MR应用开发 —— Hadoop权威指南10
1. Configuration —— Hadoop的配置API之前,在获取Hadoop文件实例时,经常会创建一个Configuration实例Configuration是Hadoop用于配置的API,是property和value的集合addResource():为Configuration指定配置文件。入参为resources中的xml文件名,Configuration可以从xml文件中获取p
1. Configuration —— Hadoop的配置API
- 之前,在获取Hadoop文件实例时,经常会创建一个
Configuration实例 Configuration是Hadoop用于配置的API,是property和value的集合
addResource():为Configuration指定配置文件。入参为resources中的xml文件名,Configuration可以从xml文件中获取property和value- 属性覆盖: 若通过
addResource()同时指定多个xml文件,同名的property的value,由后面的定义决定 - 例外: 如果该属性为
final属性,则无法被后续的定义覆盖 get():根据property,获取value;同时,可以指定默认值,当属性不存在时,则返回指定的默认值
基于Configuration的编程实例
-
config-1.xml文件如下:<?xml version="1.0"?> <configuration> <property> <name>color</name> <value>red</value> </property> <property> <name>length</name> <value>25</value> </property> <!-- final属性,无法覆盖--> <property> <name>weight</name> <value>60</value> <final>true</final> </property> </configuration> -
config-2.xml文件:<?xml version="1.0"?> <configuration> <property> <name>time</name> <value>2021-05-02 08:23:22</value> </property> <property> <name>length</name> <value>12</value> </property> <property> <name>weight</name> <value>32</value> </property> </configuration> -
程序示例:
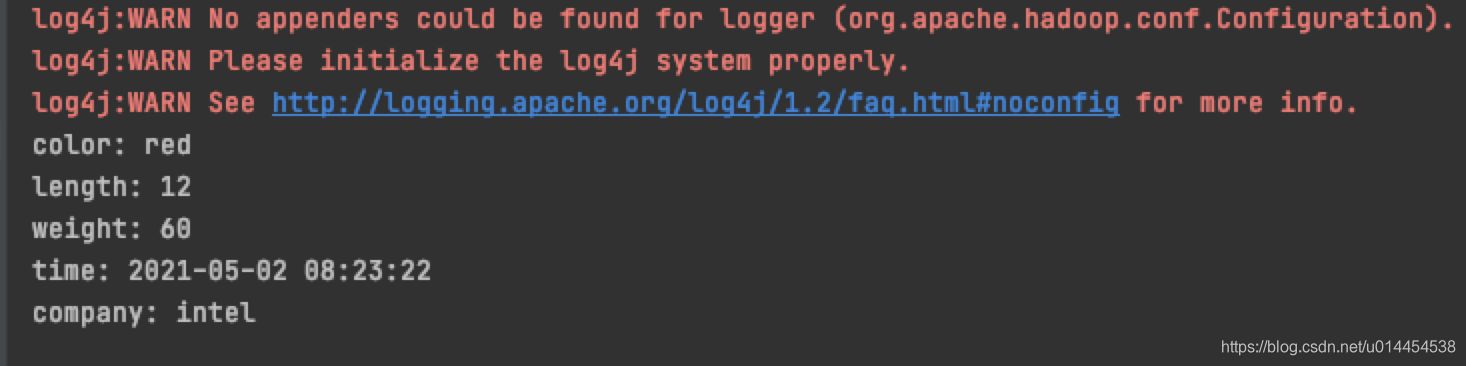
public class ConfigurationTest { public static void main(String[] args) { // 添加配置文件 Configuration configuration = new Configuration(); configuration.addResource("config-1.xml"); configuration.addResource("config-2.xml"); // 获取配置文件中的属性 System.out.println("color: " + configuration.get("color")); // 属性被覆盖 System.out.println("length: " + configuration.getInt("length", 0)); // 属性为final,不能被覆盖 System.out.println("weight: " + configuration.get("weight")); System.out.println("time: " + configuration.get("time")); // 属性不存在,返回默认值 System.out.println("company: " + configuration.get("company", "intel")); } } -
程序运行结果:
2. 开发环境的配置
2.1 默认配置的查看
- 在安装Hadoop时,总是需要配置各种各样的文件,如core-site.xml、hdfs-site.xml、yarn-site.xml等
- 这些配置文件,可以配置的属性和默认值,查看方式:
① 可以在安装包的share/doc中查看,例如core-site.xml对应core-default.xml
② 可以在官网的Configuration部分,将版本号改为对应的值即可

- 同时,不同版本的Hadoop属性,其名称可能有变化,例如MR属性:
mapred的前缀,已更新为mapreduce。
2.2 如何连接不同的集群
-
在通过hadoop fs命令,与Hadoop文件系统进行交互时,可以通过
-conf使用不同的配置 -
例如,一般Hadoop集群分为:单机、伪分布式、分布式,各自有不同的属性配置
-
假设本地文件系统的属性配置为
hadoop-local.xml,当想要连接本地文件系统,查看/user/hadoop/目录时,命令如下:hadoop fs -conf conf/hadoop-local.xml -ls /user/hadoop/ -
书中,还介绍了如何通过
Tool、ToolRunner来修改属性。 —— 自己没啥体会,暂不赘述 😂 -
还可以通过Hadoop的
-D来修改属性,其优先级高于配置文件中的属性。
-
使用方法:
# ConfigurationPrinter为一个Hadoop程序,用于打印Configuration中的配置属性 hadoop ConfigurationPrinter -D color=yellow | grep color -
可以在配置文件中,设置默认值,通过
-D设置正确值 -
Hadoop的
-D与property之间有空格:-D property=value,与Java的系统属性有差异:-Dproperty=value
2.3 MR程序的maven配置
-
编写MR程序时,需要添加一系列的maven依赖
<modelVersion>4.0.0</modelVersion> <groupId>com.lucy</groupId> <artifactId>hadoop-mr</artifactId> <version>1.0-SNAPSHOT</version> <!-- 设置公共属性 --> <properties> <hadoop.version>2.7.3</hadoop.version> </properties> <dependencies> <!-- HDFS或MR所需的client依赖--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!-- 单元测试的依赖 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <!-- MR测试的依赖--> <dependency> <groupId>org.apache.mrunit</groupId> <artifactId>mrunit</artifactId> <version>1.1.0</version> <!-- 使用hadoop2的mrunit--> <classifier>hadoop2</classifier> <scope>test</scope> </dependency> <!-- 在单个jvm中运行Hadoop集群进行测试--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-minicluster</artifactId> <version>${hadoop.version}</version> <scope>test</scope> </dependency> </dependencies> <build> <plugins> <!-- 设置jdk版本 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <target>1.8</target> <source>1.8</source> </configuration> </plugin> </plugins> </build>
3. mrunit + junit 编写MR单元测试
- 第一次写MR程序,程序非常简单,写完就放到Hadoop集群去运行了,根本没有进行单元测试
- 在真实的工作场景中,将不经测试的代码直接运行是不明智的决定
- 《Hadoop编程指南》介绍了,如何利用
mrunit和junit实现mapper和reducer的单元测试
3.1 mapper的单元测试
-
mapper函数的实现,是基于
org.apache.hadoop.mapreduce.Mapper类的:主要是统计除英语外,各科成绩public class ScoreMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 对输入数据进行切分 String line = value.toString(); String[] data = line.split(","); // 将非英语的成绩加入到map的输出 if (!"英语".equals(data[0])) { Integer score = Integer.valueOf(data[1]); context.write(new Text(data[0]), new IntWritable(score)); } } } -
编写对应的单元测试,
@Test注解是来自于junit,MapDriver来自于org.apache.hadoop.mrunit.mapreduce。 -
该单元测试非常简单,对一个输入,会产生map输出、不会产生map输出,两种情况进行了测试
public class ScoreMapperTest { @Test public void scoreMapperTest() throws IOException { Text text = new Text("语文,88"); // 通过MapDriver测试mapper函数 new MapDriver<LongWritable, Text, Text, IntWritable>() .withMapper(new ScoreMapper()) .withInput(new LongWritable(0), text) .withOutput(new Text("语文"), new IntWritable(88)) .runTest(); // 如果数据为英语,则无任何输出 text = new Text("英语,92"); new MapDriver<LongWritable, Text, Text, IntWritable>() .withMapper(new ScoreMapper()) .withInput(new LongWritable(1), text) .runTest(); } }
3.2 reducer函数的单元测试
-
reducer函数,统计各科成绩的最高分。
-
为了与
mrunit中的reducer对应,这里使用的是org.apache.hadoop.mapred.Reducer接口public class ScoreReducer implements Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text text, Iterator<IntWritable> iterator, OutputCollector<Text, IntWritable> outputCollector, Reporter reporter) throws IOException { // 获取每门科目的最高成绩 int max = Integer.MIN_VALUE; while (iterator.hasNext()){ IntWritable score = iterator.next(); if (score.get() > max){ max = score.get(); } } // 构建输出结果 outputCollector.collect(text, new IntWritable(max)); } @Override public void close() throws IOException {} @Override public void configure(JobConf jobConf) {} } -
对应的单元测试:
public class ScoreReducerTest { @Test public void scoreReducerTest() throws IOException { // 构建输入数据 Text key = new Text("数学"); List<IntWritable> scores = Arrays.asList(new IntWritable(87), new IntWritable(93), new IntWritable(72)); // 测试reducer函数 new ReduceDriver<Text, IntWritable, Text, IntWritable>() .withReducer(new ScoreReducer()) .withInput(key, scores) .withOutput(key, new IntWritable(93)) .runTest(); } }
4. MR任务调试的入门知识
4.1 关于各种ID
- 之前在学习MR和yarn时,我们知道:
- 用户提交的MR作业,需要通过yarn进行资源分配和任务管理,才能在NodeManager的容器中运行具体的map任务或reduce任务
- 在yarn看来,用户提交的MR作业就是一个Application
- 同时,map任务或reduce任务,由于失败重试或推测执行,会执行不止一次,这叫任务尝试(task attempt)。
- 因此,存在Application ID、job ID、task ID、task attempt ID四种不同的ID
Application ID:
- 由yarn的Resource Maneger负责管理
- 以application开头,中间是Resource Manager的开始时间,后缀是一个增量技术器,从1开始计数
- 一个典型的Application ID:
application_1410450250506_0003,表示这是Resource Manager负责的第3个应用
job ID:
- 将application ID的前缀改成job,得到的就是job ID
- 例如,
application_1410450250506_0003对应的job ID为job_1410450250506_0003
task ID:
- 将job ID的前缀改成
task,并在末尾增加任务类型和任务自增ID - 任务类型,是为了区别MR任务中的map任务和reduce任务,使用
m表示 map任务,r表示reduce任务 - task ID中的任务自增ID从0开始计数,任务自增ID由任务初始化时分配,并不表示任务执行的先后顺序
- 例如,一个map任务的task ID为:
task_1410450250506_0003_m_0002
task attempt ID:
- 将task ID个前缀改成
attempt,并在末尾增加任务尝试ID - 任务尝试ID从0开始计数,其自增顺序就是任务被创建运行的先后顺序
- 例如。一个task attempt ID为:
attempt_1410450250506_0003_m_0002_0
4.2 作业调试
统计异常数据
-
MR作业的结果与预期不同,例如,在统计最高分时,发现最高分超过了科目的满分
-
这时,我们需要统计输入数据中的异常数据
-
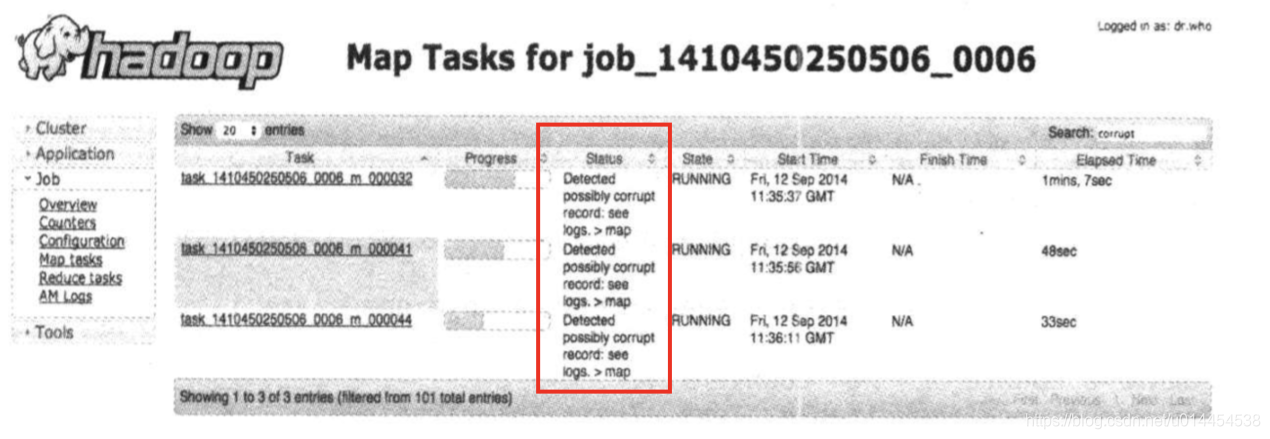
《Hadoop权威指南》介绍了如何在mapper函数中增加调试,通过status传递存在异常数据的信息并统计异常数据数量的方法
// 出现score高于100时 context.setStatus("Detect possibly error score record: See log"); context.getCounter(Score.OVER_100.increment(1)); -
其中,通过status传递的信息,可以在map任务的status字段显示
如何进行远程调试?
- MR任务在集群上执行时,难免会出错,这些错误可能是存在脏数据导致,也可能是JVM内存溢出导致的
- 这些错误,不能在任务执行前就预料到,因此无法提前添加调试信息
- 数据错误: 将出错的数据下载到本地,在本地重新运行以复现问题
- JVM错误: 设置JVM选项,当出现内存溢出时进行堆转储(heap dump)
- 使用任务分析: Hadoop提供了分析作业中部分任务的机制,java的profiler提供了很多JVM细节 —— 自己不懂这部分在说啥 😂
5. 总结
关于Configuration:
- 配置Hadoop的API
- 通过
addResource()添加xml配置文件,通过get()获取属性值(可以为不存在的属性设置默认值)、属性的覆盖(final属性无法被覆盖)
关于开发环境的配置
- Hadoop中HDFS、yarn、MapReduce等的配置,可用配置及描述的查看方式:① 安装包的
share/doc,② 网站的ConfigurationLA栏中查看 - 通过
-conf指定运行时连接的Hadoop集群 - 开发MR程序常用的maven依赖:hadoop-client、用于测试的:junit、mrunit、miniCluster
junit + mrunit对mapper函数和reducer函数进行单元测试
任务调试的基础知识
- application ID、job ID、task ID(从0开始计数)、task attempt ID(从0开始计数)的构建方式
- 如何在mapper中添加调试:context的
setStatus()和getCounter() - 远程调试:本地重现错误、JVM堆转储、任务分析
- 如果通过Resource Manager的web UI,查看/分析作业、任务的运行情况

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)