
win10下通过nvidia-smi查看GPU使用情况
1. 查看NVIDIA的GPU基本情况可以直接在任务管理器里看一下这个信息,我本机的GPU型号是:NVIDIA GeForce GTX 1650Cuda版本是cuda_11.0,可以在命令行输入:nvcc --version2. 查看使用情况参考:windows10下nvidia-smi查看GPU占用率网上大部分都说:nvidia-smi.exe这个软件的位置是在:C:\Program Files
1. 查看NVIDIA的GPU基本情况
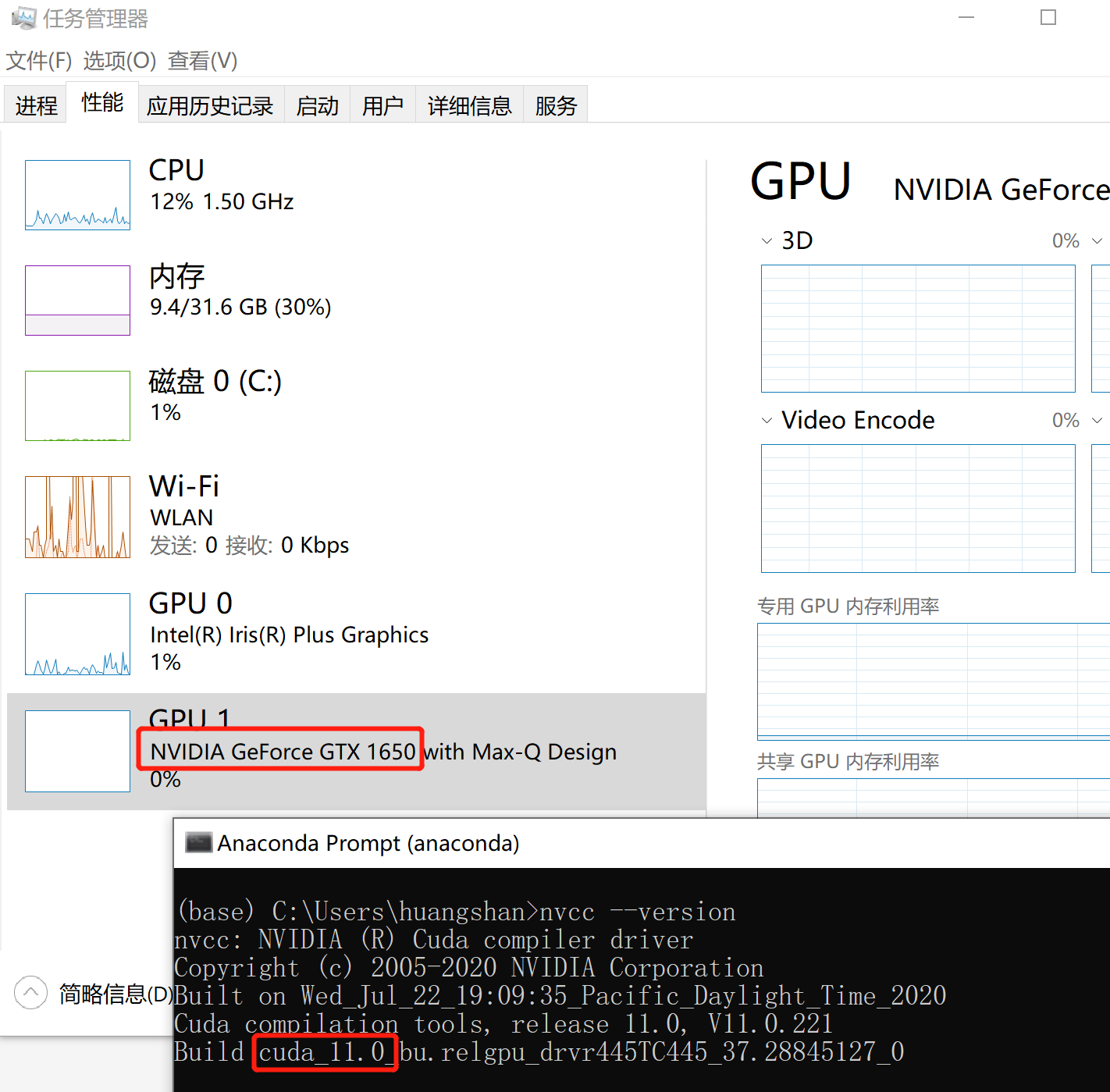
可以直接在任务管理器里看一下这个信息,
我本机的GPU型号是:NVIDIA GeForce GTX 1650
Cuda版本是cuda_11.0,可以在命令行输入:
nvcc --version
2. 查看使用情况
参考:windows10下nvidia-smi查看GPU占用率
网上大部分都说:
nvidia-smi.exe这个软件的位置是在:C:\Program Files\NVIDIA Corporation\NVSMI
但是真的不好意思,我这个最新版的cuda11.0是真的找不到
参考StackOverflow的回答:How do I run nvidia-smi on Windows?
可以知道,
老版本的cuda,nvidia-sim.exe这个软件是位于:C:\Program Files\NVIDIA Corporation\NVSMI
新版本的cuda(比如cuda11.0),nvidia-sim.exe这个软件是位于:C:\Windows\System32\DriverStore\FileRepository\nvdm*\nvidia-smi.exe 这里nvdm*表示的是以nvdm开头,后面可能是一串奇怪字符串的目录,类似:
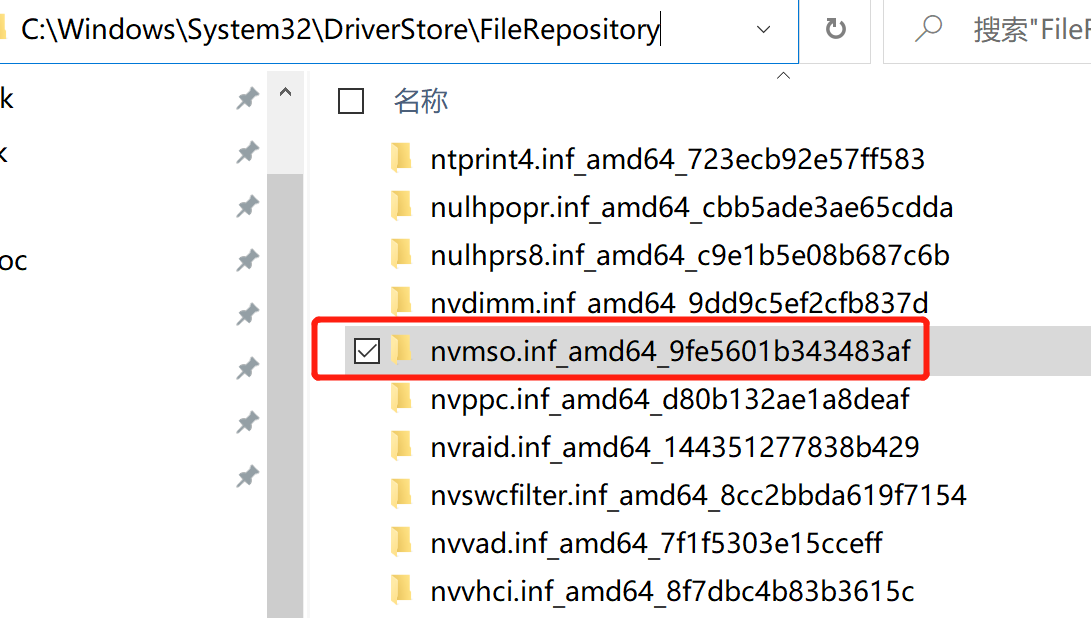
在我的电脑上,并不是nvdm开头的,而是nvmso开头的,可以自己多找找,反正肯定是nv开头的,点进去,就可以看到
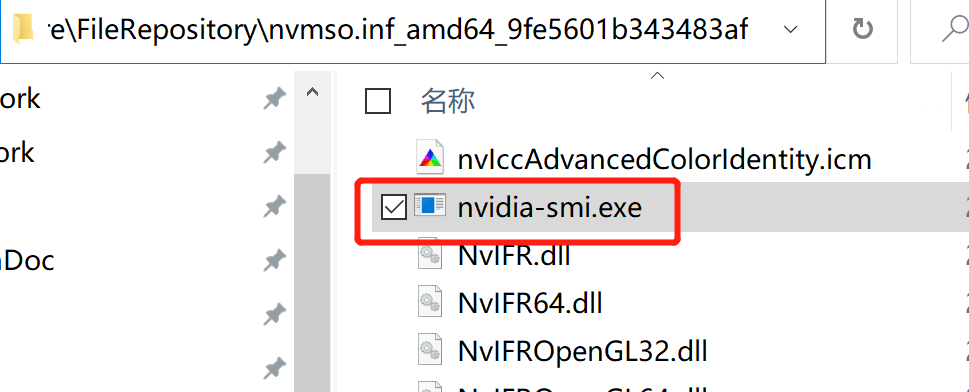
这个路径确实是不太好找,如果对这个工具需求很大,要经常使用的话,可以考虑加入系统路径,这样就可以直接打开命令行,在任意目录下运行了,不然还需要切换到相应目录,类似:
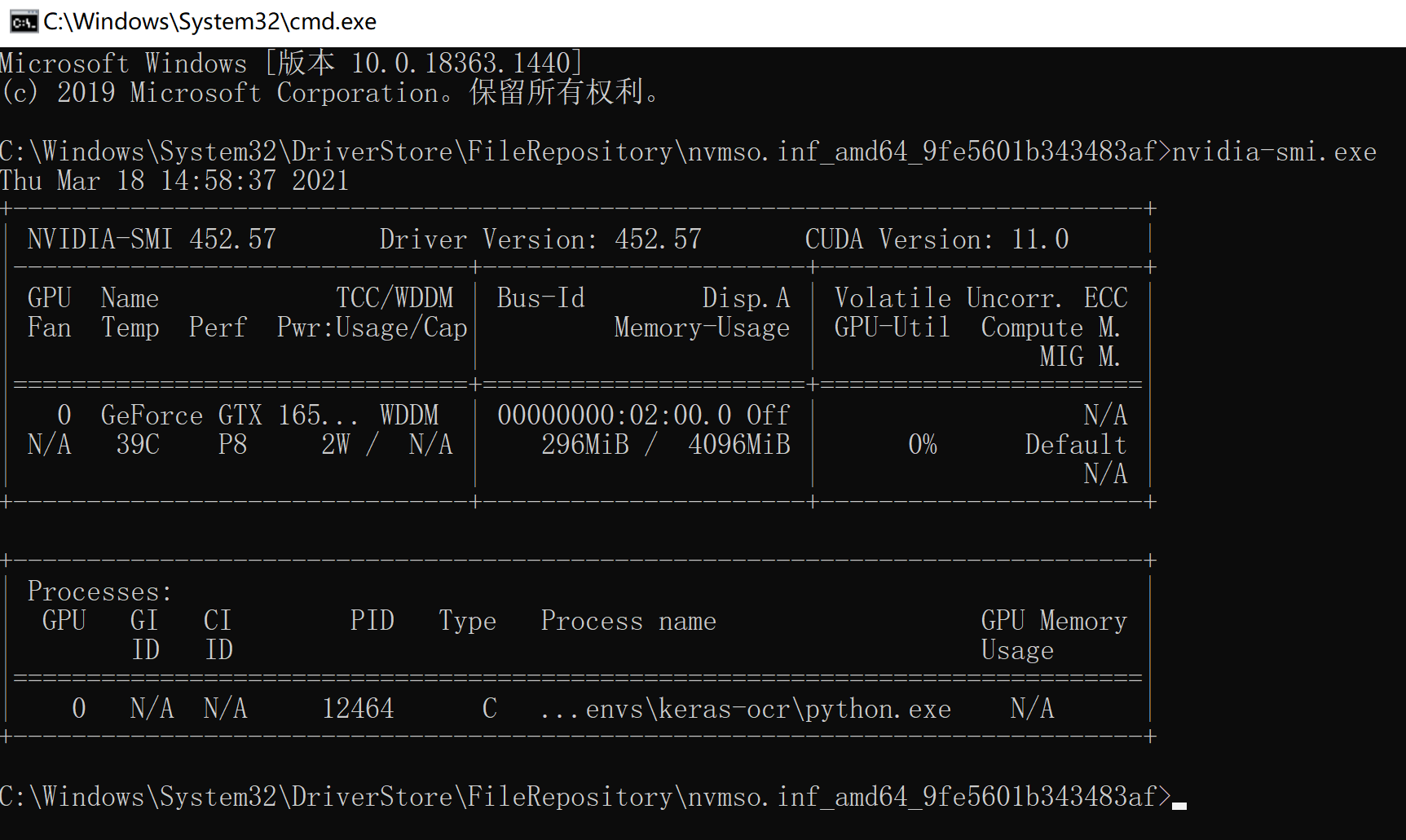 其实这个界面和linux上的还是有点相像的。
其实这个界面和linux上的还是有点相像的。
需要注意的是,最下面的Processes可以看到,有哪些程序在使用GPU。
3. 如何判断tensorflow是否调用了GPU
以jupyter notebook为例,在cell中输入import tensorflow,可以在命令行窗口中看到类似:
2021-03-18 15:03:48.734586: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406]
Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 2905 MB memory) ->
physical GPU (device: 0, name: GeForce GTX 1650 with Max-Q Design,
pci bus id: 0000:02:00.0,
compute capability: 7.5)
2021-03-18 15:31:38.439330: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties: pciBusID: 0000:02:00.0 name: GeForce GTX 1650 with Max-Q Design computeCapability: 7.5 coreClock: 1.245GHz coreCount: 16 deviceMemorySize: 4.00GiB deviceMemoryBandwidth: 104.34GiB/s
2021-03-18 15:31:38.460670: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudart64_110.dll
2021-03-18 15:31:38.473146: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublas64_11.dll
2021-03-18 15:31:38.476667: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cublasLt64_11.dll
2021-03-18 15:31:38.479930: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cufft64_10.dll
2021-03-18 15:31:38.483906: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library curand64_10.dll
2021-03-18 15:31:38.487289: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusolver64_10.dll
2021-03-18 15:31:38.490363: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusparse64_11.dll
2021-03-18 15:31:38.499306: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll
2021-03-18 15:31:38.502696: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
这个信息和刚刚在任务管理器看到的GPU是一样的,就是序号变了,一个是0,一个是1
任务管理器中的GPU
另外,关于指定特定GPU以及分配GPU使用的相关命令,可以参考:
Tensorflow在训练模型的时候如何指定GPU进行训练
命令有非常多,比如:指定用哪几个GPU
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 使用第1块GPU(从0开始)
比如:查看现在有哪些硬件可以用
assert tf.test.is_gpu_available()
# assert这个用法要被丢弃了,建议使用下面的这条
tf.config.list_physical_devices('GPU')
> [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
# 或者更快一点,可以
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
cpus = tf.config.experimental.list_physical_devices(device_type='CPU')
print(gpus, cpus)
> [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
> [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')]
# 还有一种最好用的
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
# 返回以下结果
>[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 3509448467948921213
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 3046532710
locality {
bus_id: 1
links {
}
}
incarnation: 8668762526493502295
physical_device_desc: "device: 0, name: GeForce GTX 1650 with Max-Q Design, pci bus id: 0000:02:00.0, compute capability: 7.5"
]
4. 报错 OOM错误
完整的错误信息如下,
ResourceExhaustedError: OOM when allocating tensor with shape[6,64,1536,2048]
and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[node model_22/basenet.slice1.0/Conv2D (defined at
C:\software\anaconda\envs\keras-ocr\lib\site-packages\keras_ocr\detection.py:682)
]]
根据网上搜索的结果,一般出现这个问题就是因为显存不够,虽然只有2G,但是不至于连个OCR都跑不出来吧。
而且我之前跑出来过,参考网上StackOverflow的问答:Tensorflow not running on GPU
有可能是之前跑的一些程序内容还停留在显存中,最简单的一种清理显存的方式就是:
- 关机重启,先试试。
- 另外可以设置动态分配显存
- 参考:tensorflow gpu 显存不足错误
- 对于tensorflow2.0版本,代码应写为:
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0" config = tf.compat.v1.GPUOptions # 设置最大占有GPU不超过显存的70% config.per_process_gpu_memory_fraction = 0.7 # 重点:设置动态分配GPU config.allow_growth = True- 如果是TensorFlow1.0版本,就应该是:
#指定使用那块GUP训练 os.environ[“CUDA_VISIBLE_DEVICES”] = ‘0’ config = tf.ConfigProto() # 设置最大占有GPU不超过显存的70% config.gpu_options.per_process_gpu_memory_fraction = 0.7 # 重点:设置动态分配GPU config.gpu_options.allow_growth = True - 最后,一般CPU比GPU大,如果安装的是tensorflow-gpu版本,可以考虑禁用gpu,直接用cpu
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 6
6 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)