
BN(Batch Normalization)层原理与作用
BN层最重要的作用是让加速网络的收敛速度,同时让网络训练变得更容易;另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等,而没有使用BN的话,更大的学习率就可能导致训练发散,大学习率又反过来作用到训练速度上,加速了收敛速度,两者相辅相成。此外,也有一种说法是BN层可以提高网络的泛化能力,抑制过拟合,不过这个说法一直存在争议。
BN层的作用
BN层最重要的作用是让加速网络的收敛速度,BN的论文名字也很清晰的说明了这个点《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,同时BN让网络训练变得更容易;另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等,而没有使用BN的话,更大的学习率就可能导致训练发散,大学习率又反过来作用到训练速度上,加速了收敛速度,两者相辅相成。
此外,也有一种说法是BN层可以提高网络的泛化能力,抑制过拟合,不过这个说法一直存在争议。
BN层计算过程
BN层需要计算一个minibatch input feature(
x
i
x_i
xi)中所有元素的均值
μ
\mu
μ和方差
σ
\sigma
σ,然后对
x
i
x_i
xi减去均值除以标准差,最后利用可学习参数
γ
\gamma
γ和
β
\beta
β进行仿射变换,即可得到最终的BN输出
y
i
y_i
yi,具体过程如下:
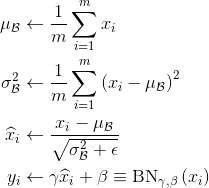
具体过程为:
1.计算样本均值。
2.计算样本方差。
3.样本数据标准化处理。
4.进行平移和缩放处理。引入了
γ
\gamma
γ和
β
\beta
β两个参数。来训练γ和β两个参数。引入了这个可学习重构参数
γ
\gamma
γ 和
β
\beta
β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。
需要注意的是,既然BN是在batch维度上做normalization,那么BN涉及的几个变量的维度就应该是一个feature map的size,比如BN layer的输入是 N × C × W × H N \times C \times W \times H N×C×W×H,那么BN的参数维度就应该是 C × W × H C \times W \times H C×W×H,也就是说BN计算的是batch内feature map每个点的均值,方差,以及 γ \gamma γ和 β \beta β。
为什么BN能加速训练收敛
Internal Covariate Shift
提到训练收敛的问题,需要先解释一个现象,叫做内部协变量偏移(Internal Covariate Shift),对于深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情,而不是covariate shift问题只发生在输入层。
固定输入分布
而BatchNorm的基本思想就是,能不能让每个隐层节点的激活输入分布固定下来呢?这样就避免了“Internal Covariate Shift”问题了。所以就有了BN中的数据标准化处理,BN 其实就是在做 feature scaling,而且它的目的也是为了在训练的时候避免这种 Internal Covariate Shift 的问题。
batch normalization
顺着这个思路想下去,如果要限制到一个固定的输入,那应该是什么样子。BN选择了normalization,也就是一种白化操作,这个很好理解,我们在原始图像输入到网络之前都会做减均值,除标准差的操作,这个操作有时单独做,有时和第一层卷积组合起来做,但是不管哪种都必须要有的。图像处理中对输入图像进行白化(Whiten)可以有效加快神经网络的收敛,而对多层网络中的每一层输出做白化,就是我们看到的在CNN中加入BN层的样子。
γ \gamma γ& β \beta β
但是到这里还没有结束,简单直接白化引入了太多的人工设计,使输入强行归一化,对于原始图像来说这样直接处理还行,但是越是到了网络的深层,CNN提取出来的特征就越是无法解释,那么同样的白化操作就变得不合理,所以BN在白化之后引入了两个参数控制白化的程度,它刚刚好使白化的逆过程,而且,这两个参数是参与训练的,那么一种极端的可能就是,白化如果对结果没有作用,那么 γ \gamma γ& β \beta β 很有可能将白化后的结果恢复成原来的样子。
为什么BN能抑制过拟合
BN层抑制过拟合抑制存在争议,《UNDERSTANDING DEEP LEARNING REQUIRES RETHINKING GENERALIZATION》实验出BN层加入使得overfitting再更多的training epoch后出现,但并不能阻止。
如果硬要说是防止过拟合,可以这样理解:BN每次的mini-batch的数据都不一样,但是每次的mini-batch的数据都会对moving mean和moving variance产生作用,可以认为是引入了噪声,这就可以认为是进行了data augmentation,而data augmentation被认为是防止过拟合的一种方法。因此,可以认为用BN可以防止过拟合。
BN层与卷积层的融合
一般情况下BN层都是直接接到卷积操作之后,训练结束后,卷积和的参数和BN层的参数都会固定下来。同时上面介绍了,BN是对输入特征图的每一个像素点归一化后的线性变换,并且变换的参数相同。满足了这些特点,BN层在网络inference过程中,其实可以融合进卷积层中,具体的方式就是用BN的参数改变卷积核中每一个位置的参数。
假设卷积变化如下:
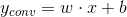
我们将卷积公式代入到BN的公式中,有:
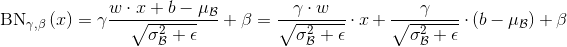
另:
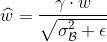
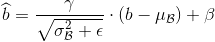
则有:
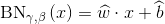
即重新计算后的卷积核参数,融合了固定参数的BN层。
Sync BN
在一般的视觉问题上,单卡的batchsize其实已经够大,没必要把所有卡上的都统计一遍。然而到了现在的检测或者分割问题上,有些大模型单卡只能bz=1,这样的话BN完全无法发挥作用,所以我们需要在更多的卡上同步bn。
PyTorch-Encoding
Synchronized-BatchNorm-PyTorch
pytorch-syncbn

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 49
49 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)