
【知识图谱】哈工大ltp工具包的安装和使用
LTP(Language Technology Platform) 提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。官方教程:https://github.com/HIT-SCIR/ltp/blob/master/docs/quickstart.rst官方文档:http://ltp.ai/docs/appendix.html安装与pyltp不
LTP(Language Technology Platform) 提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。
官方教程:https://github.com/HIT-SCIR/ltp/blob/master/docs/quickstart.rst
官方文档:http://ltp.ai/docs/appendix.html
安装
与pyltp不同,ltp4无需安装繁琐的vc环境,也不用考虑python版本对轮子兼容的问题。
pip install ltp
在github源代码中可以发现作者主要使用了Electra预训练模型,并使用了transformers库调用模型。所以在安装pyltp之前我们要确保本机上安装的库与ltp中使用的库版本一致,当然如果本机环境并没有安装相应库,安装ltp时会自动安装。
- torch>=1.2.0
- transformers>=4.0.0, <5.0
- pygtrie>=2.3.0, <2.5
下载预训练模型参数
模型下载地址:https://github.com/HIT-SCIR/ltp/blob/master/MODELS.md
在使用ltp时需要选择适合任务大小的模型,将下载下来的压缩文件解压放入文件夹中即可
ltp的使用
加载模型
ltp = LTP(path='pretrained_model') # 默认加载 Small 模型
path中填入模型参数放入的文件夹
分句
sents = ltp.sent_split(["该僵尸网络包含至少35000个被破坏的Windows系统,攻击者和使用者正在秘密使用这些系统来开采Monero加密货币。该僵尸网络名为“ VictoryGate”,自2019年5月以来一直活跃。"])
print('分句:')
for sent in sents:
print(sent)
分词
sent =[sents[0]]
print('分词:')
seg, hidden = ltp.seg(sent)
print(seg[0])
词性标注
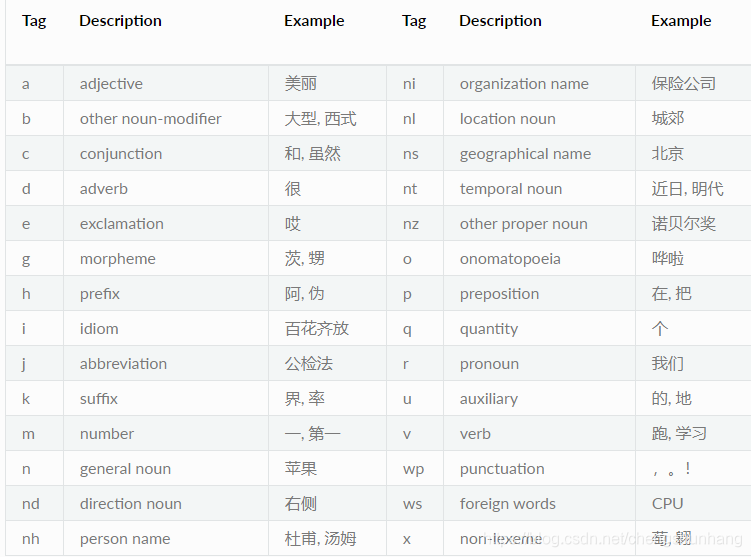
print('词性标注:')
pos = ltp.pos(hidden)
print(pos[0])
语义角色标注

print('语义角色标注:')
srl = ltp.srl(hidden, keep_empty=False)
print(srl[0])
句法分析
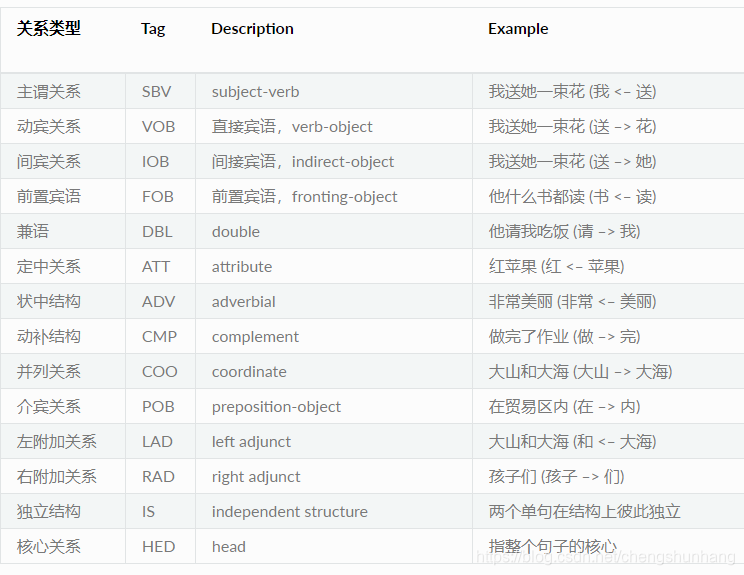
print('句法分析:')
dep = ltp.dep(hidden)
print(dep[0])

使用语义角色标注构造关系抽取
通过语义角色标注任务可以将句子中各实体以及其关系表示出来,我们以主谓宾关系为例,构建一个(主,谓,宾)的三元组:
def srl_AtoA(sent):
seg, hidden = ltp.seg([sent])
seg = seg[0]
srl = ltp.srl(hidden, keep_empty=False)[0]
results = []
for s in srl:
key = s[0]
values = s[1]
result_A0 = ''
result_A1 = ''
for value in values:
if value[0] == 'A0':
result_A0 = ''.join(seg[value[1]:value[2]+1])
if value[0] == 'A1':
result_A1 = ''.join(seg[value[1]:value[2]+1])
if result_A0 != '' and result_A1 != '':
results.append((result_A0,seg[key],result_A1))
print(results)

通过词性和语义角色标注构建的三元组可以大致获取到实体与实体之间的联系,但是在实际的任务中我们需要结合需求构造相应的实体与相应的关系(例如在医疗系统中,我们的实体不再是名词这么简单,可能包括药物名称,症状等等,这些需要我们通过命名实体识别构建特定的实体集。)
通过最后获取的三元组我们便可以轻松的完成知识图谱了。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)