基于深度学习的webshell检测
本科是信息安全,研究生搞机器学习,工作了又开始搞安全,然后有些东西就荒废了。想着要不结合一下练练手吧,于是就有了这篇文章NLP(Natural Language Processing,自然语言处理)是一门融语言学、计算机科学、数学于一体的科学,主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面1、安装参考1、word2vec2、...
本科是信息安全,研究生搞大数据,工作了又开始搞安全,然后有些东西就荒废了。
想着要不结合一下练练手吧,本来想着搞一个大的,但工作后又没有足够的时间,于是就选了个成熟的模型和自己找了些数据试试水。
准确的说这篇文章是基于bert模型的webshell检测,项目地址见github。
背景知识:NLP与深度学习
NLP(Natural Language Processing,自然语言处理)是一门融语言学、计算机科学、数学于一体的科学,主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面
深度学习是可以实现NLP的方法之一,大概讲一下什么是深度学习:
从系统角度出发,一个系统通常有三个部分组成:输入、输出和模型,模型就是输入和输出之间的映射关系。
比如一个系统的输入是 x ,输出为 y ,我们知道 x=1, y=2; x=2, y=4,以此类推。我们很容易就得出 x 与 y 之间的映射关系,即 y 是两倍的 x ( y=2x )。

这里的两倍,就是输入和输出之间的映射关系。当我们知道了这种映射关系之后,我随便给出一个输入 x ,都能得到输出 y
这时候就很明确了,从输入推理出输出的关键就在于,获取输入和输出之间的映射关系,我们将输入和输出之间的映射关系定义成一个函数 Y = F(X, j) ,这里的 X 就是输出, Y 是输入,j 是参数。
关键就在于,怎么求解这个 F 呢?这时候就要祭出神经网络了,它的作用就是通过调整参数 j 来求解输入输出之间的映射关系 F 。
从理论上来讲,神经网络通过调整各层的参数 j ,可以拟合任意复杂度的函数。我们先喂给神经网络一定量的输入输出数据,通过一次次的训练,让网络学习到当前输入输出数据之间的映射关系。那么如果未知的输入 X 与训练神经网络的输入服从同分布的话,将这个未知输入 X 送入神经网络中就能够映射出一个输出 Y 。
可是这种映射的结果一定是准确的吗,比如我输入一张猫咪的图像进入识别动物的神经网络,我想要的输出结果是:这是一只猫咪。但神经网络给出的输出有可能是:这是一只狗狗。
这意味着,神经网络学习到的输入和输出之间的映射关系,不一定是准确的!
那么什么样的神经网络能够更加准确的学习到输入和输出之间的映射关系呢?答案是更深的神经网络。
原来把网络层数加深就好了,当然也不是越深越好,涉及到过拟合问题,或者跟训练的数据集、激活函数等都有关系
可是神经网络采取下图这种全连接的连接方式,即每层中的任意个神经元都与下一层的全部神经元相连接,然后每个连接之间都有一组参数 J :
X11 = J1*X1 + J2*X2 J3*X3 + 1
J = [J1, J2, J3, 1]

这种全连接形式带来的参数量是极其巨大的,导致的计算量是不可接受的。
参数量巨大只是其中的一个问题,还有一个问题是,过于深的神经网络在求解过程中很容易陷入局部最优解,而非全局最优解。这成为了阻碍深度神经网络发展的主要因素。
直到2006年,深度学习界的大牛,Hinton教授发表的论文中提出了两个重要观点:(1)多层的神经网络具有优秀的特征学习能力,能够学习到数据更本质的特征;(2)可通过逐层预训练的方式解决深度神经网络难以获得全局最优解的问题。
随着深度学习的继续发展,受到猫脑视觉皮层研究中局部感受野的启发,卷积神经网络(Convolutional Neural Network,CNN),通过稀疏连接、参数共享两个思想改进了深度神经网络。左边是CNN结构,右边是全连接形式的神经网络。

还有深度波尔茨曼机Deep Boltzmann Machine(DBM),假设有一个二部图,每一层的节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。

当然,模型还有很多,不再一一介绍。
环境安装
1、安装anaconda,教程很多,不再介绍,安装完成后打开它

2、在anaconda prompt中输入如下命令:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
conda create -n tensorflow python=3.6
3、进入tensorflow环境,我是很久以前安装的,所以是python3.5,现在3.6也很好兼容了
4、安装CPU版本的TensorFlow(安全人员要什么GPU,那是用来挖矿的东西,碰不得),命令如下:
pip install --upgrade --ignore-installed tensorflow==1.14.0
5、举个例子试试,栗子如下,告警请忽略
>>> import warnings
>>> warnings.filterwarnings("ignore")
>>> import tensorflow as tf
>>> hello_t = tf.constant('hello tensorflow')
>>> session = tf.Session()
>>> print(session.run(hello_t))

conda相关命令
conda info -e #显示所有已经创建的环境
source activate env_name #切换至env_name环境, Windows:activate env_name
source deactivate #退出环境,Windows: deactivate
conda --version #查看conda版本,验证是否安装
conda remove --name env_name –all #删除环境
conda list #查看所有已经安装的包
conda create -n env_name package_name #创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号,例如:conda create -n python2 python=python2.7 numpy pandas,创建了python2环境,python版本为2.7,同时还安装了numpy pandas包
使用模型
这里使用google的bert,2018年的10月11日,Google发布的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》,成功在 11 项 NLP 任务中取得 state of the art 的结果声。

优点:
Bert的基础建立在transformer之上,拥有强大的语言表征能力和特征提取能力。在11项 NLP基准测试任务中达到了state of the art。同时再次证明了双向语言模型的能力更加强大。
缺点:
1)可复现性差,基本没法做,只能拿来主义直接用,不过这正是我们这种没时间瞎调的优势
2)训练过程中因为每个batch_size中的数据只有15%参与预测,模型收敛较慢,需要强大的算力支撑
下载地址:https://github.com/google-research/bert
这里使用的预训练模型是:https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
使用数据
下面是我收集的一些白名单(正常业务代码),黑名单(webshell代码):
链接:https://pan.baidu.com/s/1PguiOAy7kh-afX7Tc1VglA
提取码:5wim
我对训练数据做了一些粗略的预处理,比如去除了回车、注释,将多个连续符号替换成逗号等。因为bert是对文本进行分类,连续多个符号对训练并无太大意义,还会影响效率。
数据清洗是深度学习预测准确率的决定性要素之一,这边由于时间不多,也比较懒,只是简单地做了一些处理。
训练与预测
项目地址见github,目前也比较粗略,只是能跑起来,后面有时间改改。
首先下载预训练参数模型,然后放到对应目录

简单且不严谨地解释一下:
因为我们的训练模型有很多参数,需要赋一个初始值,这玩意的主要作用就是给我们的初始模型进行参数赋值,因为预训练模型也是通过其他数据训练出来的,语言有一定的相通性,会比你一顿瞎赋效果好很多。在我们训练数据比较少的时候,预训练模型是很有用的,相当于它帮你训练好了一部分东西。就好比:原来一个孩子你要从婴儿开始带到大,现在别人帮你把你的孩子抚养到10岁,然后再还给你继续带。。。。额。。。这比喻。。。绝了
当然,训练其实也是一个复杂的过程,涉及到训练、验证数据、黑白数据等的比例,参数的优化,层数的优化、激活函数的选择等等,有需要的读者需要自己找相关资料了解。
不想了解的只要会用就行:
然后开始训练,忽略下面那些警告
python train_eval.py

然后预测:
python predict.py
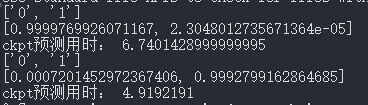
这里总共预测了两个代码。
第一个数组中0代表正常代码,1代表webshell代码
第二个数组中两个小数分别表示预测为0和1的概率
参考
1、word2vec
2、https://blog.csdn.net/weixin_41765699/article/details/81873076
3、https://www.zhihu.com/question/24097648/answer/1155390509
4、https://github.com/yaleimeng/TextClassify_with_BERT
5、https://zhuanlan.zhihu.com/p/51413773

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)