机器学习入门 —— 超级详细的KNN算法学习笔记、KNN算法的三要素、KNN算法的优缺点
文章目录KNN(K nearest neighbors)K值的选择和影响k取值偏小k取值偏大样本点距离的计算方式闵可夫斯基距离曼哈顿距离欧几里得距离切比雪夫距离余弦距离决策函数的选择用于分类的多票表决法用于回归的平均值法KNN算法的优缺点KNN(K nearest neighbors)简介K近邻 (k-Nearest Neighbors, KNN) 算法是一种分类与回归算法,是机器学习算法中最基础
文章目录
KNN(K nearest neighbors)
-
简介
K近邻 (k-Nearest Neighbors, KNN) 算法是一种分类与回归算法,是机器学习算法中最基础、最简单的算法之一, 1968年由 Cover和 Hart 提出, 应用场景有字符识别、 文本分类、 图像识别等领域。 -
算法的核心思想
一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别,具体来说即每个样本都可以用它最接近的k个邻居来代表。
如下图,如果 K = 1,未知数据(绿色的问号点)被小圈中的红色方块”决策“为class2 ;如果 K = 2 , 未知数据就会被大圈里的蓝色三角形”决策“为class1(理由是,有3个蓝色三角,大于红色方块的数目)。

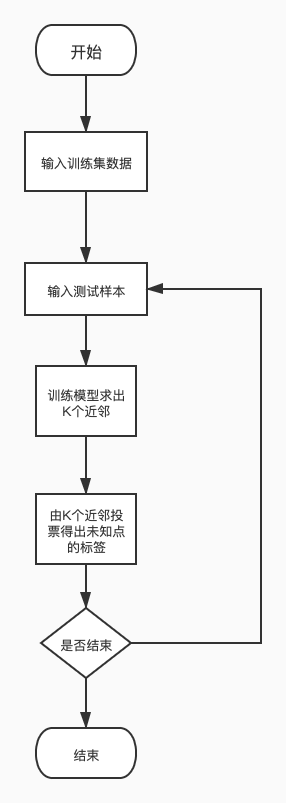
- 算法执行的步骤
- 构造训练样本集,样本集中每一数据都有一个标签;
- 输入没有标签的数据,根据每一个维度的特征,从样本集选出k的最靠近的邻居;
- 用这k个邻居去投票得出未知数据的标签。
-
学习特点
K近邻算法是监督学习,训练样本集中的每一个数据都有确定的已知的标签。
K近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。 -
KNN算法的三要素
距离待预测点的邻居的个数K;
样本点之间距离的计算方式;
决策函数的选择;
下面分点依次对着KNN的三要素进行介绍。
K值的选择和影响
K是K近邻算法中的唯一一个超参数。
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
记样本数据集的容量为n;
K的选取一般来源于经验,一般选取一个较小的大于1的奇数,一般在
(
1
,
n
)
(1,\sqrt n)
(1,n)。
- n较小时,n取 ( 1 , 10 ) (1,10) (1,10)中的奇数;
- n较大时,n取 ( 1 , n / 2 ) (1,\sqrt n/2) (1,n/2)中的奇数;
简单介绍一下,k值过小或过大的对预测结果的影响。
k取值偏小
k取值偏小时,预测结果对近邻点的周围的实例及其敏感,容易受到噪声点的干扰,导致过拟合。
不妨取k的一个极小值来分析,比如 k = 1 k = 1 k=1,那么绿色三角形原本属于红色方块的类别,但却由于一个最邻近的噪声点呗误判为蓝色方块类型。

k取值偏大
k取值偏大时,相当于用较大邻域中的训练实例进行预测,模型鲁棒性比较好,其优点是可以减少学习的估计误差,但会导致欠拟合,因为离测试点很远的实例也会影响到预测结果,这就违背了KNN算法的基本思想 —— 用邻居数据点的去决策出未知点的类别。
如下图,有于K值取值太大,所以即使离三角形很远的点也被纳入的考虑范围,所以导致预测结果是真。

样本点距离的计算方式
在上述阐述中,经常需要衡量实例点之间的距离,而特征空间中的两个实例点的距离是两个实例点相似程度的反映。
不同的距离计算方式,有不同的几何意义,所以对结果的评价的也不近相同。
下面介绍几个数学上常用的距离计算。
假设有两个 m m m维的向量: x = [ x 1 , x 2 , … x i , … , x m ] x = [x_1,x_2,…x_i,…,x_m] x=[x1,x2,…xi,…,xm]
闵可夫斯基距离
严格来说闵氏距离并不是某种特定的距离,而是距离的一个定义:
p是参数
L
p
=
(
∑
i
=
1
m
∣
x
i
−
y
i
∣
p
)
1
p
L_p = (\sum_{i=1}^m |x_i - y_i |^{p} )^{{\tfrac{1}{p}}}
Lp=(i=1∑m∣xi−yi∣p)p1
曼哈顿距离
L 1 = ( ∑ i = 1 m ∣ x i − y i ∣ ) L_1 = (\sum_{i=1}^m |x_i - y_i | )^{} L1=(i=1∑m∣xi−yi∣)
欧几里得距离
欧式距离是最常用在KNN算法距离计算中的。
它反映的是m维空间的点与点(向量与向量)之间的距离。
L
2
=
(
∑
i
=
1
m
∣
x
i
−
y
i
∣
2
)
1
2
L_2 = (\sum_{i=1}^m |x_i - y_i |^{2} )^{{\tfrac{1}{2}}}
L2=(i=1∑m∣xi−yi∣2)21
切比雪夫距离
由极限知识可以证明,当
p
p
p趋向于无穷大时,闵氏距离等于两个向量各特征维度差值的最大值
L
∞
=
max
i
=
1
m
(
∣
x
i
−
y
i
∣
)
L_\infty = \max_{i=1}^{m}(|x_i-y_i|)
L∞=i=1maxm(∣xi−yi∣)
余弦距离
上述三种距离体现的是数值上的绝对差异,而余弦距离体现方向上的相对差异。
两个向量之间的余弦公式为:
s
i
m
i
l
a
r
i
t
y
=
c
o
s
(
θ
)
=
∑
i
=
1
m
x
i
∗
y
i
∑
x
i
2
∑
y
i
2
similarity = cos(\theta) = \frac{\sum_{i=1}^m x_i*y_i}{\sqrt{\sum x_i^{2}} \sqrt{\sum y_i^{2}} }
similarity=cos(θ)=∑xi2∑yi2∑i=1mxi∗yi
那么 余弦距离为:
d
i
s
t
a
n
c
e
=
1
−
s
i
m
i
l
a
r
i
t
y
distance = 1 - similarity
distance=1−similarity
显然,
d
i
s
t
a
n
c
e
∈
[
0
,
2
]
distance \in [0,2]
distance∈[0,2]。
这个距离越小,说明两个向量在方向上差别越小,反之,方向差异性大。
决策函数的选择
用于分类的多票表决法
记输入训练集为
T
=
{
(
x
1
⃗
,
y
1
)
,
…
,
(
(
x
i
⃗
,
y
i
)
)
,
…
,
(
x
n
⃗
,
y
n
)
}
T = \{ ( \vec{x_1},y_1) ,…,(( \vec{x_i},y_i) ),…,( \vec{x_n},y_n) \}
T={(x1,y1),…,((xi,yi)),…,(xn,yn)}
其中
x
i
=
[
x
i
1
,
x
i
2
,
…
,
x
i
m
]
∈
R
m
x_i = [x_{i1},x_{i2},…,x_{im}] \in R^m
xi=[xi1,xi2,…,xim]∈Rm为
m
m
m维向量,
y
i
∈
{
t
1
,
t
2
,
.
.
.
}
y_i \in \{t_1,t_2,... \}
yi∈{t1,t2,...}为第
i
i
i个向量的标签。
在分类任务中可使用投票法,即选择这k个实例中出现最多的标记类别作为预测结果;
根据多票表决法,确定测试实例的标签为:
c 0 = arg max ∑ x k ∈ N K ( x ) I ( c , y k ) , c ∈ N k ( y ) c_0 = \argmax \sum_{x_k \in N_K(x)} I(c,y_k),c \in N_k(y) c0=argmaxxk∈NK(x)∑I(c,yk),c∈Nk(y)
上述的多数投票法,可能有如下缺陷。
最终因为蓝色方块的数目大于红色三角形的数量,所以,未知点被决策为蓝色方块,
但是很直观的发现,其实它属于红色圆形的可能性更大,因为距离更近一些。

如果仅仅按照 k 个邻居的占多数的决定最终的投票的结果,似乎有失公平,从生活经验出发,应该让与自己亲密的人、熟悉自己的朋友对自己的评价的权重的大一点,熟悉程度差一点的人的评价的权重小一点。
于是,可以使用加权多票表决法,这个时候,每一个邻居在“投票”的时候都要乘上一个权重,因为距离越远,权重越小,所以不妨让权重系数等于距离的倒数。
于是,产生预测标签的公式变为
c
0
=
arg max
∑
x
k
∈
N
K
(
x
)
I
(
c
,
y
k
)
∗
d
i
s
t
(
x
⃗
,
t
⃗
)
,
c
∈
N
k
(
y
)
c_0 = \argmax \sum_{x_k \in N_K(x)} I(c,y_k) * dist(\vec x,\vec t ),c \in N_k(y)
c0=argmaxxk∈NK(x)∑I(c,yk)∗dist(x,t),c∈Nk(y)
其中,dist为计算两个向量距离的函数,
t
⃗
\vec t
t为未知类别的数据点。
用于回归的平均值法
另外,KNN算法不仅用于分类,也可用于回归 —— 回归与分类的根本区别在于输出空间是否为一个度量空间。
所以,如果数据向量的对应的标签(类别)也可以进行量化衡量的话,
那么采用平均值法或加权平均值法就可以得出测试点的预测值。
平均值:
y
0
=
∑
i
k
y
i
k
y_0 = \frac{\sum_i^{k} y_i}{k}
y0=k∑ikyi
加权平均值:
y
0
=
∑
i
k
y
i
∗
d
i
s
t
(
x
⃗
,
t
⃗
)
k
y_0 = \frac{\sum_i^{k} y_i*dist(\vec x,\vec t)}{k}
y0=k∑ikyi∗dist(x,t)
KNN算法的优缺点
- 优点
- 算法本身简单、易于理解和实现
- 精度较高、对异常值不敏感
- 适用于大样本自动分类
- 需要参数估计很少,只有一个邻居个数 k k k
- 惰性学习,学习阶段仅仅是保存数据而已
- 缺点
- 计算时间复杂度高
- 内存开销大,训练数据停驻在内存中
- 输出可解释性不强

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 73
73 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)