制来记录前面收到的信息。这种机制就是Flink里面的state,记录前面输入的数据。
二、Flink中的state
2.1 Flink State基本概念

Flink支持状态流处理的分布式计算系统。从分布情况来讲,Flink Jobs是由operator组成,每一个operator的执行在物理上都会被几个并行的operator实例。从Flink的设计理念出发,Flink并行Operator实例是一个可以集群上单独运行的实例。出于避免不必要数据传输的理念,所有的state数据都是保留在本地机器上。
在Flink中,State主要有两种基本类型:KeyedState 和 Operator State。因常用KeyedState,故只对keyedState进行详细介绍。
2.2 Flink keyedState基本编程模型
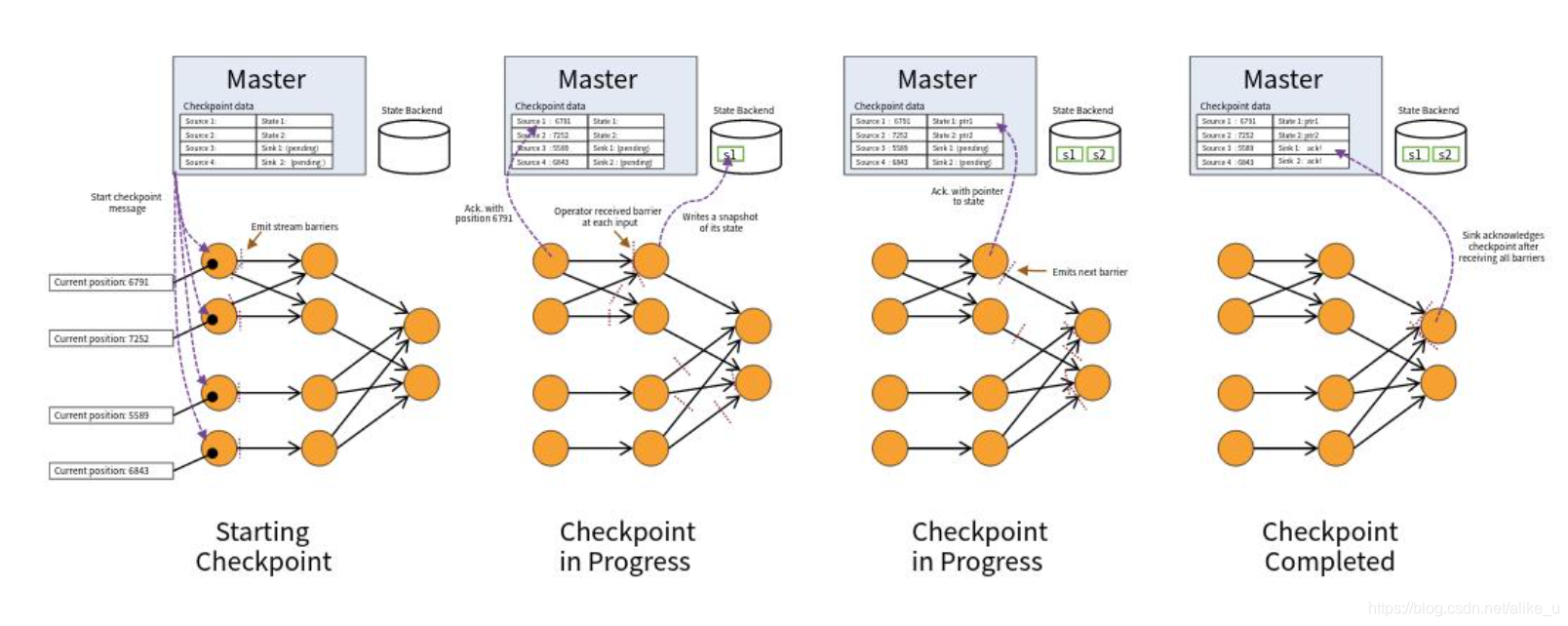
(这部分内容出自对官方文档的理解和学习,如有疏漏之处,请多多指教。)
Keyed State顾名思义就是被key过的状态,这里其实就是大数据编程中常见key的概念,也就是使用某个属性对全体数据进行分区,比如 reduce by key,Group By key,这里就是根据key对状态进行计算。
在Flink中,State有两种形式,一种是Flink自身提供的,另外一种是自己编码实现的。Flink自身提供的state,有很多自动机制,就是任务并行度增加时,state的状态也可以分发。自己编码的State,那些自动机制就需要自己编码实现。Flink官方文档优先推荐使用Managed State。下面这些State我自己的理解(https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/stream/state.html#keyed-state):
-
ValueState: 记录单个值的 -
ListState: 列表值,同类型的可以记录一串串 -
ReducingState: 聚合相加的算子 -
FoldingState: 支持聚合函数 -
MapState: 存储k,v类型的
2.3 Flink State编程套路
Flink State编程,我的理解是1、声明一个状态变量 2、通过上下文获得一个状态变量 3、对状态变量进行取值,赋值的操作。下面以一个RichFlatMapFunction为例,来介绍State的使用。这里需要注意的是:首先是State的存取,需要使用RuntimeContext来读取,所以只能在RichFunction中使用。其次是State的存储方式是可以选择,再就是keyed State的值是和key绑定的。
下面就是一个带有state的RichFlatMapFunction的实现。(如果还不能跑起来,评论区见)
# 输入输出是(Long,Long)
class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] {
# 声明State
private var sum: ValueState[(Long, Long)] = _
override def flatMap(input: (Long, Long), out: Collector[(Long, Long)]): Unit = {
// 读取State值
val tmpCurrentSum = sum.value
// State初始化
val currentSum = if (tmpCurrentSum != null) {
tmpCurrentSum
} else {
(0L, 0L)
}
// 获得当前和
val newSum = (currentSum._1 + 1, currentSum._2 + input._2)
// 更新Stata值
sum.update(newSum)
// 输出State,并将State进行清空
if (newSum._1 >= 2) {
out.collect((input._1, newSum._2 / newSum._1))
sum.clear()
}
}
override def open(parameters: Configuration): Unit = {
sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
}
}
object ExampleCountWindowAverage extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromCollection(List(
(1L, 3L),
(1L, 5L),
(1L, 7L),
(1L, 4L),
(1L, 2L)
)).keyBy(_._1)
.flatMap(new CountWindowAverage())
.print()
// the printed output will be (1,4) and (1,5)
env.execute("ExampleManagedState")
}

Kafka开源项目指南提供详尽教程,助开发者掌握其架构、配置和使用,实现高效数据流管理和实时处理。它高性能、可扩展,适合日志收集和实时数据处理,通过持久化保障数据安全,是企业大数据生态系统的核心。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)