Spark DataSource V1 & V2 API 一文理解
1. Spark Connector 介绍Spark Connector 是一个 Spark 的数据连接器,可以通过该连接器进行外部数据系统的读写操作。Spark Connector 包含两部分,分别是 Reader 和 Writer。DataSource的API的代码位于spark_sql【如spark-sql_2.11-2.4.4.jar】 模块中的org.apache.spark.sql.s
1. Spark DataSource介绍
Spark DataSource 是一个 Spark 的数据连接器,可以通过该连接器进行外部数据系统的读写操作。Spark DataSource包含两部分,分别是 Reader 和 Writer。
Spark DataSource API 类似于flink 的connector API
DataSource的API的代码位于spark_sql【如spark-sql_2.11-2.4.4.jar】 模块中的org.apache.spark.sql.sources包下,定义了如何从存储系统进行读写的相关 API
API分为v1、v2两个版本,v2的代码位于org.apache.spark.sql.sources.v2包下

Spark 1.3 版本开始引入了 Data Source API V1,通过这个 API 我们可以很方便的读取各种来源的数据,而且 Spark 使用 SQL 组件的一些优化引擎对数据源的读取进行优化,比如列裁剪、过滤下推等等
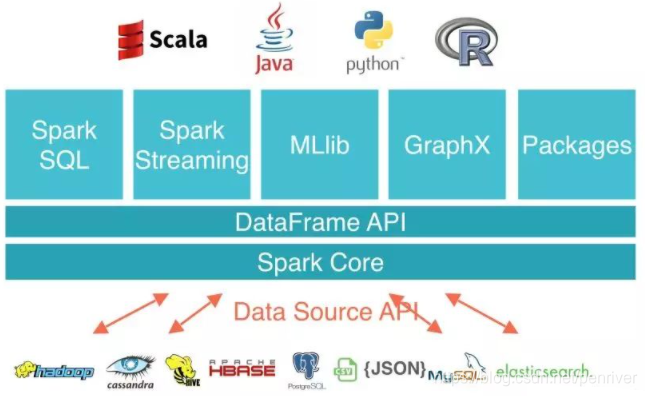
2. Data Source API V1
2.1. 接口定义
Data Source API V1 为我们抽象了一系列的接口,使用这些接口可以实现大部分的场景
接口定义详见类文件:org.apache.spark.sql.sources.interfaces.scala
2.1.1. 基本接口
-
BaseRelation: 表示具有已知 Schema 的元组的集合。所有继承了 BaseRelation 的子类都必须生成 StructType 格式的 Schema。换句话说,BaseRelation 定义了从数据源中读取的数据在 Spark SQL 的 DataFrame 中存储的数据格式。
-
InsertableRelation: 用于插入数据的BaseRelation
-
DataSourceRegister: 注册数据源的简称,在使用数据源时不用写数据源的全限定类名,而只需要写自定义的 shortName 即可。
2.1.2. Provider 接口
-
RelationProvider:从指定数据源中生成自定义的 relation,createRelation 会基于给定的参数生成新的 relation。
-
SchemaRelationProvider:基于给定的参数和给定的 Schema 信息生成新的 relation。
-
CreatableRelationProvider: 用于将DataFrame落地存储
-
StreamSourceProvider:产生一个流式的数据源
-
StreamSinkProvider:产生一个流式的落地sink

2.1.3. scan接口
-
TableScan: 整个表扫描,读取全部数据
-
PrunedScan:在生成RDD之前删除不需要的列
-
PrunedFilteredScan:过滤下推,在生成一个包含所有匹配元组的RDD作为Row对象之前,消除不必要的列并进行过滤下推。
-
CatalystScan:与PrunedFilteredScan,CatalystScan从org.apache.spark.sql.catalyst.plans.logical.LogicalPlan接收原始表达式,并针对query planner进行优化。此接口是实验性的
2.2 优点
常见的读取 JSON、CSV、JDBC、Kafka 以及最近开源的 Detla Lake 等都是通过 Data Source API V1 实现的。这个版本的 Data Source API 有以下几个优点:
-
接口实现非常简单
-
能够满足大部分的使用场景
2.3 不足
但是随着 Spark 的不断发展,以及使用的用户越来越多,这个版本的 Data Source API 开始暴露出一些问题。
1. 部分接口依赖 SQLContext 和 DataFrame
一般而言,Data Source API 应该是比较底层的 API,但是这个版本的 Data Source API 依赖了上层的 API,比如 SQLContext、DataFrame 以及 RDD 等。
在 Spark 2.0 中,SQLContext 已经被遗弃了,逐渐被 SparkSession 替代,同理,DataFrame 也被 Dataset API 取代。但是 Spark 无法更新数据源 API 以反映这些变化。
可以看到高层次的 API 随着时间的推移而发展。较低层次的数据源 API 依赖于高层次的 API 不是一个好主意。
2. 扩展能力有限,难以下推其他算子。
当前数据源 API 仅支持 filter 下推和列修剪(参见上面的 PrunedFilteredScan 接口的 buildScan 方法)。如果我们想添加其他优化, 比如添加 limit优化,那么需要添加其他接口
buildScan(limit)
buildScan(limit, requiredCols)
buildScan(limit, filters)
buildScan(limit, requiredCols, filters)
3. 缺乏对列式存储读取的支持
Spark 数据源仅仅支持以行式的形式读取数据。即使 Spark 内部引擎支持列式数据表示,它也不会暴露给数据源。但是使用列式数据进行分析会有很多性能提升,所以 Spark 完全没必要读取列式数据的时候把其转换成行式,然后再转换成列式进行分析
4. 缺乏分区和排序信息
物理存储信息(例如分区和排序)不会从数据源传递到 Spark 计算引擎,因此不会在 Spark 优化器中使用。这对于像 HBase/Cassandra 这些针对分区访问进行了优化的数据库来说并不友好。在 Data Source V1 API 中,当 Spark 从这些数据源读取数据时,它不会尝试将处理与分区相关联,这将导致性能不佳。
5. 写操作不支持事务
当前的写接口非常通用。它的构建主要是为了支持在 HDFS 等系统中存储数据。但是像数据库这样更复杂的 Sink 需要更多地控制数据写入。例如,当数据部分写入数据库并且作业出现异常时,Spark 数据源接口将不会清理这些行。这个在 HDFS 写文件不存在这个问题,因为写 HDFS 文件时,如果写成功将生成一个名为 _SUCCESS 的文件,但是这种机制在数据库中是不存在的。在这种情况下,会导致数据库里面的数据出现不一致的状态。这种情况通常可以引入事务进行处理,但是 Data Source V1 版本不支持这个功能。
6. 不支持流处理
越来越多的场景需要流式处理,但是 DataSource API V1 不支持这个功能,这导致想 Kafka 这样的数据源不得不调用一些专用的内部 API 或者独自实现。
正是因为 DataSource API V1 的这些缺点和不足,引入 DataSource API V2 势在必行。
3. Data Source API V2
Data Source API V2为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Source API V2,在保留原有的功能之外,还解决了 Data Source API V1 存在的一些问题,比如不再依赖上层 API,扩展能力增强。Data Source API V2 对应的 ISSUE 可以参见 SPARK-15689。
3.1. 接口定义
这些抽象出来的类全部存放在 sql 模块中 core 的 org.apache.spark.sql.sources.v2 包里面,咋一看好像类的数目比之前要多了,但是功能、扩展性却比之前要好很多的。从上面的包目录组织结构可以看出,Data Source API V2 支持读写、流数据写、微批处理读(比如 KafkaSource 就用到这个了)以及 ContinuousRead(continuous stream processing)等多种方式读。在 reader 包里面有 SupportsPushDownFilters、SupportsPushDownRequiredColumns、SupportsReportPartitioning、SupportsReportStatistics 以及 SupportsScanColumnarBatch,分别对应的含义是算子下推、列裁剪、数据分区、统计信息以及批量列扫描等。

3.2. 实现自定义DataSource步骤
1. 实现自定义的reader
- 继承 DataSourceReader并重写 readSchema、planInputPartitions方法,由于 DataSource V2 的优化,可以在这里加上 SupportsPushDownFilters、SupportsPushDownRequiredColumns、SupportsReportPartitioning 等相关的优化
- 继承InputPartition并重写createPartitionReader方法
- 继承InputPartitionReader[InternalRow]并重写next,get方法,实现数据按分区读取
2. 实现自定义的writer
- 继承 DataSourceWriter 重写 createWriterFactory 方法并返回自定义的 DataWriterFactory,重写 commit 方法,用来提交整个事务, 重写 abort 方法,用来做事务回滚。
- 继承 DataWriterFactory, 重写 createDataWriter方法返回自定义的 DataWriter。
- 继承 DataWriter 重写 write 方法,用来将数据写出,重写 commit 方法用来提交事务,重写 abort 方法用来做事务回滚
3. 实现自定义的DataSource
- extends DataSourceV2 with ReadSupport with WriteSupport with DataSourceRegister,并重写createReader、createWriter、shortName方法,创建自定义的数据源

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)