
什么是ElasticSearch?看完这一篇你就懂了
es常用操作学习教程
文章目录
一.什么是ElasticSearch?
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,通过面向文档从而让全文搜索变得简单。
二.核心概念
1.倒排索引
首先要了解索引表:由关键词为key,关键词位置属性为value组成的一张表。由于该表不是由key来确定value值,而是由value的属性值来确定key的位置,所以称为倒排索引,带有倒排索引的文件称为倒排文件。通俗的讲倒排索引就好比书的目录,通过目录咱们可以准确的找到相应的数据。
2.Cluster(集群)
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
3.Node(节点)
形成集群的每个服务器称为节点。
4.Shard(分片)
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
5.Replia(副本)
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
6.全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
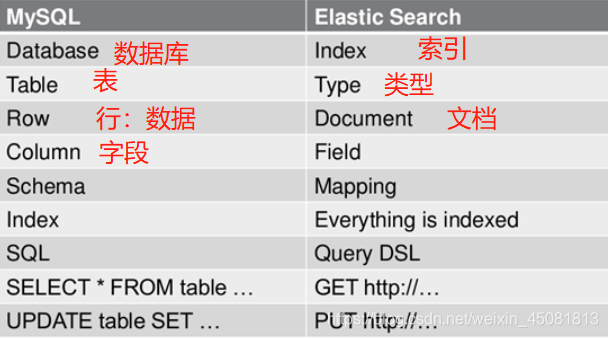
三.MySQL与ElasticSearch的对比
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
四.IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看成一个词,比如"我爱技术"会被分为"我",“爱”,“技”,“术”,这显然不符合要求,所以我们需要安装中文分词器IK来解决这个问题
IK提供了两个分词算法:ik_smart和ik_max_word
其中ik_smart为最少切分,ik_max_word为最细粒度划分
EG:
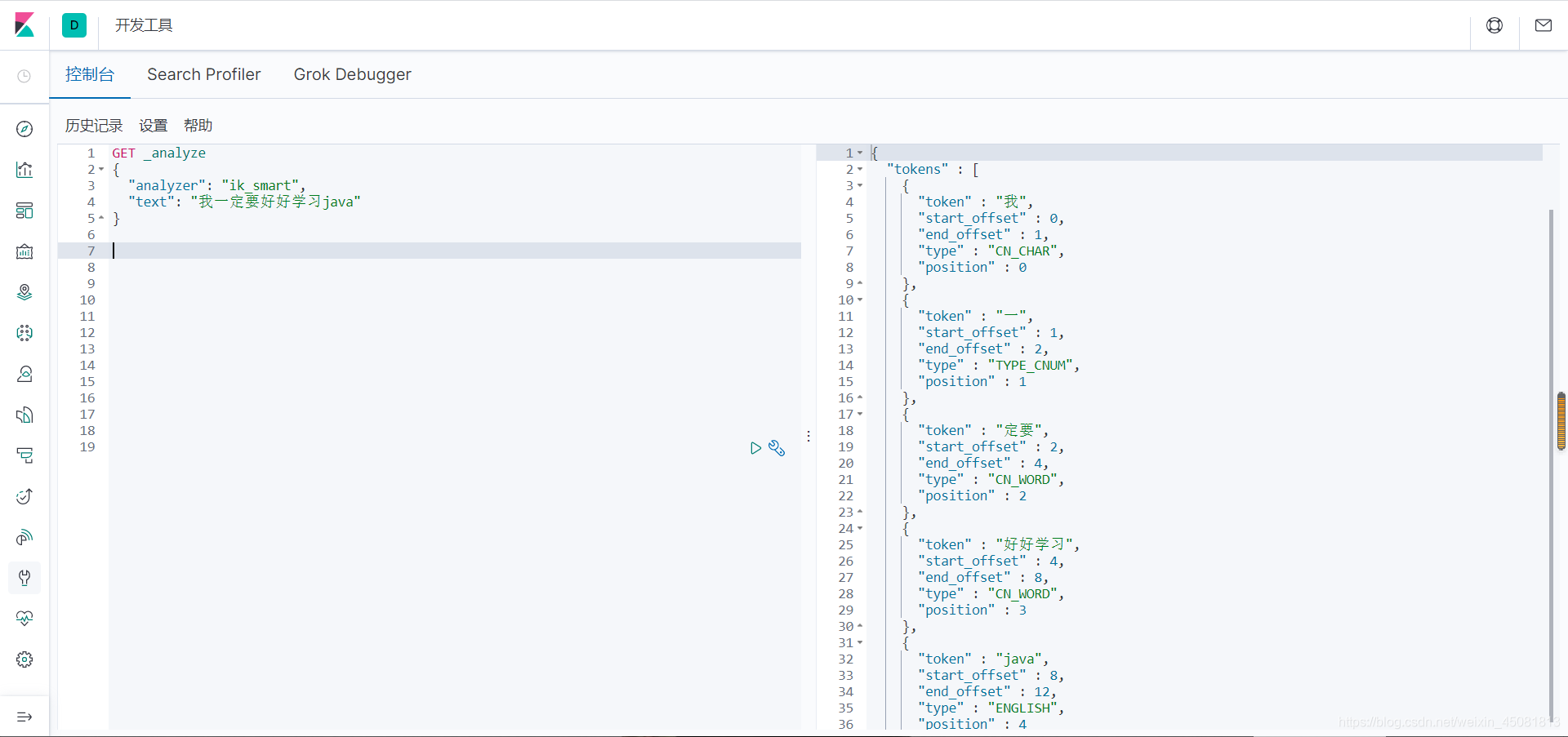
1.ik_smart
最少切分,分的词中不会有重复的字
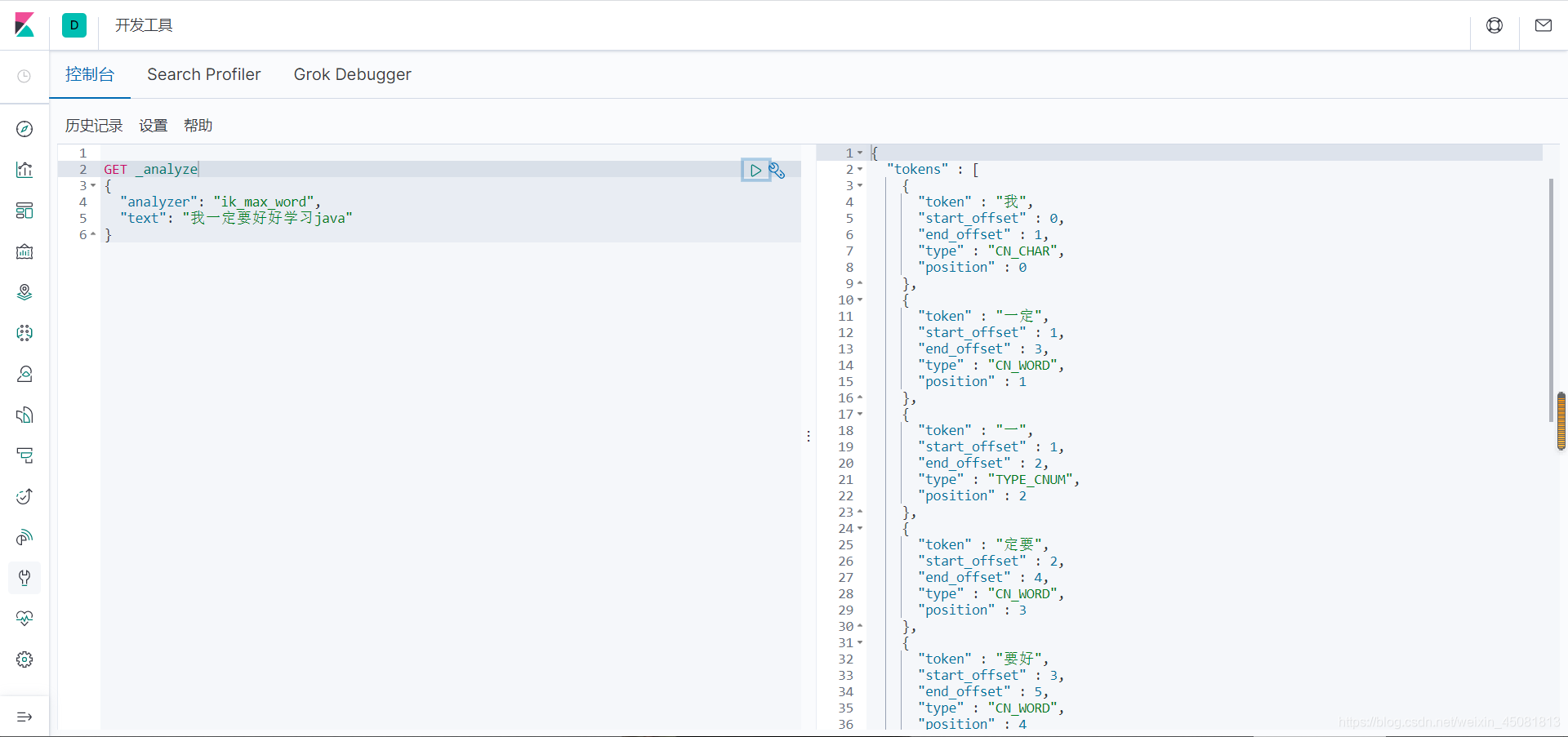
2.ik_max_word
最细粒度划分,穷尽词库的可能
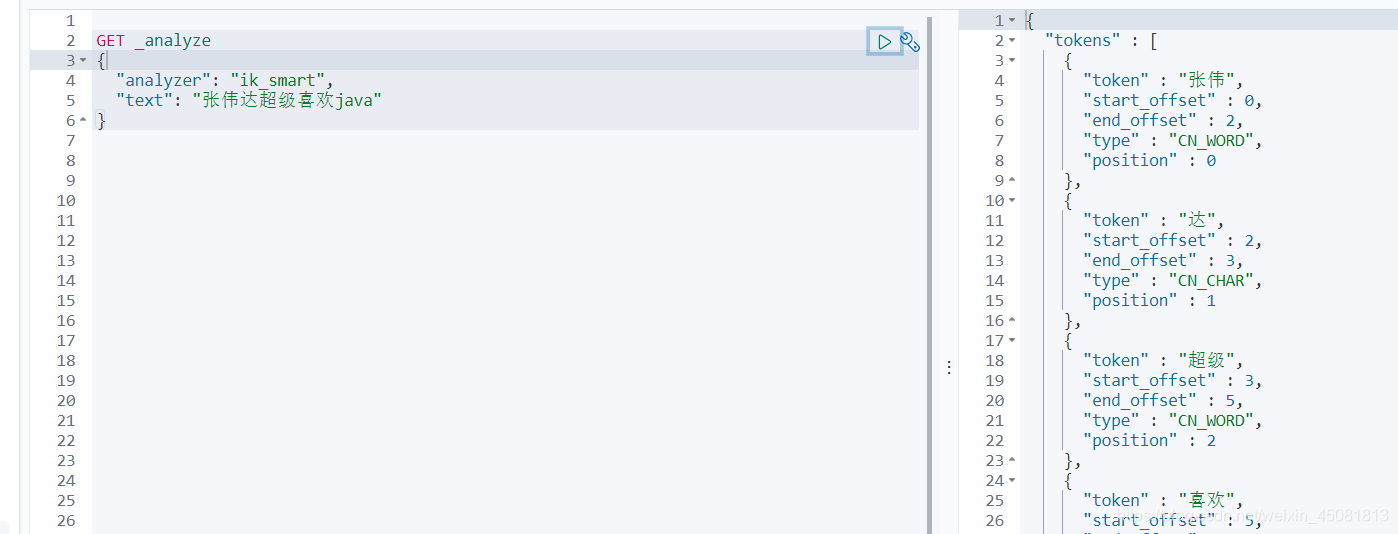
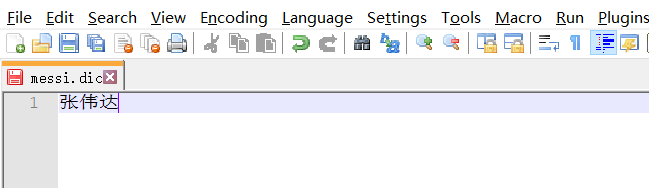
如果他不认为查询的词 比如 张伟达 不是一个词, 则这种自己需要的词,需要自己加到字典中
创建messi.dic
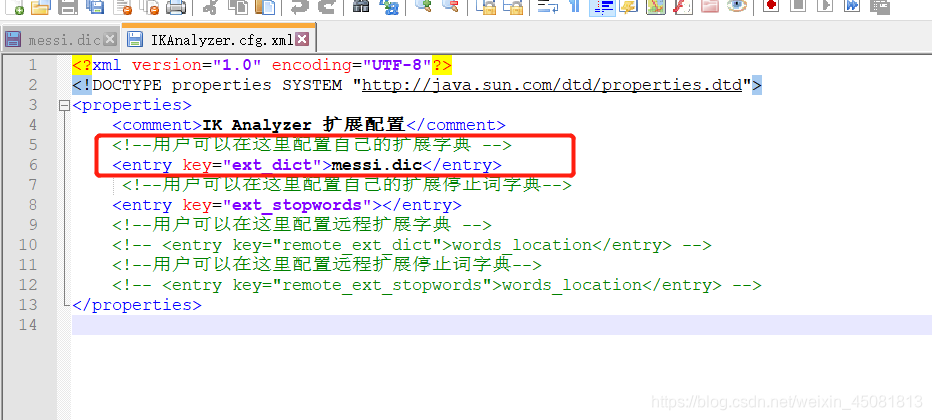
在ik/config/IKAnalyzer.cfg.xml中添加我们自己的词典
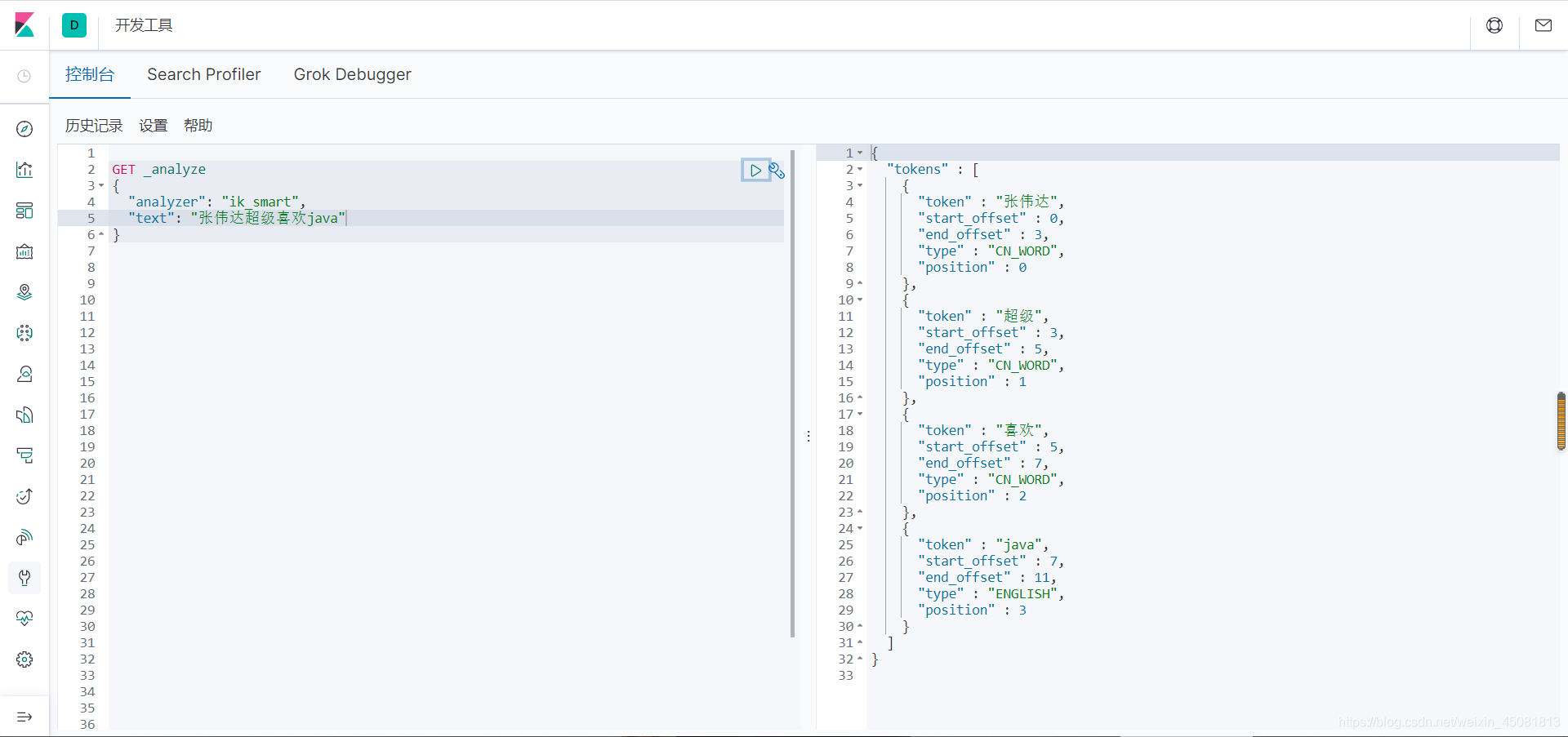
重启ES,然后测试
注意:加入的词典(dic文件)和IKAnalyzer.cfg.xml的编码要一致!!!
五.基于restful风格的操作命令
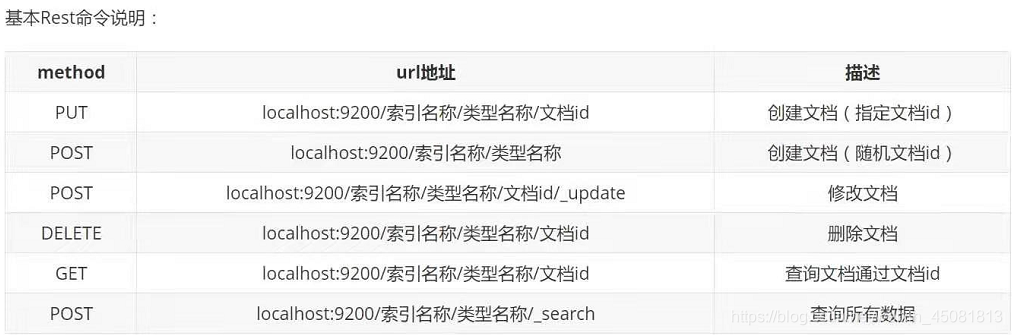
1.添加删除索引
DELETE test_wsy
PUT test_wsy
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"fields": {
"rawName": {
"type": "keyword"
}
}
},
"desc": {
"type": "text"
},
"age": {
"type": "integer"
},
"depName": {
"type": "keyword"
},
"aptDate": {
"type": "text"
},
"created_at": {
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"type": "date"
}
}
}
}
- 通过GET请求获得具体信息
GET test_wsy

2.添加数据
- PUT /索引名/类型名/文档id:创建一个指定id的文档
- POST /索引名/类型名: 不指定ID插入时会自动生成,需要使用POST请求
POST /test_wsy/_doc
{
"id":1,
"name":"小明",
"desc":"数学成绩很好",
"age":18,
"depName":"科技部"
}
PUT /test_wsy/_doc/2
{
"id":2,
"name":"小王",
"desc":"历史成绩很好",
"age":20,
"depName":"财务部"
}
POST /test_wsy/_doc
{
"id":3,
"name":"小明",
"desc":"数学成绩很好",
"age":18,
"depName":"财务部"
}
PUT /test_wsy/_doc/4
{
"id": 4,
"name": "小王",
"desc": "历史成绩很好",
"age": 20,
"depName": "科技部"
}
PUT /test_wsy/_doc/5
{
"id": 5,
"name": "小刘",
"desc": "英语很好",
"age": 40,
"depName": "科技部"
}
PUT /test_wsy/_doc/6
{
"id": 6,
"name": "大王",
"desc": "物理成绩很好",
"age": 20,
"depName": "科技部"
}
3.修改数据
- 通过继续提交PUT覆盖原来的值
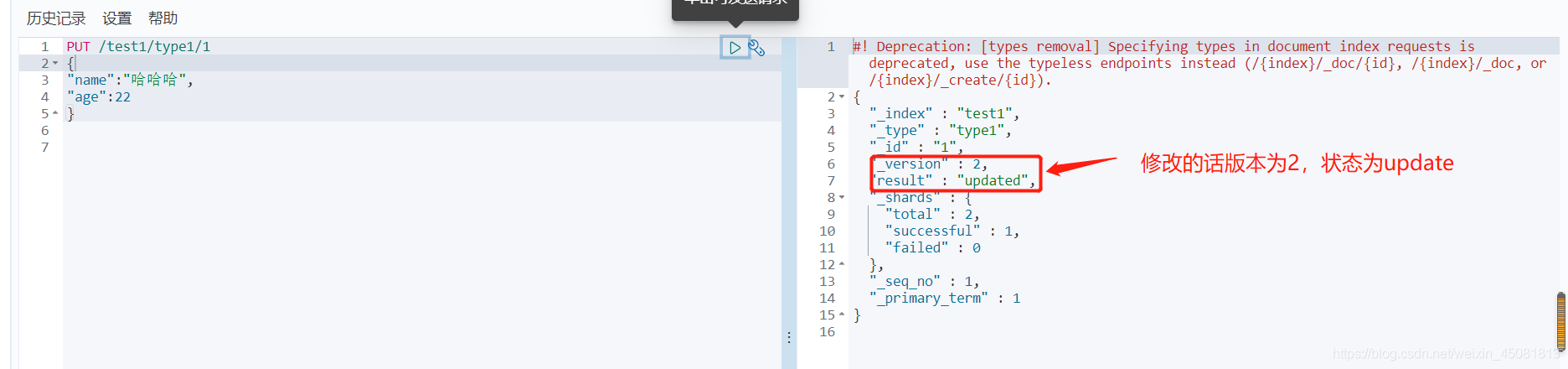
- 通过POST进行修改,后面需要加上_update
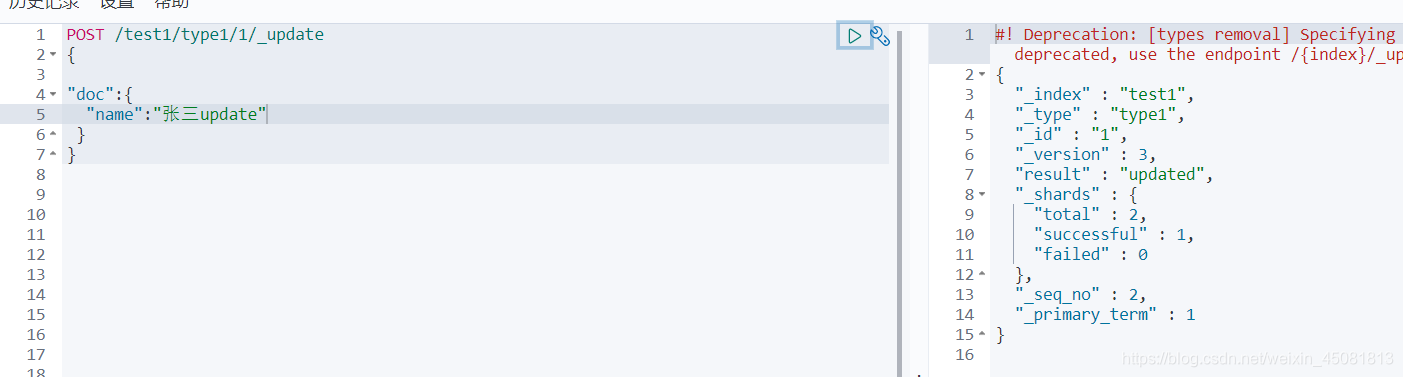
4.删除数据

5.查询数据
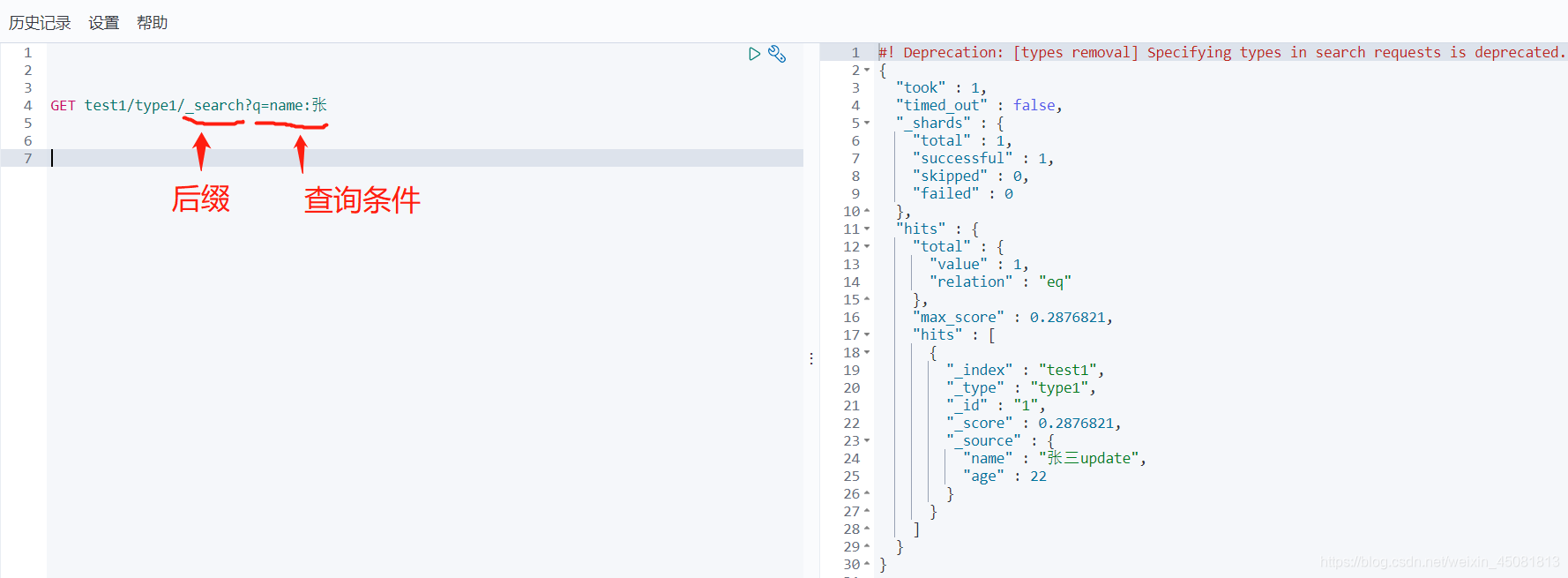
六.复杂查询
1.聚合查询
query先查询,然后基于查询结果进行聚合统计
- 局部bucket统计与全局global bucket统计
global:{} 在aggs 的分组名字内部, 就是忽略上面的查询条件, 进行全局统计
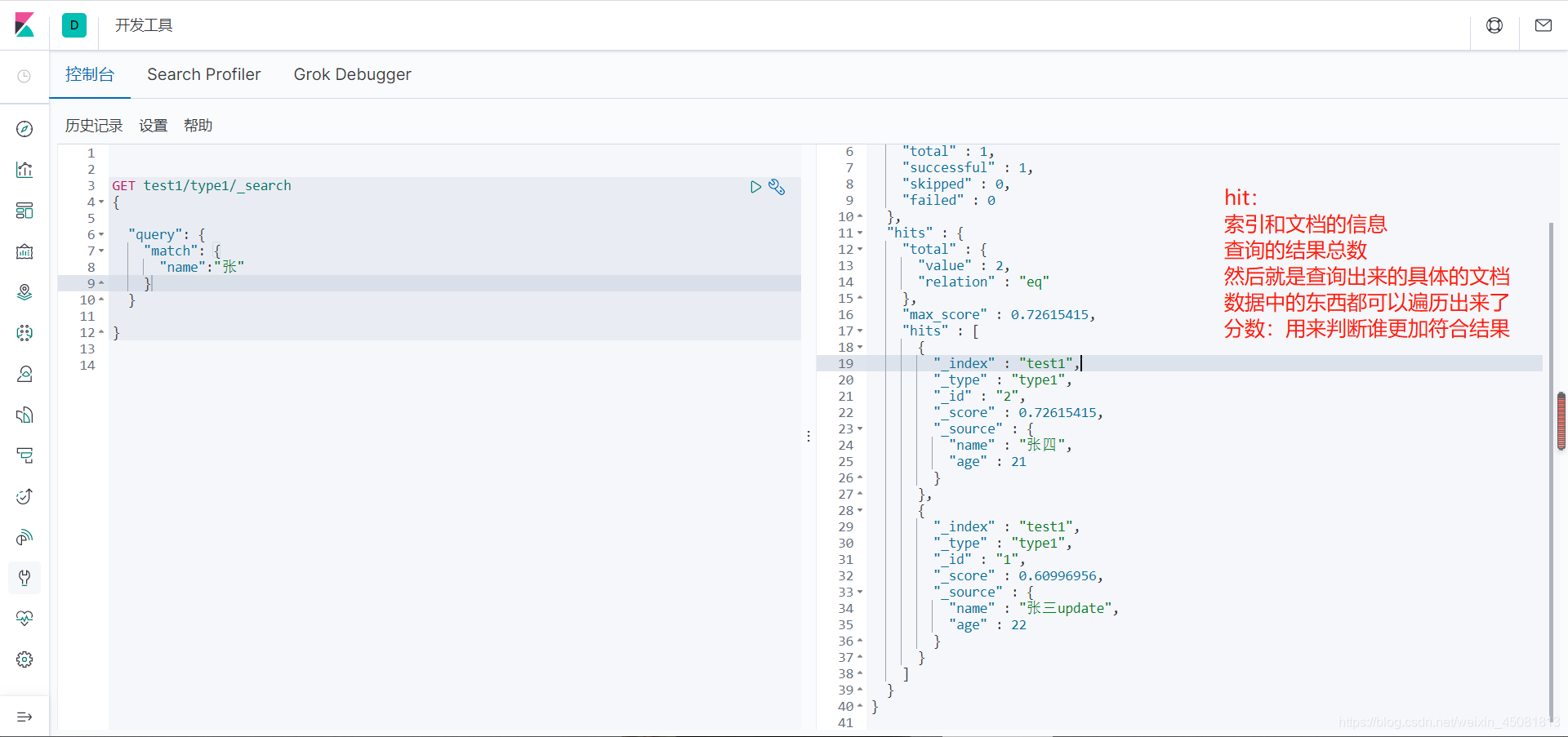
GET /test_wsy/_search
{
"query": {
"bool": {
"must": {
"match_phrase": {
"depName": "科技部"
}
}
}
},
"aggs": {
"test_avg_age": {
"avg": {
"field": "age"
}
},
"test_max_age": {
"max": {
"field": "age"
}
},
"test_min_age": {
"min": {
"field": "age"
}
},
"all_avg_age":{
"global": {},
"aggs": {
"all_avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}

2.keyword和text
text会对字段进行分词处理而keyword则不会进行分词,即text支持模糊查询,keyword只能精准查询
text类型的数据不能用来过滤、排序和聚合等操作;keyword用来过滤、排序和聚合。
- 同字段多type配置
创建索引,在mapping中通过fields关键字给name字段添加别名rawName,类型为keyword,用来做精确匹配以及排序。
创建索引
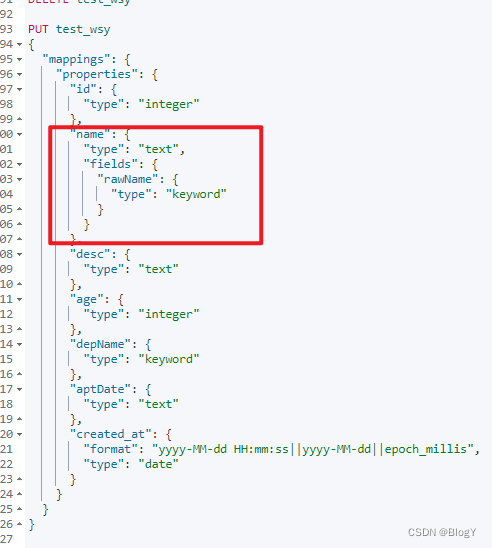
添加数据
POST /test_wsy/_doc
{
"id":1,
"name":"小明",
"desc":"数学成绩很好",
"age":18,
"depName":"科技部"
}
PUT /test_wsy/_doc/2
{
"id":2,
"name":"小王",
"desc":"历史成绩很好",
"age":20,
"depName":"财务部"
}
POST /test_wsy/_doc
{
"id":3,
"name":"小明",
"desc":"数学成绩很好",
"age":18,
"depName":"财务部"
}
PUT /test_wsy/_doc/4
{
"id": 4,
"name": "小王",
"desc": "历史成绩很好",
"age": 20,
"depName": "科技部"
}
PUT /test_wsy/_doc/5
{
"id": 5,
"name": "小刘",
"desc": "英语很好",
"age": 40,
"depName": "科技部"
}
PUT /test_wsy/_doc/6
{
"id": 6,
"name": "大王",
"desc": "物理成绩很好",
"age": 20,
"depName": "科技部"
}
精确查询
使用别名可以精确查询了
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name.rawName": {
"value": "明"
}
}
}
]
}
}
}
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name.rawName": {
"value": "小明"
}
}
}
]
}
}
}

GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "明"
}
}
}
]
}
}
}

GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "小明"
}
}
}
]
}
}
}
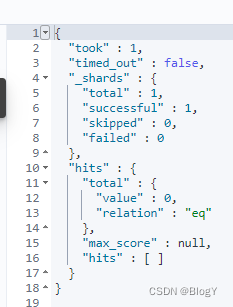
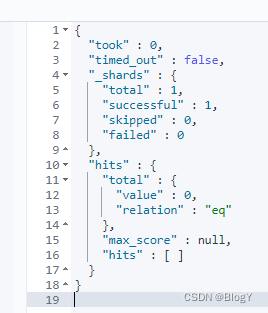
说明text类型的字段会被分词,查询的时候如果用拆开查可以查询的到,但是要是直接全部查,就是查询不到。
3.局部bucket统计与全局global bucket统计
- global:就是global bucket,即将所有数据纳入聚合的scope,而不管之前的query查询出来的数据,是对所有数据执行聚合后的。
- 局部bucket :基于query搜索结果来聚合的;


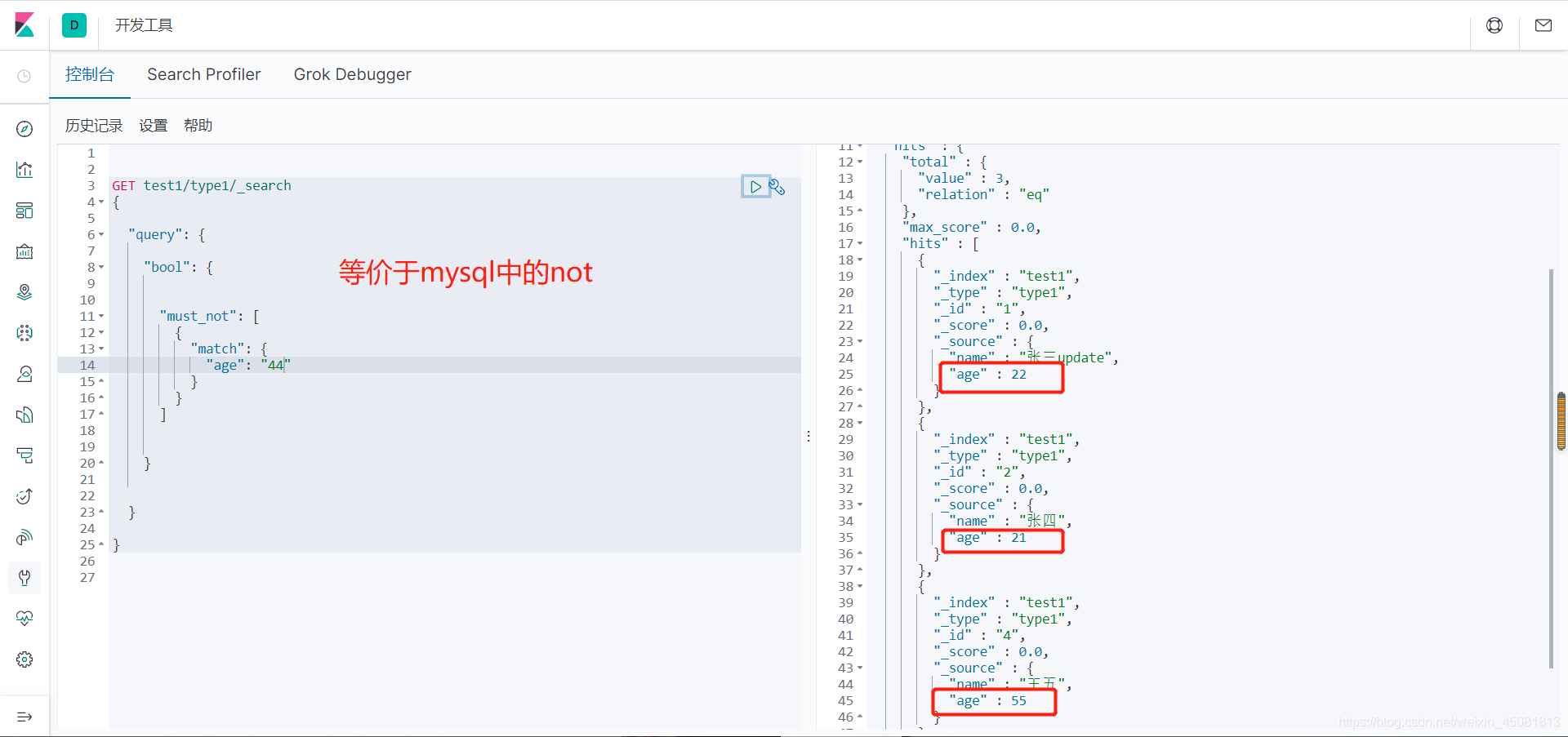
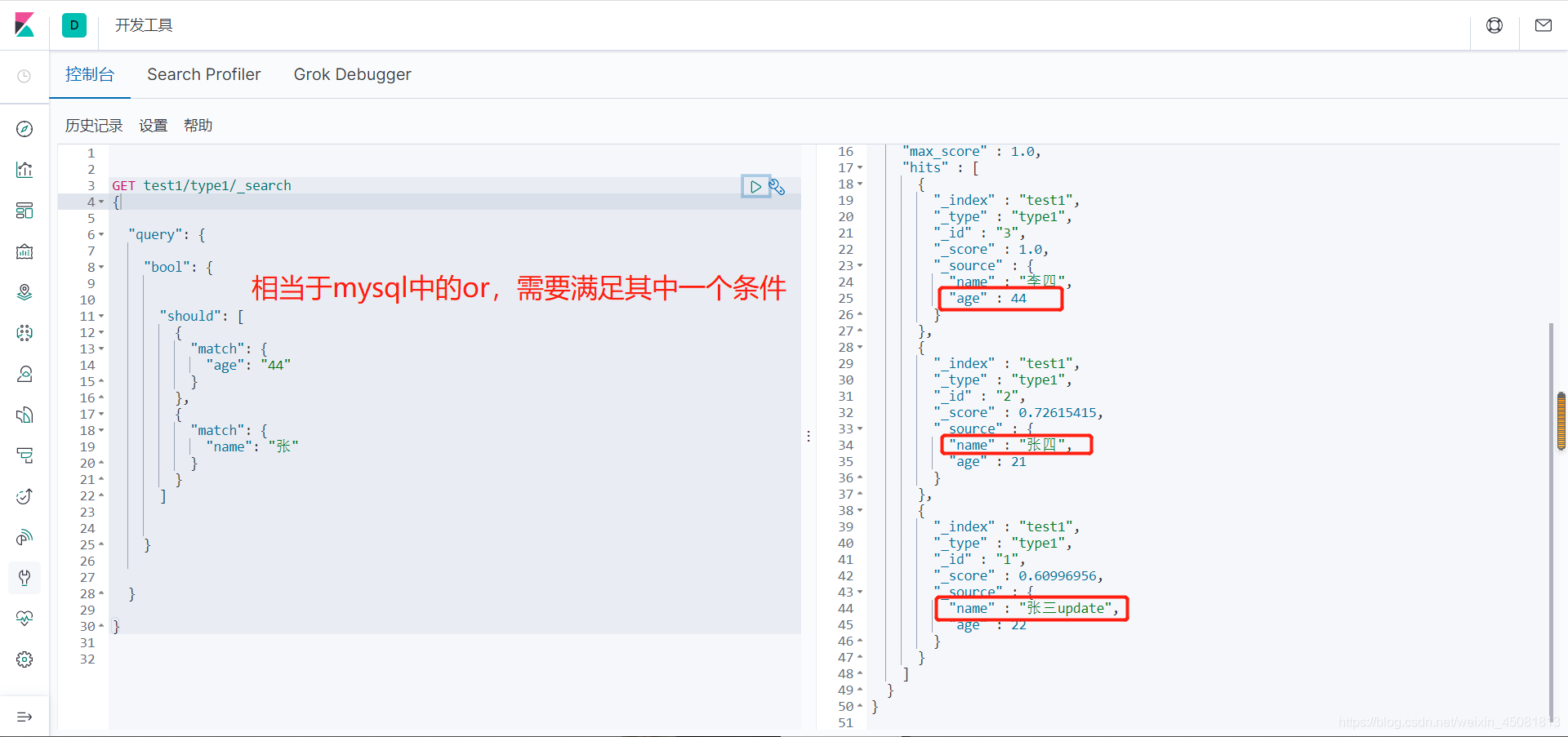
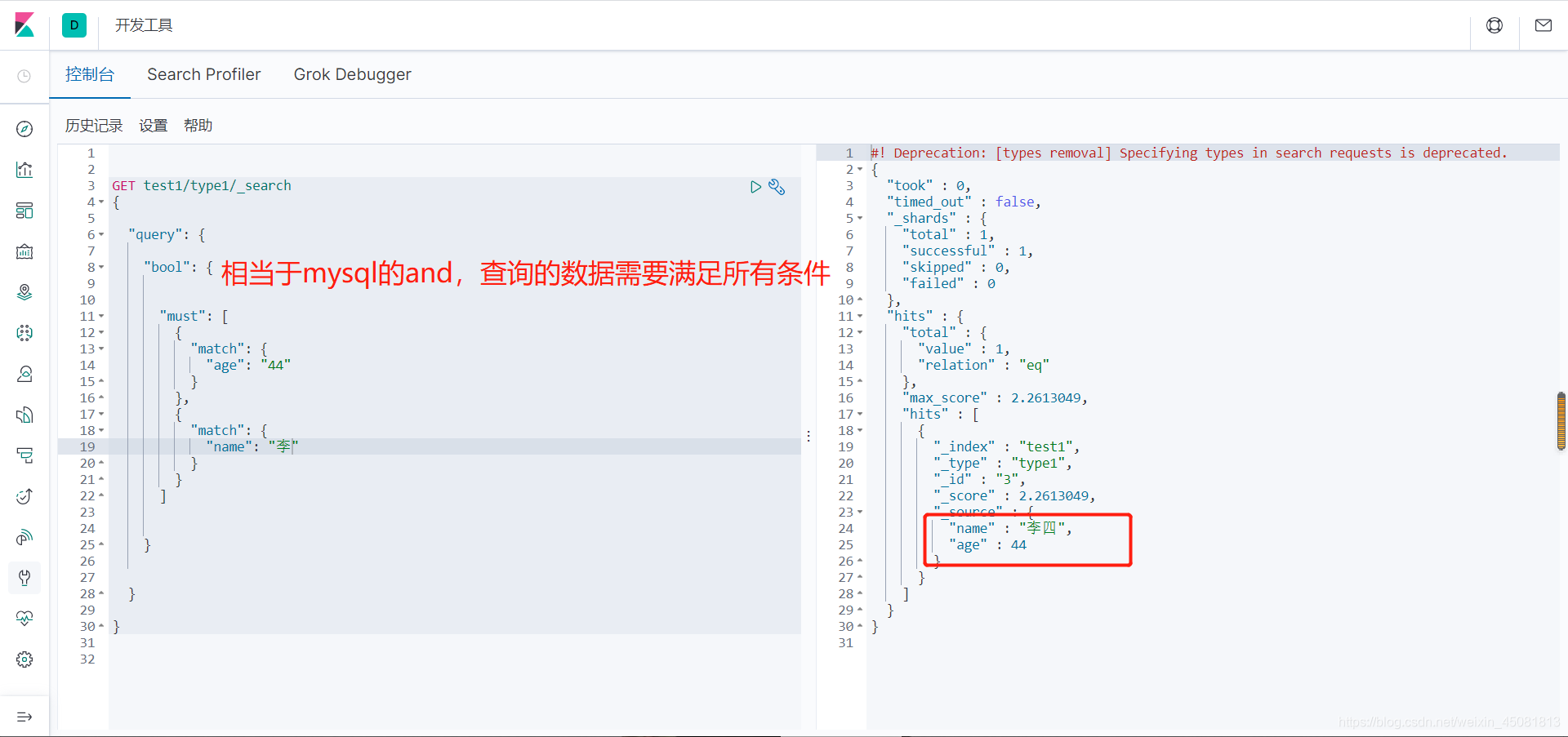
4.bool查询
-
must:与关系,相当于关系型数据库中的 and。
-
should:或关系,相当于关系型数据库中的 or。
-
must_not:非关系,相当于关系型数据库中的 not。
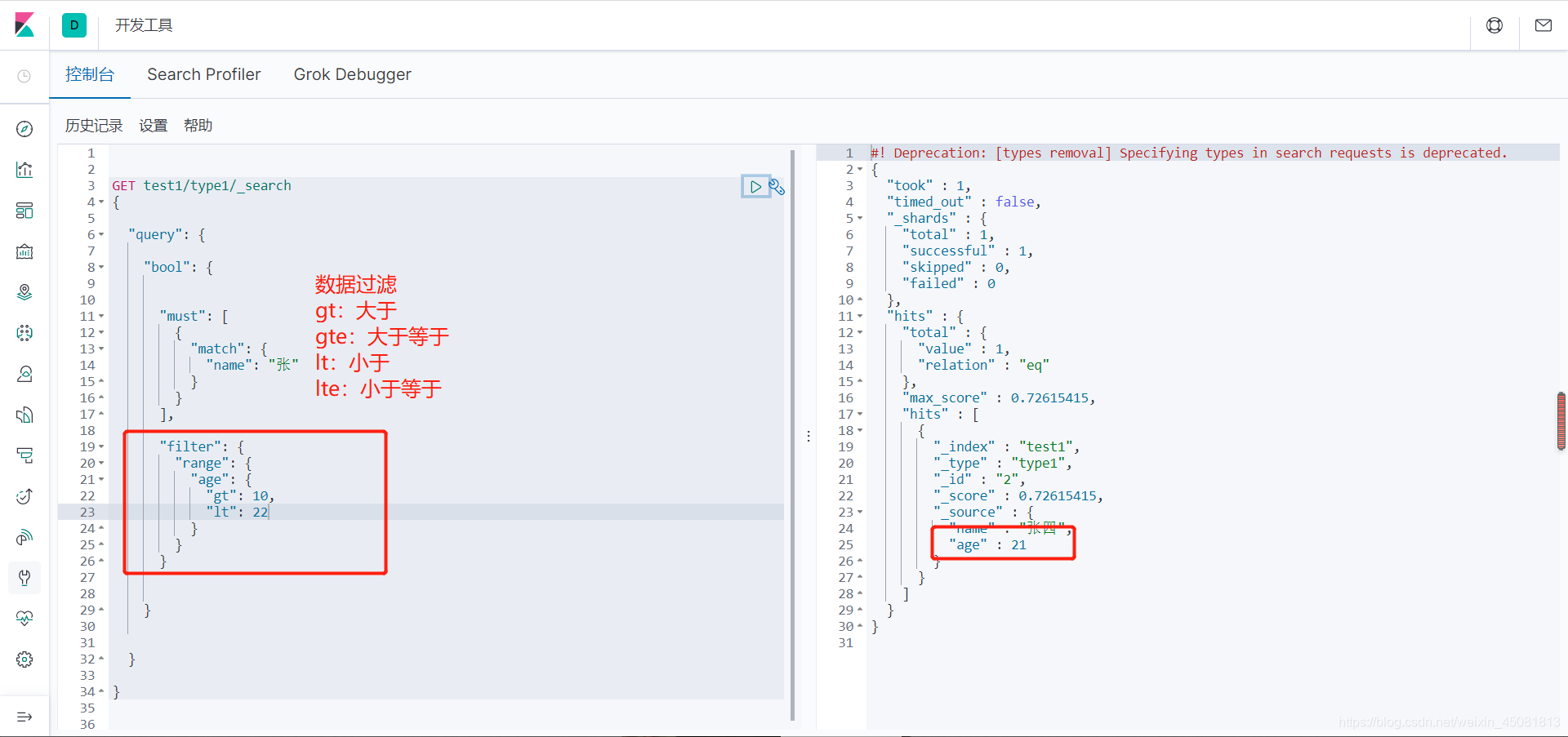
-
filter:过滤条件。
-
range:条件筛选范围。
-
gt:大于,相当于关系型数据库中的 >。
-
gte:大于等于,相当于关系型数据库中的 >=。
-
lt:小于,相当于关系型数据库中的 <。
-
lte:小于等于,相当于关系型数据库中的 <=
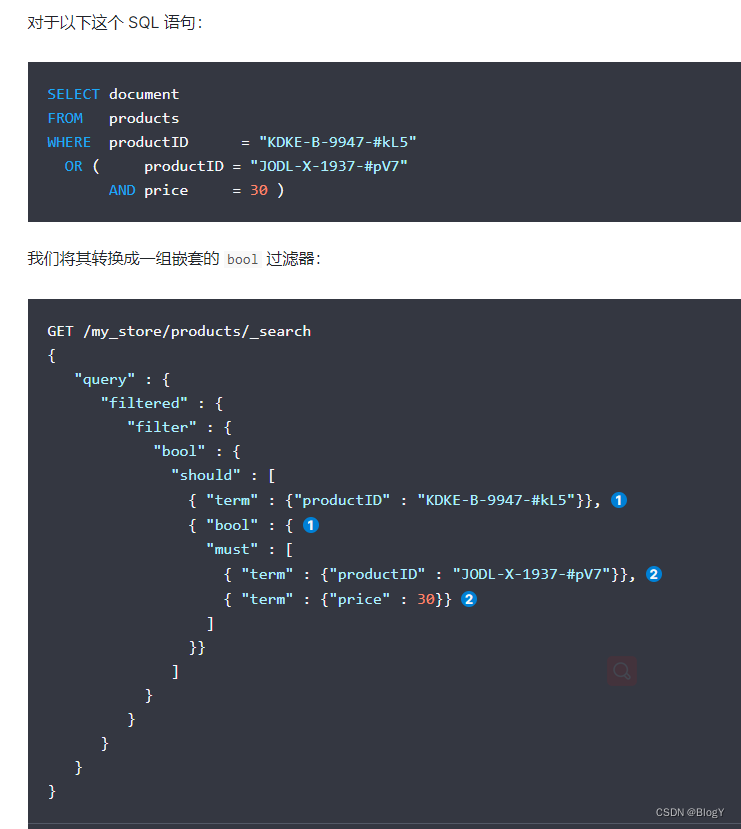
must和filter经常连用, should和filter不常在一起。
filter在bool内.与should和must同级,不要在query里和bool平级,语法错误。
EG1:
(city = ‘New York’ AND state = ‘NY’) AND ((businessName=‘Java’ and businessName=‘Shop’) OR (category=‘Java’ and category = ‘Shop’))
{
"query": {
"match_all": {}
},
"filter": {
"bool": {
"must": [
{
"term": {
"city": "New york"
}
},
{
"term": {
"state": "NY"
}
},
{
"bool": {
"should": [
{
"bool": {
"must": [
{
"term": {
"businessName": "Java"
}
},
{
"term": {
"businessName": "Shop"
}
}
]
}
},
{
"bool": {
"must": [
{
"term": {
"category": "Java"
}
},
{
"term": {
"category": "Shop"
}
}
]
}
}
]
}
}
]
}
}
}
EG2:
API
5.es中must,must_not,should不能同时生效
如果一个query语句的bool下面,除了should语句,还包含了filter或者must语句,那么should context下的查询语句可以一个都不满足,只是_score=0,所以上述查询语句,有无should语句,查询到的hits().total()是一样的,只是score不同而已。
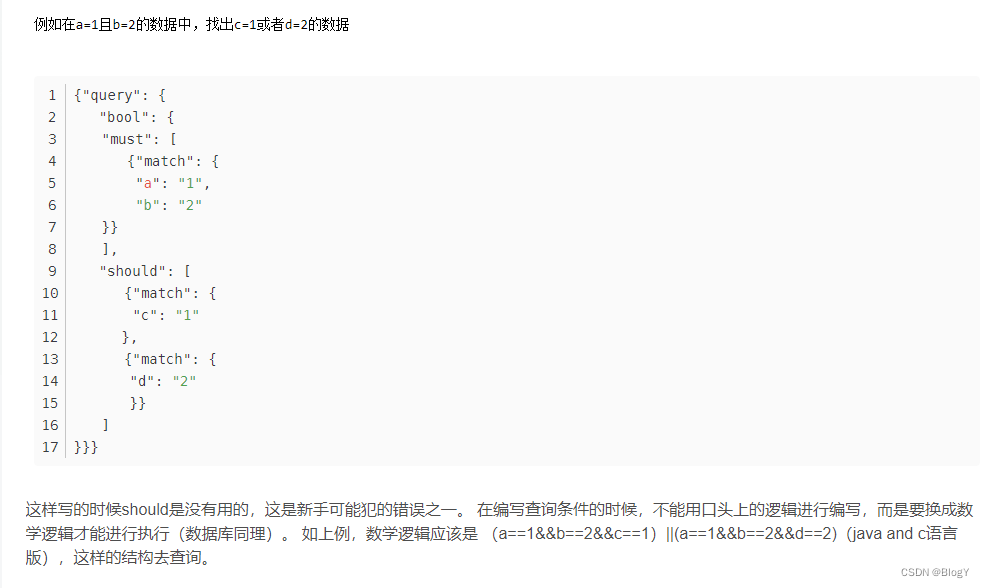

- 解决方法1:转换成复杂的组合查询 把should放到must或must_not里面
{
"query": {
"bool": {
"must": [{
// 先满足前置条件
"bool": {
"must": [{
"term": {
"dynamicType.keyword": "201"
}
}, {
"prefix": {
"viewTime.keyword": "2019-10-11"
}
}]
}
}, {
// 在满足后置条件
"bool": {
"should": [{
"term": {
"uniqueKey.keyword": "3a91b0abd3507ee8b7165e710382a411"
}
}, {
"term": {
"uniqueKey.keyword": "e5a359bcff112a98a6f7ea968d00ae3a"
}
}, {
"term": {
"uniqueKey.keyword": "0fb98f5dd7f86ff7d3f7c105d27cddb0"
}
}, {
"term": {
"uniqueKey.keyword": "ccc0a51553fc33e7c19bb822f8ff6048"
}
}]
}
}]
}
},
"from": 0,
"size": 10,
"sort": [{
"viewTime.keyword": {
"order": "desc"
}
}],
"aggs": {}
}
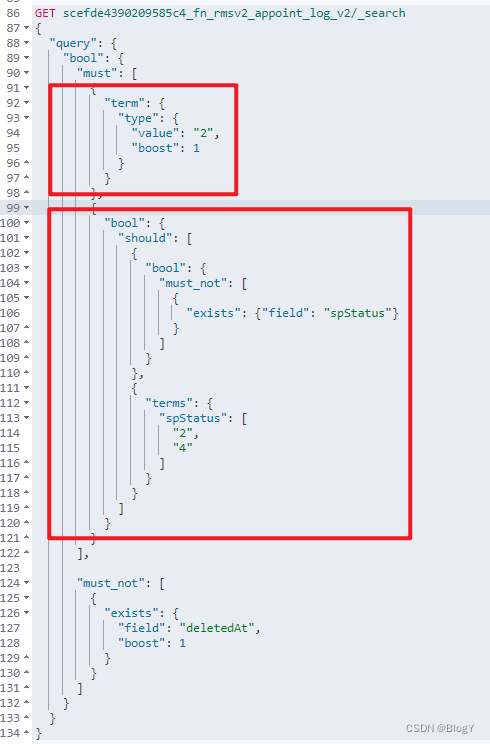
- 解决方法2:minimum_should_match
minimum_should_match代表了最小匹配精度,如果设置minimum_should_match=1,那么should语句中至少需要有一个条件满足,查询语句如下:

6.wildcard
通配符模糊查询,类似MySQL的like,但非常消耗性能:会把需要模糊查询的分成一个个单个的词,常适用于字母和数字的模糊查询
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"desc": {
"value": "语"
}
}
}
]
}
}
}

GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"desc": {
"value": "英语"
}
}
}
]
}
}
}
7.match、match_phrase、multi_match,term , terms
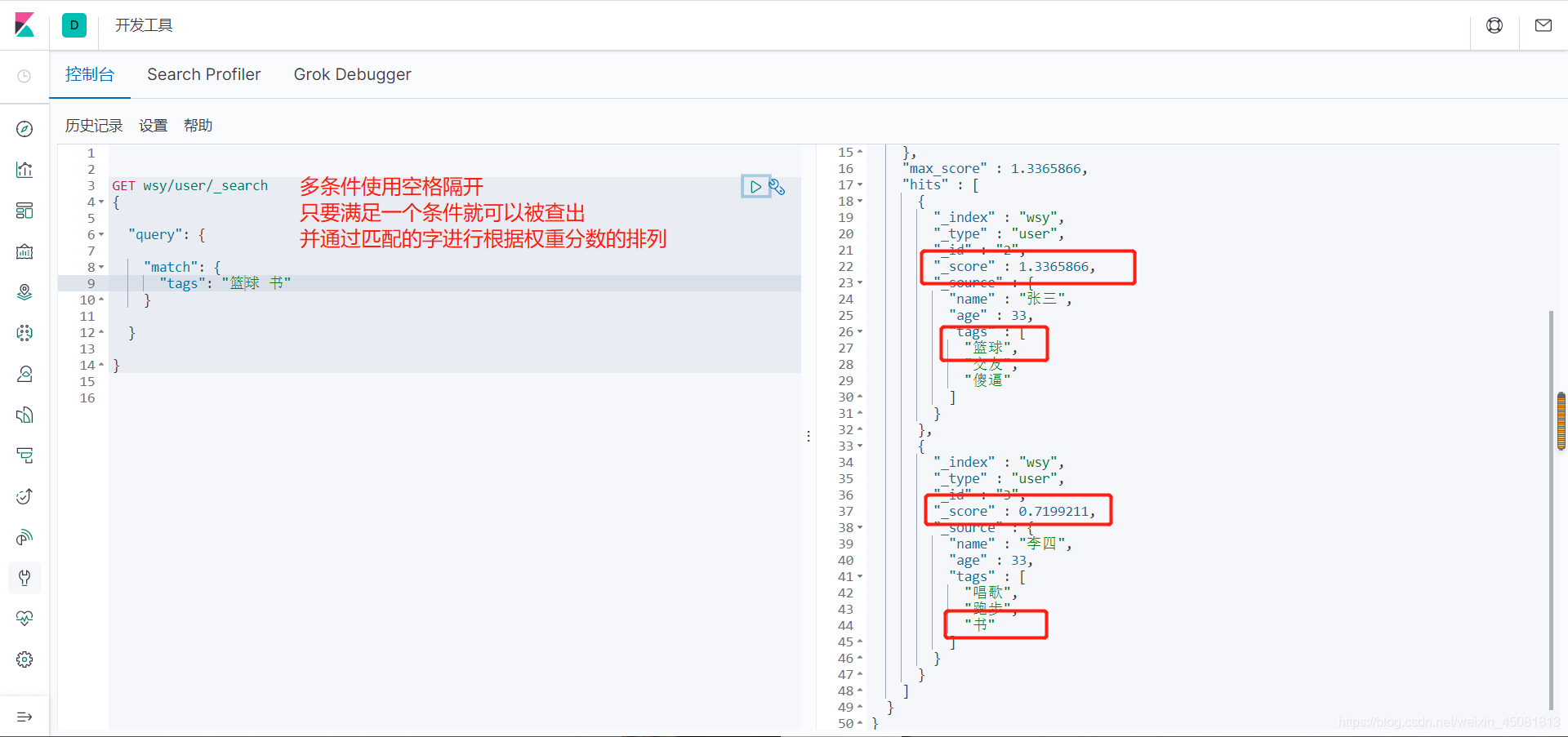
- match:用于搜索单个字段,首先会针对查询语句进行解析(经过 analyzer),主要是对查询语句进行分词,分词后查询语句的任何一个词项被匹配,文档就会被搜到,默认情况下相当于对分词后词项进行 or 匹配操作。
match还有2个比较重要的参数:operator和minimum_should_match,他们可以控制match查询的行为。
这个operater的默认值就是or,就是只要匹配到任意一个词,就算匹配成功,若要分词后的所有词全部匹配,可以设置 “operator”: “and”
minimum_should_match可以设置匹配的最小词数,不要与operator一起使用,意思会冲突。它可以赋值正数、负数、百分比等,但是我们常用的是设置一个正数,即指定最小匹配的词数。
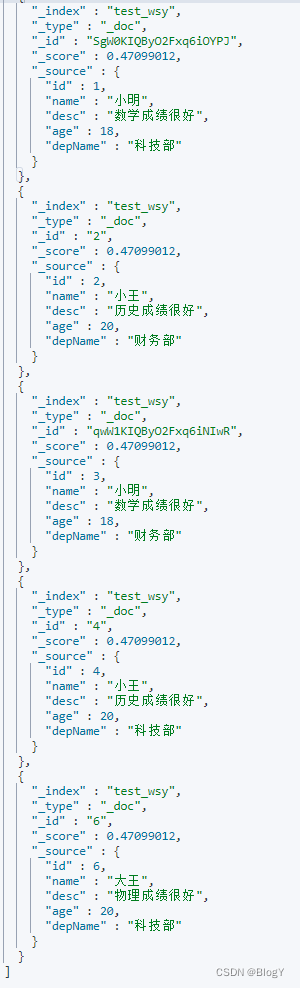
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "绩成"
}
}
]
}
}
}
会把“绩成“”分为“绩”和“成”,两个只要有一个包含在里面即可
语
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "阿拉伯语"
}
}
]
}
}
}

- match_phrase:首先会把 query 内容分词,分词器可以自定义,同时文档还要满足以下两个条件才会被搜索到,一是分词后所有词项都要出现在指定字段中,二是字段中的词项顺序要一致。查询内容会作为一个短语整体去匹配,而不会拆成多个字
"绩很"是连续的 在分词内 所以能够找到
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"desc": "绩很"
}
}
]
}
}
}

"很绩"没有按顺序 可能不在分词内 所以不能够找到
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"desc": "很绩"
}
}
]
}
}
}
“绩好“不是连续的 可能不在分词内 所以找不到
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"desc": "绩好"
}
}
]
}
}
}
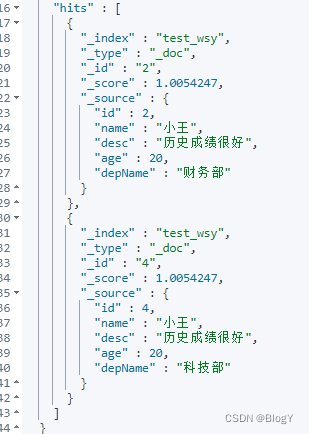
- multi_match:multi_match 是 match 的升级,用于搜索多个字段。查询语句为“java 编程”,查询域为 title 和 description
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "历",
"fields": ["name","desc"]
}
}
]
}
}
}
- term :查询用来查找指定字段中包含给定单词的文档,term 查询不被解析,只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精准匹配的需求。避免 term 查询对 text 字段使用查询,默认情况下,Elasticsearch 针对 text 字段的值进行解析分词,这会使查找 text 字段值的精确匹配变得困难。要搜索 text 字段值,需改用 match 查询。
name为text类型 无法查找
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "小明"
}
}
}
]
}
}
}
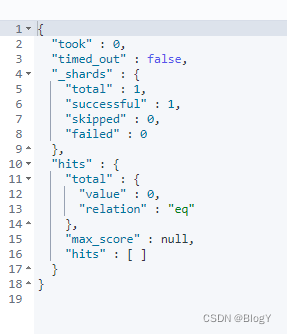
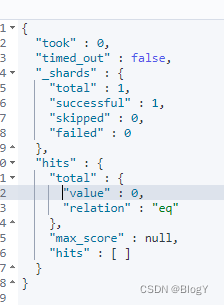
name.rawName为keyword类型 进行精确查找
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name.rawName": {
"value": "小明"
}
}
}
]
}
}
}
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name.rawName": {
"value": "明"
}
}
}
]
}
}
}
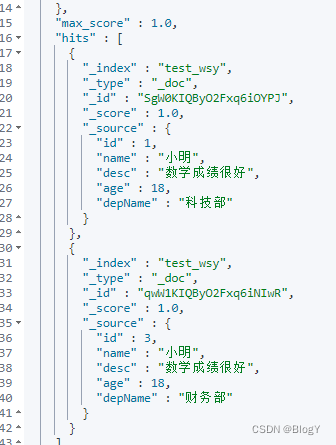
- terms:是 term 查询的升级,可以用来查询文档中包含多个词的文档。比如,想查询 title 字段中包含关键词 “java” 或 “python” 的文档
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"terms": {
"name.rawName": [
"小明",
"小黄"
]
}
}
]
}
}
}
总结:在text上应该用match、match_phrase来全文搜索 而term,terms常用在keyword类型
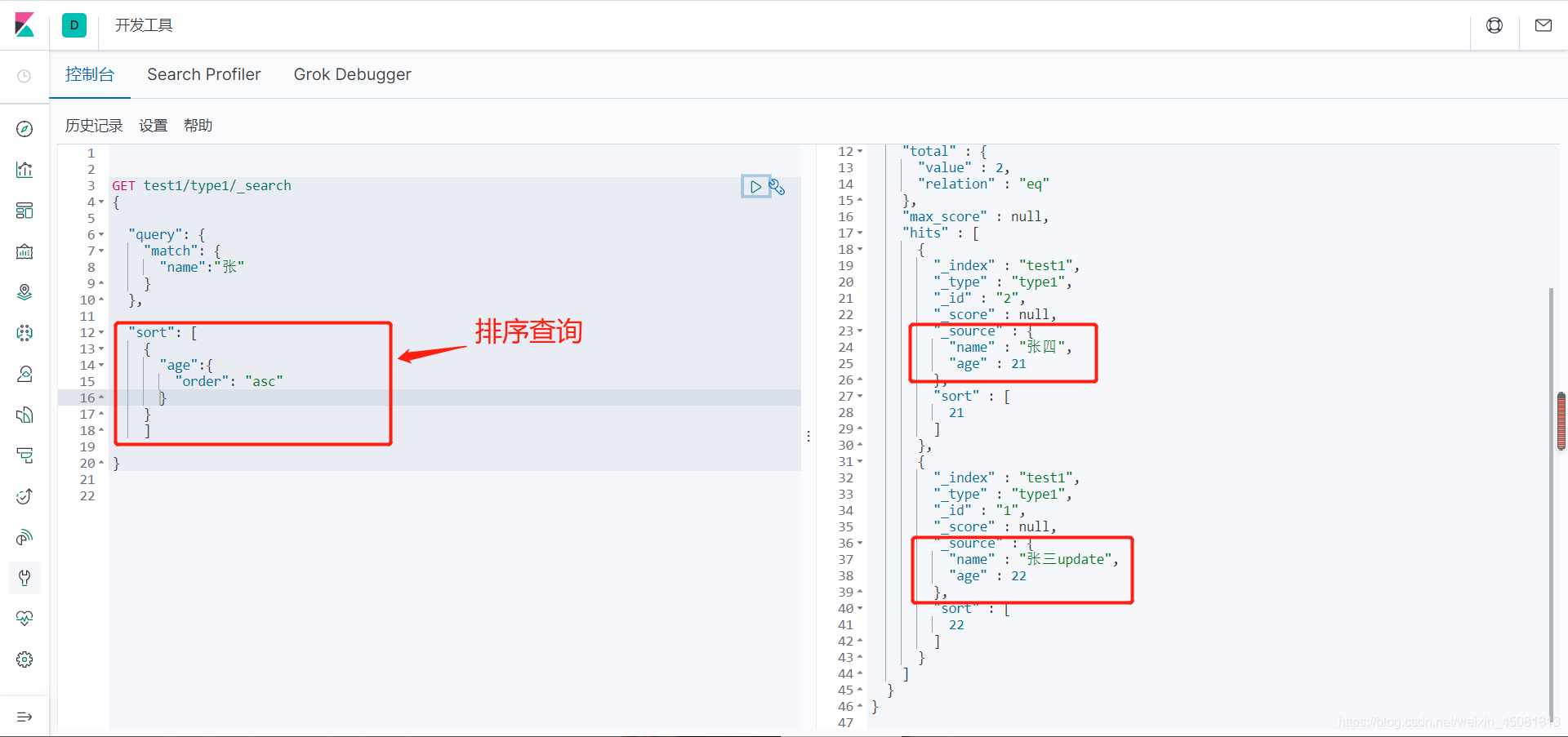
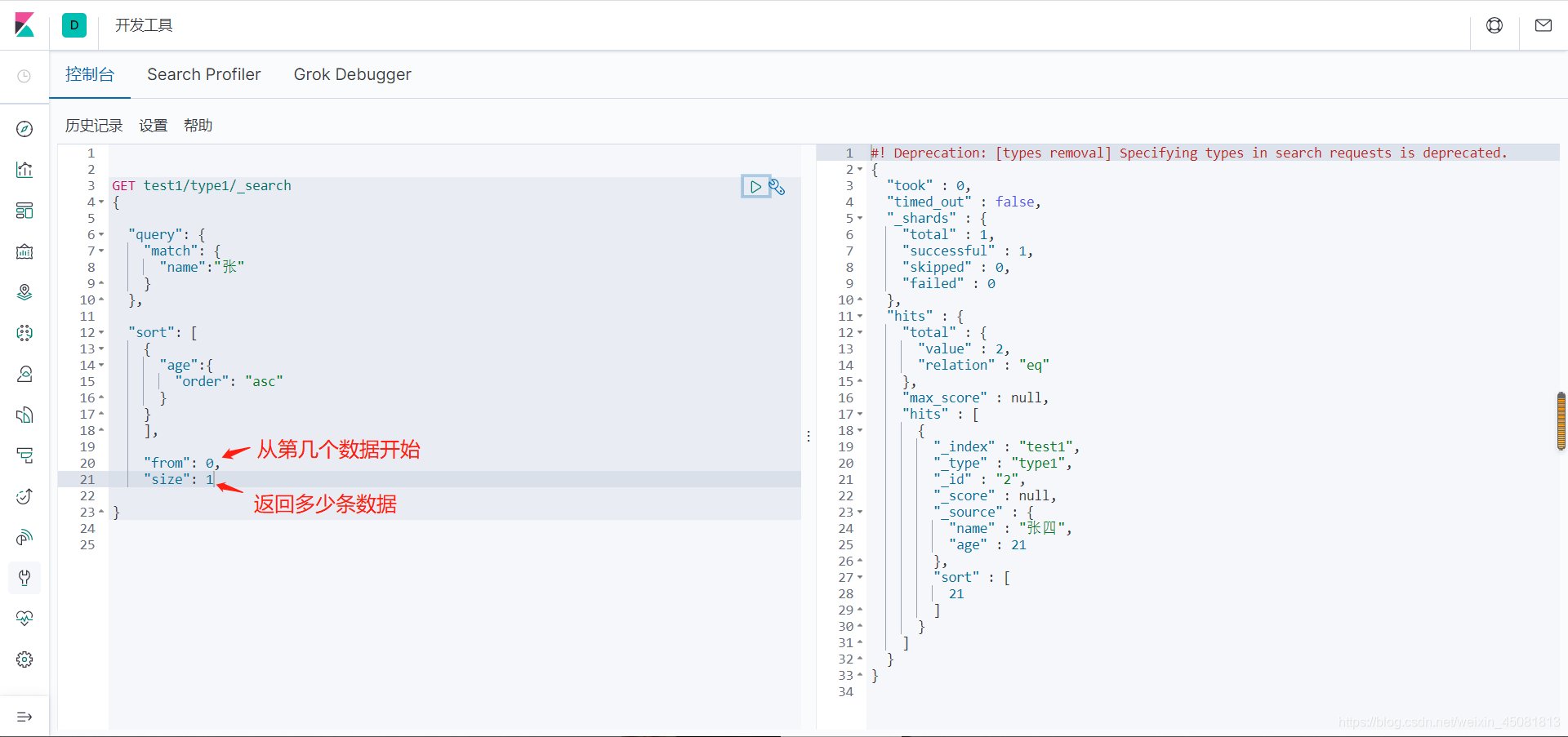
8.sort,range,exists
-
sort

-
range:范围查询,用于匹配在某一范围内的数值型、日期类型或者字符串型字段的文档,比如搜索哪些书籍的价格在 50 到 100 之间、哪些书籍的出版时间在 2015 年到 2019 年之间。使用 range 查询只能查询一个字段,不能作用在多个字段上。

GET /test_wsy/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}

- exists:查询会返回字段中至少有一个非空值的文档。
GET /test_wsy/_search
{
"query": {
"bool": {
"must": [
{
"exists":{"field":"name"}
}
]
}
}
}
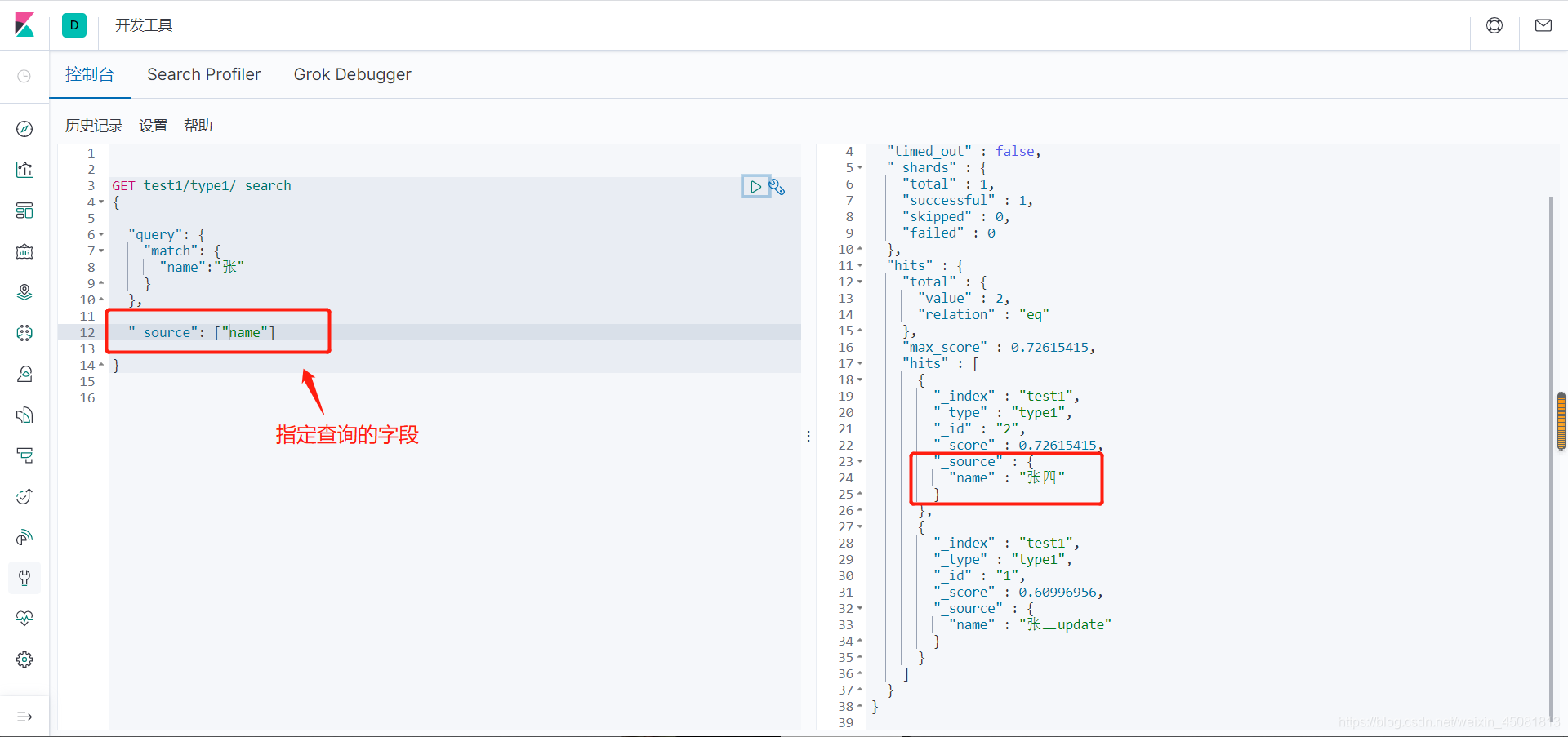
七.API操作
-
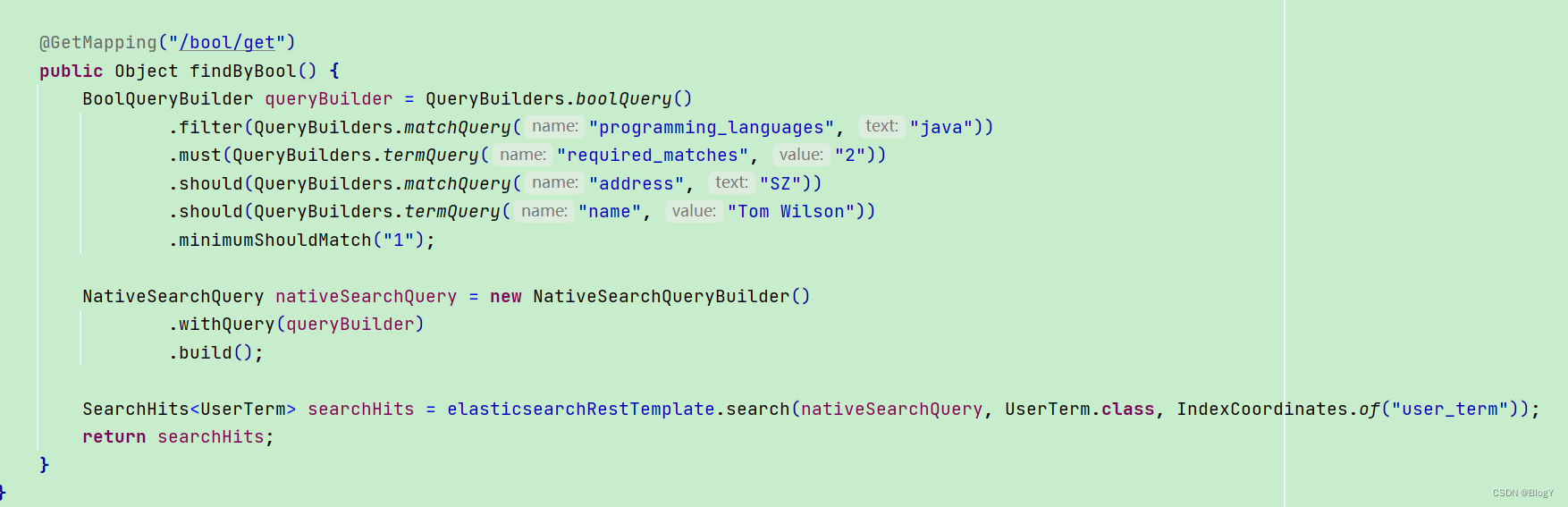
match:QueryBuilders.matchQuery(“name”, “小明”)
-
match_phrase:QueryBuilders.matchPhraseQuery(“desc”,“成绩很好”)
-
multi_match:QueryBuilders.multiMatchQuery(“哈哈哈”,“name”,“desc”); //前一个参数为要查询的数据,后面的为属性名
-
range:QueryBuilders.rangeQuery(“age”).gte(20).lt(30)
-
term:QueryBuilders.termQuery(“desc”, “很好”)
-
terms:QueryBuilders.termsQuery(“desc”,“成绩”,“英语”);
-
exists:QueryBuilders.existsQuery(“name”);
-
must
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.must(QueryBuilders.termQuery(“desc”, “成绩”)) -
must_not
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.mustNot(QueryBuilders.termQuery(“desc”, “很好”)) -
should
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.should(QueryBuilders.termQuery(“name”, “成绩”)) -
filter
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.filter(QueryBuilders.termQuery(“desc”, “历史”)) -
分页和排序
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.withSort(SortBuilders.fieldSort(“age”).order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort(“money”).order(SortOrder.ASC))
.withPageable(PageRequest.of(1, 10))
.build(); -
BoolQueryBuilder:
获取查询条件构造器QueryBuilders进行操作:
BoolQueryBuilder queryBuilder= QueryBuilders.boolQuery();
queryBuilder.must(QueryBuilders.termQuery(“user”, “kimchy”))
.mustNot(QueryBuilders.termQuery(“message”, “nihao”))
.should(QueryBuilders.termQuery(“gender”, “male”));
QueryBuilders.boolQuery #子方法must可多条件联查
QueryBuilders.termQuery #精确查询指定字段
QueryBuilders.matchQuery #按分词器进行模糊查询
QueryBuilders.rangeQuery #按指定字段进行区间范围查询
# 大于等于 .from .gte
# 小于等于 .to .lte
- NativeSearchQueryBuilder
//构建Search对象
NativeSearchQuery build = new NativeSearchQueryBuilder()
//条件
.withQuery(queryBuilder)
//排序
.withSort(SortBuilders.fieldSort("id").order(SortOrder.ASC))
//高亮
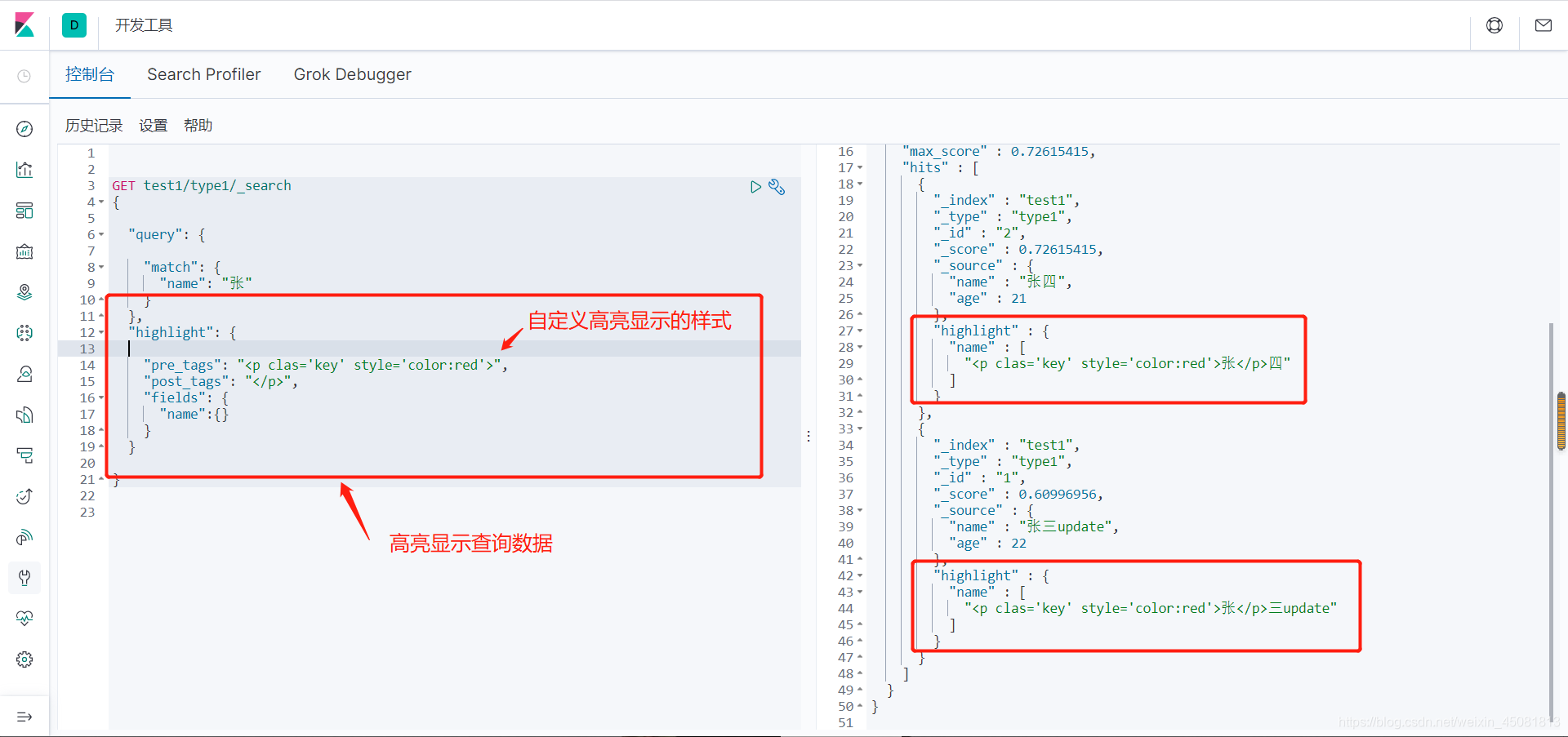
.withHighlightFields(name, ms)
//分页
.withPageable(PageRequest.of(pageNum - 1, pageSize))
//构建
.build();
AggregatedPage<Goods> aggregatedPage = elasticsearchTemplate.queryForPage(build, Goods.class,new Hig());
//queryForPage 参数一: NativeSearchQuery 封装的查询数据对象
参数二: es对应索引实体类
参数三: 调用高亮工具类
八.动态索引
{
"template": {
"settings": {
"index": {
"max_result_window": "2000000",
"number_of_shards": "1",
"number_of_replicas": "1"
}
},
//字段映射
"mappings": {
"dynamic_templates": [],
"properties": {
"aptDate": {
"type": "date",
"format": "yyyy-MM-dd||epoch_millis"
},
"aptId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"createdAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"deletedAt": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"districtName": {
"type": "text"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"mobile": {
"type": "text"
},
"startTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis"
}
}
},
//索引模式
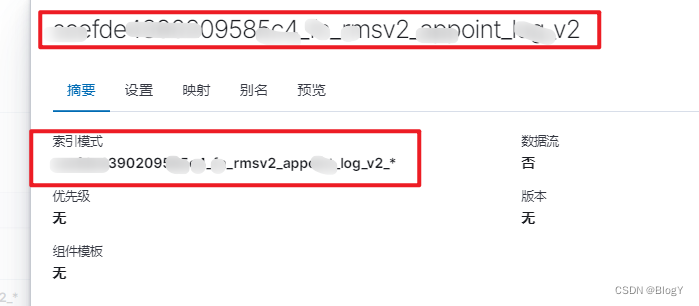
"aliases": {
"09585_fn_rms2_apoint_log_v2": {}
}
}
}
保存数据时根据某个规则将数据放到不同的索引分片里
九.ES数据迁移
#1.建立临时索引
PUT fn_rmsv2_log_v2_test_temp
#2.迁移数据导临时索引
POST _reindex
{
"source": {
"index": "fn_rmsv2_log_v2_test",
"size": 1000
},
"dest": {
"index": "fn_rmsv2_log_v2_test_temp"
}
}
#3.删除原索引并重建
DELETE fn_rmsv2_log_v2_test
PUT fn_rmsv2_log_v2_test
#4.将临时索引数据迁移回新建的原索引
POST _reindex
{
"source": {
"index": "fn_rmsv2_log_v2_test_temp",
"size": 1000
},
"dest": {
"index": "fn_rmsv2_log_v2_test"
}
}
#5.删除临时索引
DELETE fn_rmsv2_log_v2_test_temp
十.Springboot集成ES
1.引入依赖
<properties>
<java.version>1.8</java.version>
<!--自己定义es版本依赖,保证和本地一致-->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
<!--ES-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--fastjosn-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.74</version>
</dependency>
2.创建实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
3.ES配置类
@Configuration
public class EsClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder( new HttpHost("127.0.0.1",9200,"http")));
return client;
}
}
4.对API的调用(重点)
@SpringBootTest
public class EsApiTest {
@Autowired
private RestHighLevelClient restHighLevelClient;
//索引的创建
@Test
void testCreateIndex() throws IOException {
//1.创建索引请求
CreateIndexRequest request=new CreateIndexRequest("es_api2");
//2.客户端执行请求 IndicesClient,请求后获得响应
CreateIndexResponse createIndexResponse=restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//测试获取索引
@Test
void testExistIndex() throws IOException {
GetIndexRequest request=new GetIndexRequest("es_api");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request=new DeleteIndexRequest("es_api2");
//删除
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
//测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user=new User("哈哈哈3.0",22);
//创建请求
IndexRequest request=new IndexRequest("es_api");
//设置规则
request.id("2");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//把数据放入请求
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse=restHighLevelClient.index(request,RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
//获取文档,判断是否存在
@Test
void testIsExists() throws IOException {
GetRequest getRequest=new GetRequest("es_api","1");
//不获取返回的_source 的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest getRequest=new GetRequest("es_api","1");
GetResponse getResponse=restHighLevelClient.get(getRequest,RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//打印文档的内容
System.out.println(getResponse);
}
//更新文档的信息
@Test
void testUpdateRequest() throws IOException {
UpdateRequest updateRequest=new UpdateRequest("es_api","1");
updateRequest.timeout("1s");
User user=new User("dessw",33);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse=restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
//删除文档记录
@Test
void testDeleteRequest() throws IOException {
DeleteRequest deleteRequest=new DeleteRequest("es_api","2");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse=restHighLevelClient.delete(deleteRequest,RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
//批量插入数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest=new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList=new ArrayList<>();
userList.add(new User("dessw1",22));
userList.add(new User("dessw2",33));
userList.add(new User("dessw3",34));
userList.add(new User("dessw4",55));
userList.add(new User("dessw5",13));
userList.add(new User("dessw6",32));
//批处理请求
for (int i=0;i<userList.size();i++){
bulkRequest.add(
new IndexRequest("es_api")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse=restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());
}
//查询
@Test
void testSearch() throws IOException {
SearchRequest searchRequest=new SearchRequest("es_api");
//构建搜索条件
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//查询条件,我们可以使用QueryBuilders工具来实现
//QueryBuilders.termQuery 精确查询
//QueryBuilders.matchAllQuery 匹配所有
TermQueryBuilder termQueryBuilder= QueryBuilders.termQuery("name","dessw1");
// MatchAllQueryBuilder matchAllQueryBuilder=QueryBuilders.matchAllQuery();
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("=================");
for (SearchHit documentFields:searchResponse.getHits().getHits()){
System.out.println(documentFields.getSourceAsMap());
}
}
}
十一. Mysql数据同步ES

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)