语音识别概述
什么是语音识别?英文解释就是:Automatic Speech Recognition(ASR) 或者Speech to Text(STT)就是将语音信号转换成文本,但是注意以下几点:只负责解决机器听清问题,不负责听懂的问题;是要处理声学和(部分)语言上的混淆;. 如“帮我拿快递” or “帮我拿块地”解决“共性”问题:每个人的语音都能识别出正确的文本但是不能解决谁在说话(声纹识别)、话是怎么说的
什么是语音识别?
英文解释就是:Automatic Speech Recognition(ASR) 或者Speech to Text(STT)
就是将语音信号转换成文本,但是注意以下几点:
-
只负责解决机器听清问题,不负责听懂的问题;
-
是要处理声学和(部分)语言上的混淆;
. 如“帮我拿快递” or “帮我拿块地” -
解决“共性”问题:每个人的语音都能识别出正确的文本
但是不能解决谁在说话(声纹识别)、话是怎么说的(情感状态质量)、说的是什么意思(语言理解)
语音识别怎么评估呢?
准确率:
• 音素错误率 (Phone Error Rate)
• 词错误率 (Word Error Rate, WER)
• 字错误率 (Character Error Rate, CER)
• 句错误率 (Sentence Error Rate, SER)
• 实时率 (Real-time Factor, RTF)
下图就是一个统计错误率的一个例子:

其中Subdtitutions 是替换错误,Deletions是删除错误,Insertions是插入错误;
Ref:那一行是原本完整的数据;
Hyp:是识别出的数据;
第一个矩形框,是删除错误,指的是在识别过程中,THE没有识别出来、第二个矩形框是替换错误,将IN错误识别了IS、第三个矩形框是插入错误,本来没有ON却错误的识别了Ins、第四个矩形框也是插入错误;
则错误率就是,这些出现的错误与原先正确的字词的比值;
语音识别的分类
•说话人:特定人、非特定人
• 语种:单一语种、多语种
• 词汇量:大、中、小
• OOV:Out of Vocabulary
• 设备:云侧、端侧
• 距离:近讲、远讲…
语音生成
音素(Phonemes):一种语言中语音的“最小”单元(primitive sounds) 音素的维基百科
词/语素(morpheme):一种语言中最小的具有语义的结构单元
共振峰(formant)指在声音的频谱中能量相对集中的一些区域(语谱峰值),共振峰是一个很重要的概念;
- 共振峰不但是音质的决定因素,而且反映了声道(共振腔)的物理特征。
- 声音在经过共振腔时,受到腔体的滤波作用,使得频域中不同频率的能量重新分配, 一部分因为共振腔的共振作用得到 强化,另一部分则受到衰减,得到强化的那些频率在时频分析的语图表现为浓重的黑色条纹。
- 由于能量分布不均匀,强的部分犹如山峰一般,故而称之为共振峰
- 共振峰是被声道特别放大的频带; 由于不同元音在声道内不同位置产 生,不同元音会产生不同种类的放大或共振。
- 第一和第二个共振峰(F1和F2)对于区分不同元音尤为重要。
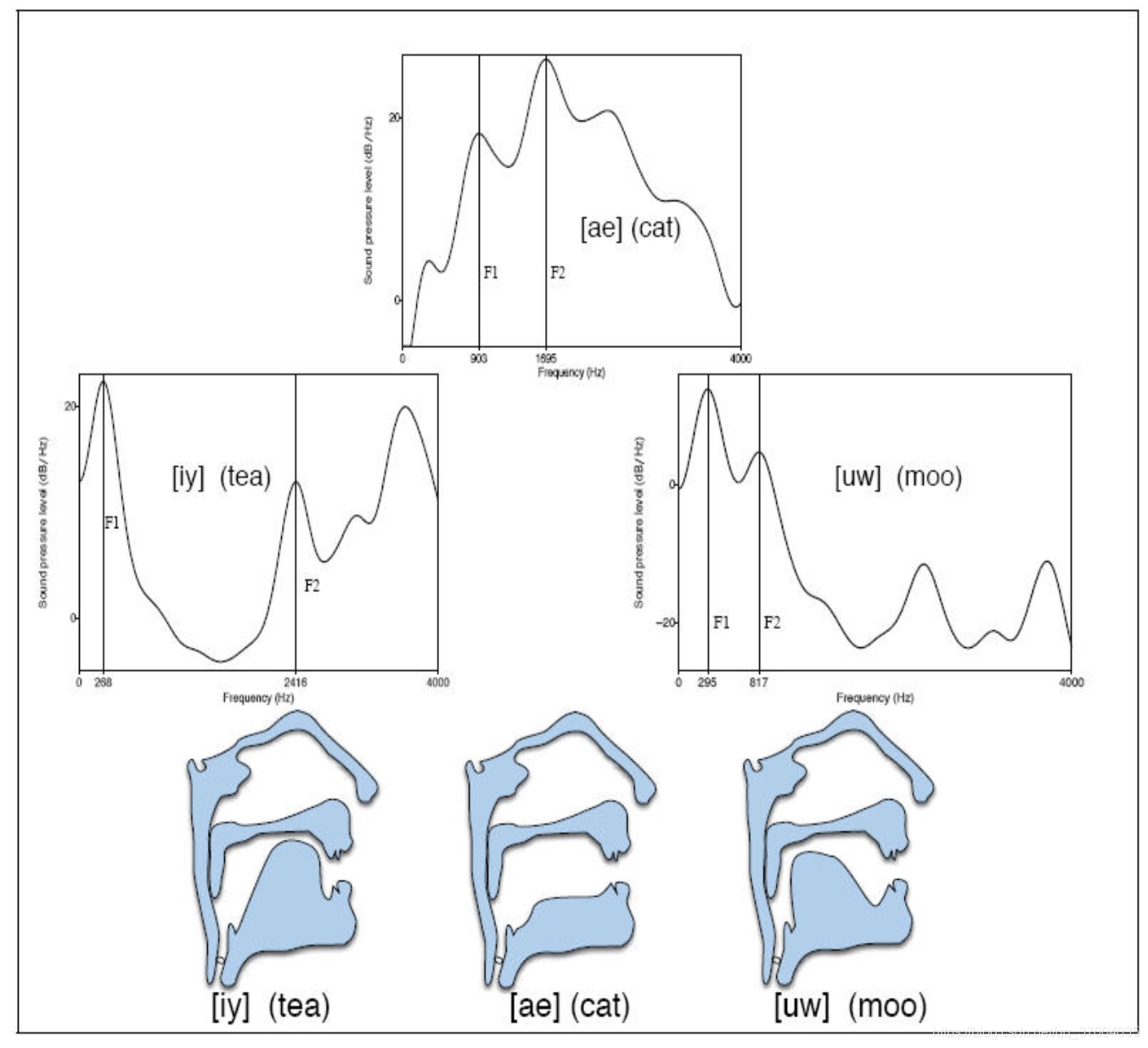
如图所示, 根据不同的振动峰,来区分不同的元音
协同发音:在发音的时候,一个词是受到上下文发音的影响的,这就叫做协同发音;音素在声学上的实现和上下文强相关
音素抄本:一段语音对应的音素列表,如下图所示

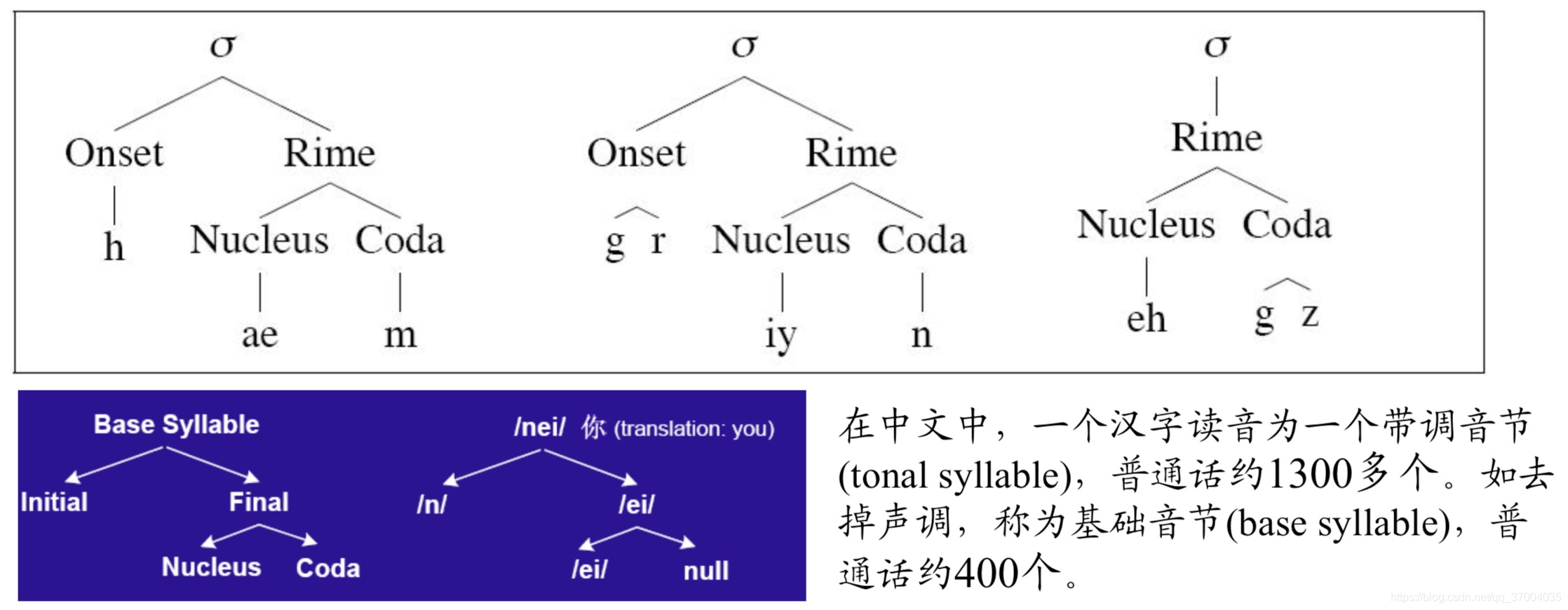
音节:元音和辅音结合构成一个音节
•在元音之前的辅音,叫作音节头(onset)或称声母(initial)
• 在音节头之后的元音及随后的子音被叫作韵母(rime)
• 而韵母里的元音叫作音节核(nucleus)
• 随后的子音叫作音节尾(coda)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)