CSDN学习社区
计算机视觉知识点整理(中) 模型篇(持续更新) 计算机视觉知识点整理(中) 模型篇(持续更新)
前言我在学习过程中,经常反复记忆各种网络的创新点是什么。这次我复习的时候决定把里面的关键创新点、容易疏忽的点都记录下来,方便快速查找回顾。记忆表网络名称记忆点备注MobileNetV1深度可分离卷积替换传统卷积计算量和参数量下降为原来的1/Dk^2(Dk为卷积核kernel size,一般为3,所以计算量约为1/9)深度卷积的激活函数是Relu6下采样是通过3x3的深度卷积stride=2Mobi
 吸欧大王 · 2021-03-04 11:38:54 发布
吸欧大王 · 2021-03-04 11:38:54 发布 前言
最近在面试,每天会被考到很多知识点,这些知识点有些我已经看了十几遍,还是会反应慢或者记不住。回想我在学习过程中,也是学了忘忘了学,没有重复个几十遍根本难以形成永久记忆。这次我复习和整理面试知识点的时候决定把CNN里面的关键创新点、容易疏忽的点都记录下来,方便快速查找回顾,于是就有了这篇像词典一样的永久更新的文章。
因为知识点过多,导致文章过长,目前已拆分为三篇:
1.基础知识篇
2.轻量化网络篇
3.通用模型篇
一.常见目标检测网络
1.FasterRCNN (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| Faster-RCNN | 网络结构图 |  |
| anchor是怎样放置的? |
- 首先按照3种不同的尺度和3种不同的宽高比生成9个anchor,坐标排列是以原点为中心的左上右下相对量。
- 生成和feature map的w,h一样的gird网格,得到每个网格点的中心坐标。
- 把9个anchor分别加到网格点中心坐标上,因此得到了所有anchor位置的坐标。
|
| Extractor和Classifier是如何划分的? | 以resnet50作为backbone为例,stage3及之前的module为extractor,负责生成基础的feature map,而stage4和avgpool(7)作为classifier对ROI进行最后的预测。 |
| 描述RPN网络? |
- feature map经过一个3x3的卷积后进行relu激活,然后送入两个1x1卷积。假设anchor数量为9,那么一个调整channel为9x2,代表着anchor内有无物体的概率;一个代表着rpn对anchor的坐标调整,生成建议框。
- 完成两个1x1卷积后,分别得到score和location预测值。对结果进行reshape,变为[B,A,2]和[B,A,4],其中B是batchsize,A是全部的anchor位置。对score进行softmax,取出包含前景的一层,shape为[B,A],对location进行anchor坐标调整。
|
| RPN如何调整anchor坐标生成ROI? |
- rpn的train和test阶段,对于anchor的坐标调整并生成region proposal的过程只有nms前后两个阈值有区别。
- 首先调整是按照BatchSize的维度逐个图像循环进行的,其次每次迭代针对全部的anchor位置的,最后调整是基于原图尺寸的未经过任何放缩。
- x,y坐标调整是针对anchor中心点的,调整的量是相对于anchor的宽高的;w,h是相对与anchor宽高的,调整量通过指数函数乘到anchor的宽高上。如下图:
 - rpn对所有的anchor位置进行坐标调整之后,有M(50*50*9=22500)个,并且是用原图上的绝对坐标表示的。
- 针对是否超出了原图边界进行裁剪。
- 过滤掉宽或高小于阈值(默认16)的框。剩下M1个框。
- 按照置信度score,来对框进行排序,取出阈值n_pre_nms个(默认train的时候12000,test的时候3000)。
- 对上面得到的n_pre_nms个框,执行NMS。
- 得到结果后,取出阈值n_post_nms个(默认train的时候600,test的时候300),这些就是所谓的ROI了。
- 最后把按照B的维度循环迭代的每张图片的ROI合并起来。得到的是B*600(train)/ B*300(test)个ROI。并且还标记了这些ROI对应的batch index。
|
| stage1:RPN阶段的loss如何计算的? |
- 首先明确stage1阶段的样本划分、loss计算都和ROI没有任何关系,这里不要搞混了。
- 对feature map的所有anchor位置,分别与GT的所有框进行iou计算,iou>0.7被标记为正样本(表示为1),iou小于0.3被标记为负样本(表示为0)。其余被标记为忽略样本(表示为-1)。
- 在所有正样本中抽样128个,其余正样本重新标定为忽略样本。如果正样本>128,则对负样本抽样128个,其余标记为忽略样本。如果正样本<128,则batchsize-正样本个数的部分均用负样本填充。所以每张图实际上产生256个样本。
- rpn的loss分为两部分,一个是2分类的损失,计算的是刚刚得到的256个正负样本。另一部分是location的回归,这里同样需要求出gt相对于anchor的坐标偏移量,再与rpn的location输出进行回归损失。这里需要注意两个点:一是只计算标记为正样本的anchor位置,二是损失使用的是smooth L1 loss。
|
| stage2:classifier阶段的loss如何计算的? |
- 首先rpn的输出是每张图默认600个roi。
- 这些roi要进一步的抽样,同样与gt进行iou计算获取最大的iou与对应的gt,iou>0.5的标记为正样本,iou<0.5的标记为负样本。正样本采样64个,负样本采样64个(正样本不够负样本来补),整体凑128个样本。
- 在feature map上roi pooling到相同的尺寸。
- 送入分类网络,得到n_classes+1个类得分,和4*(n_classes+1)个坐标。
- loss仍然是分类用交叉熵,位置回归是smooth L1 loss。
|
| ROI pooling的两次量化精度丢失?以及ROI align的改进? | ROI Pooling ROI放缩到feature map上,按照输出的shape通过两次量化将ROI切分成不同版块,每个版块内做max pooling。 两次量化:
- 第一次是ROI放缩到feature map上,如果无法整除,要向下取整。
- 第二次是ROI放缩到feature map之后,还要根据输出规定的形状去划分为整格点的版块,这里无法整分也只能近似的取整。

ROI Align
- 将bbox区域按输出要求的size进行等分,很可能等分后各顶点落不到真实的像素点上
- 没关系,在每个bin中再取固定的4个点(作者实验后发现取4效果较好),也就是图二右侧的蓝色点
- 针对每一个蓝点,距离它最近的4个真实像素点的值加权(双线性插值),求得这个蓝点的值
- 一个bin内会算出4个新值,在这些新值中取max,作为这个bin的输出值
- 最后就能得到2x2的输出

|
2.CascadeRCNN (重要度★★★)
3.Mask-RCNN (重要度★★★★)
4.YoloV3 (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| | 模型结构示意图 | 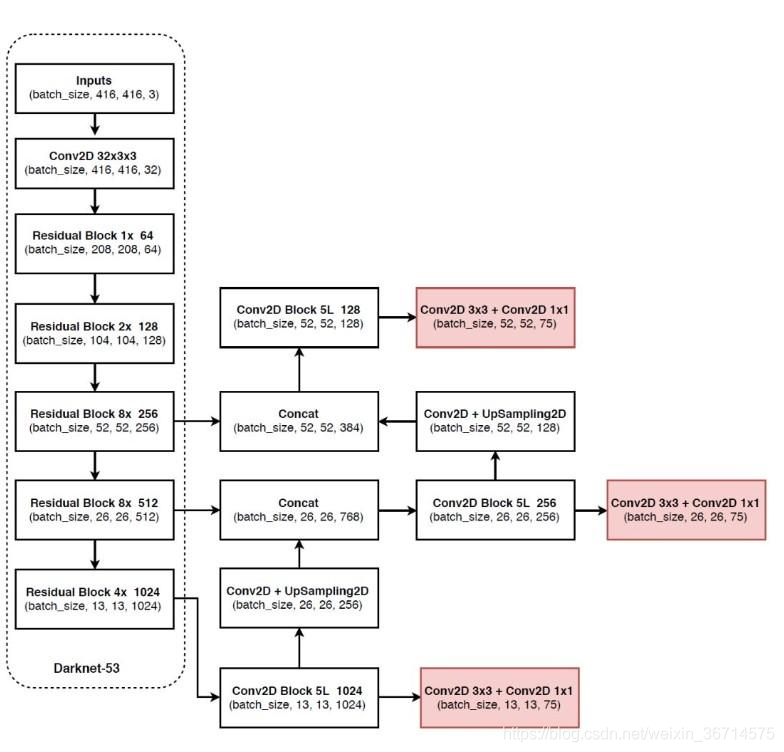 |
| YoloV3 | 快速列举YoloV3模型的特点? |
- backbone默认是darknet53,5个stage分别重复[1, 2, 8, 8, 4]次,每个stage下采样2倍,最大32倍下采样。
- 每个stage开始先用3x3 stride2 CBL 下采样同时增大通道数 。
- 有点特色的bottleneck结构: 1x1 CBL 通道数减为一半 + 3x3 CBL 通道数恢复 。
- FPN结构,3个head都是3x3 + 1x1
|
| 前景背景如何判定的? |
- 分三个尺度,每次放置3个anchor。
- 对于每个GT,由它中心左上角(实际上向下取整)所在的格点负责预测。GT与该点的3个anchor计算IOU,最大的anchor位置标记为正样本。其余位置标记为负样本。
- 负样本中,如果置信度高于阈值,则从负样本里去掉。所以部分anchor位置被忽略。
|
| loss计算 | loss_x = self.mse_loss(x[obj_mask], tx[obj_mask])
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
|
5.YoloV4(重要度★★★★)
6.YoloV5 (重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| YoloV5 | 快速列举YoloV5模型上的创新点? |
- Focus:Slice切片叠加,是一种col-major space2depth操作。
- 两种CSP,残差/非残差。残差用在较深的backbone里,增加反向传播梯度,避免梯度消失。
- SPP:多尺度的特征融合。
- PAN:FPN传导高层语义到低层,PAN再传到底层定位信息到高层,使多个尺度上的语义信息和定位信息都增强。
- nn.Silu()激活函数:f(x)=x⋅σ(x) f′(x)=f(x)+σ(x)(1−f(x)) 计算友好

|
| | |
7.CornerNet (重要度★★★)
| 模型名称 | 记忆点 | 备注 |
| CornerNet | Anchor-Based目标检测算法有哪些问题? |
- AnchorBoxes的数量非常大,动辄就上万个几万个,增大了计算量。
- 只有一小部分能和GT重合,这就带来了严重的正负样本不均衡的问题,依赖于手动设计阈值区分正负样本。
- 引入了很多复杂的参数设计,比如Anchor的宽高比、大小、数量,使用时难以调整。
- 参数难以泛化,因为不同数据集的大小形状分布不同。
|
| 核心思路 | 把一个目标的识别看成一对关键点的检测(左上和右下)。具体来说,模型使用单个卷积神经网络来预测同一个物体类别的所有实例的左上角的热力图和右下角的热力图以及每个检测到的角点的嵌入向量。嵌入向量用于对同一目标的一对角点进行分组。本方法无需设计anchor boxes,极大简化了网络的输出。
|
| Corner Pooling | Corner Pooling可以更好的定位边框的角点。对每个channel,从右向左,从下向上找到最大值再求和,作为该点的值。 |
| backbone使用Hourglass | 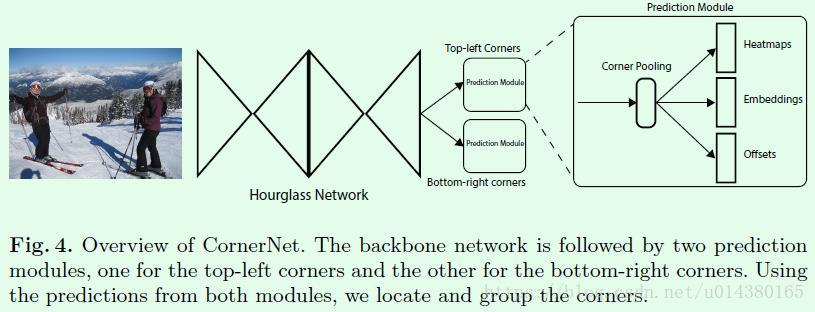 |
8.CenterNet 【论文:Object as points】 (重要度★★★★★)
| 模型名称 | 记忆点 | 备注 |
| CenterNet | 思路 | 之前的网络大部分是直接回归出中心点坐标和宽高,centernet的思路是求出概率图,然后根据概率选择中心点。 |
| CenterNet的优势/亮点 |
- 比two stage的代表FasterRCNN更快,且精度更高。
- 只检测中心点和宽高。
- 可扩展性极强,可以加入目标检测、姿态估计、3D目标检测等多个检测头达到多重功能。
- 不需要后处理(比如NMS)。
|
| 架构简图 | 

- 分为3个branch,Center Heatmap、Offset、Size。
- 注意Link是统一的结构。
|
| BackBone |  |
| Link | Link的作用是匹配后面检测头的channel数值。 
|
| Center HeatMap | Shape是【128, 128, C】,C代表着预测类别的数量。每一层代表着一类的物体,数值代表着该类物体中心点的概率,所以整体是概率图的模式。 |
| Offset | Shape是【128, 128, 2】,2个维度分别代表中心点误差δx和δy。预测出因为量化导致的中心点误差。原始图像是512/512,而center heatmap是128/128,这就会产生类似ROI pooling的量化,这种量化是尤其伤害小目标的预测的。为了弥补这个误差,因此需要预测出误差。 
预测和真实值间的差距要和offset做L1 loss,使offset能够预测量化带来的误差。 |
| Size | Shape是【128,128,2】,预测物体的宽高。 |
| Other Heads | 这里充分说明了CenterNet的可扩展性,因为每个head都负责不同的功能,所以可以加入关键点检测等更多的功能,只需要设计对应的head即可。 还可以先训练某个branch,然后固定后再训练其他的branch,非常灵活。 |
| 正负样本的划分 | 
如图我们对于GT的真实中心放缩到grid mask上,对应的点标记为正样本;同时周围一圈的的点也会通过高斯分布给与标签数值,这些都会认为是正样本点,这样就避免了只预测一个点的难度过大。 |
| Loss的设计 | 中心点loss: 
offset loss: 
size loss: 
total loss: 
|
| 如何inference? | 
默认未使用NMS,而是使用3x3的max pooling找到8-邻域最大值,然后得到100个峰值。 |
9.FCOS (重要度★★★)
10.EfficientDet (重要度★★★★)
| 模型名称 | 记忆点 | 备注 |
| EfficientDet | 设计理念 |
- 构建更好的backbone,用于提取更优秀的特征。
- 构建更好的特征融合模块,来实现对多尺度的预测精度。
- 构建一组不同的网络宽度、深度和分辨率来实现不同目标检测任务的适配。
|
| 架构图 |  |
| BackBone(EfficientNet) | Backbone使用了EfficietNet,通过复合缩放策略平衡模型的深度、宽度和分辨率。
- 调整图像的输入大小 【分辨率翻倍,计算量变为原来4倍】
- 调整网络的深度(卷积层数)【卷积核数翻倍,计算量变为原来2倍】
- 调整网络的宽度(通道数或者是类似Inception的思路并联分支)【通道数翻倍,计算量变为原来4倍】

- 是设计一个标准化的卷积网络的扩展方法。
- 既可以实现较高的准确率,又可以充分的节约算力资源。
最终使用了Compound Scaling的缩放策略,比单一调整分辨率和深度、宽度的效果更好,具体如上图。最后得到的compound 参数见下图: 
baseline是用mobileNetV2 + SE 用NAS搜索出来的结构,然后再上面进行缩放。 α、β、γ都是网格搜索出来的基数,Φ是人工调节的,比如计算量扩大十倍,Φ=3.32。


|
| BiFPN | 
- 图a是原始的FPN,P3-P7表示从低阶特征到高阶特征的5个stage,可以看到原始的FPN只有从高阶特征到低阶特征的单方向融合(top-down),那么对于高阶特征的输出,其实是没有获得低阶的细节特征信息的。
- 图b是PANet中的双向(top-down & bottom-up)FPN,这样就让高阶特征输出中也有了低阶细节特征信息,使得特征提取更有效,不过双向融合相应的也带来了更大的计算量。
- 图c是NAS-FPN,顾名思义是用NAS搜索出来的FPN网络,网络结构让人看得摸不着头脑,而且针对特定任务搜出来的网络,泛化能力也不一定好。不过可以注意到其中有很多跳级的连接(cross-scale connections)。
- 图d就是EfficientDet提出来的BiFPN,它其实是图b和图c的融合,去糟取精。他去掉了图b中的一些不必要的连接,减少计算量,保持了图b中的双向融合;去掉了图c中没有章法的连接,保留了跳级连接。BiFPN有两个特点一个是feature map之间的融合是加权且可训练的,另外一个是BiFPN是可重复叠加的。
|
二.常见OCR模型
OCR经典网络
| 模型名称 | 记忆点 | 备注 |
| CRNN(2015) | 优势 |
- 支持端到端的训练,特征提取(CNN)、识别(LSTM)、解码(CTC)于一体。
- 十分轻量,只有8M,适用于工业落地。
|
| | |
| Attention-OCR | | |
| DBNet | | |
三.常见人脸识别模型
| 模型名称 | 记忆点 | 备注 |
| 人脸识别的流程 | 人脸识别的流程 | 
- 人脸检测:在图像中找到人脸的位置。
- 人脸对齐:人脸配准在人脸中找到眼睛、鼻子、嘴巴等面部器官的位置。
- 人脸特征提取:通过人脸特征提取将人脸图像信息抽象为embedding信息。
- 人脸识别:将目标人脸与既有人脸比对计算相似度,确认人脸身份。
|
| MTCNN(2015) | 使用了Region Proposal的思路 |
- Pnet:Proposal Net
- Rnet:Refine Net
- Onet:Output Net
|
| | |
| LightCNN(2017) 【人脸识别】 | 不使用Relu的原因 | 主要是为了加速,减少计算量。 |
| MFM(Max Feature Map) | 
将feature map分为两组,然后对应的特征图逐像素取最大值。实现通道减半的功能。Max函数本身也能提供非线性的能力。 |
| Semantic BootStrapping for Noisy Labels | 实际上就是Presedo labeling的思路。 另外有论文研究表明,label有一点noise在数学上可以等同于图像有一点noise,所以算是一种data augmentation方法。 |
| Dlib-alignment | | |
| FaceBoxes(2018) 【人脸检测】 | 优势 | RealTime on CPU, 100FPS+ on GPU。 |
| 整体架构图 |  |
| CRelu的思路 | 
理解:作者观察到卷积核在conv5之后是完全呈现出反向的,也就是卷积核的向量夹角余弦值接近于-1。那么使用这样的卷积核做卷积在做激活和先做relu,再取反做relu是几乎等价的,但是却省去了很多计算量。 CRelu只用在浅层,起到减少计算量的作用。 |
| Rapidly Digested Convolutional Layers | 出于速度上的考虑,使用了快速降低resolution的方案。这个结构完全可以当成backbone换成各种其他网络,比如resnet18。 
|
| Inception |  |
| 稠密anchor | 
在32x32的尺度上摆放了21(4x4 + 4+ 1)个anchor。 下面具体来解释这个21是怎么来的: 首先模型是在3个尺度上放置anchor,尺度分别是32x32、64x64、128x128。默认放置的anchor大小是这些尺度的4倍。比如32x32就分别在每个grid放置32x4=128的anchor,64x64放置256x256的anchor,128x128放置512x512的anchor。但是在32x32上除了放置128的框还会防止64和32的,所以实际上每个位置放置16个32x32的,4个64x64的,1个128x128的共21个anchor。 |
| BlazeFace(2019) | | |
| InsightFace(2019) | | |
四.常见GAN模型
GAN经典网络
| 模型名称 | 记忆点 | 备注 |
| GAN | 基本思路 |
- 生成式模型从图像学习联合概率分布,生成fake图像。
- 判别式模型学习条件概率分布,判断图像是真实样本还是生成式模型伪造的。
- 通过对抗训练达到最优解,使用反向传播训练。
|
| 架构简图 | 
|
| 价值函数 | |

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!



 19
19 0
0

 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)