
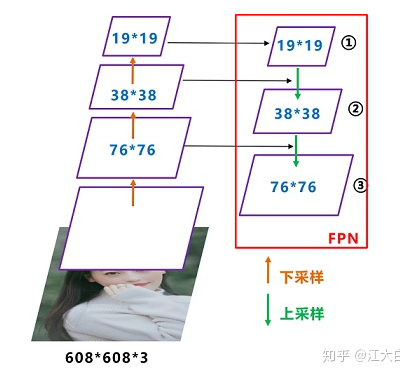
FPN+PAN结构学习
yolo4的neck结构采用该模式,我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。如图所示,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。这样结合操作,FPN层自顶
yolo4的neck结构采用该模式,我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。

如图所示,FPN是自顶向下的,将高层特征通过上采样和低层特征做融合得到进行预测的特征图。Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
自底向上增强
如上图中所示,FPN是自顶向下,将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递,而本文就是针对这一点,在FPN的后面添加一个自底向上的金字塔,可以说是很皮了。这样的操作是对FPN的补充,将低层的强定位特征传递上去,个人称之为”双塔战术“。
参考:
https://zhuanlan.zhihu.com/p/143747206utm_source=wechat_session&utm_medium=social&utm_oi=667962890661924864&from=singlemessage
https://www.cnblogs.com/wzyuan/p/10029830.html
FPN还是PAN或者后面的BiFPN都是类似的结构。FPN的理念就是增强不同层特征融合,在多尺度上进行预测。PAN在FPN的基础上又加了从下到上的融合。
我们都知道,深层的feature map携带有更强的语义特征,较弱的定位信息。而浅层的feature map携带有较强的位置信息,和较弱的语义特征。FPN就是把深层的语义特征传到浅层,从而增强多个尺度上的语义表达。而PAN则相反把浅层的定位信息传导到深层,增强多个尺度上的定位能力。
FPN的作用
FPN是在卷积神经网络中图像金字塔的应用。图像金字塔在多尺度识别中有重要的作用,尤其是小目标检测。顶层特征上采样后和底层特征融合,每层独立预测。
fpn设计动机:
1.高层特征向低层特征融合,增加低层特征表达能力,提升性能
2.不同尺度的目标可以分配到不同层预测,达到分而治之。
图片
FPN每层做特征融合的特征图有两个,首先是前向传播,然后取了每个特征图做上采样(最近邻插值),对应前向传播的特征图做融合。融合的方式是:通过1x1卷积调整通道数,然后直接add。之后进行3x3卷积操作,目的是消除上采样的混叠效应。
其实,fpn真正起作用的是分而治之的策略,特征融合的作用其实很有限,此外fpn存在消耗大量显存,降低推理速度。
为什么FPN采用融合以后效果要比使用pyramidal feature hierarchy这种方式要好?
图片
卷积虽然能够高效地向上提取语义,但是也存在像素错位问题,通过上采样还原特征图很好地缓解了像素不准的问题。
backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
从感受野的角度思考,浅层特征的感受野比较小,深层网络的感受野比较大,浅层网络主要负责小目标的检测,深层的网络负责大目标的检测(比如人脸检测中的SSH就使用到了这个特点)。再联想后来的BiFPN,语义特征和定位信息在串联的FPN/PAN结构中被像踢皮球一样的“传来传去”…
————————————————
最后说一下全连接作用:全连接层其实可由卷积实现,可看作感受野为整个特征图的卷积核,所以全连接层是感受野更大的卷积,另外,这里的卷积参数不共享,每个像素点拥有一个卷积核,
FPN在RPN中的应用
rpn在faster rcnn中用于生成proposals,原版rpn生成在每个image的最后一张特征图上生成3x3个proposal。但实际上,小目标下采样到最后一个特征图,已经很小了。fpn可以在之前的多个特征图上获得proposal,具体做法是:在每个feature map上获得1:1、1:2、2:1长宽比的框,尺寸是{322、642、1282、2562、512^2}分别对应{P2、P3、P4、P5、P6}这五个特征层上。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
如何解决小目标识别问题
通用的定义来自 COCO 数据集(https://so.csdn.net/so/search%3Fq%3D%25E6%2595%25B0%25E6%258D%25AE%25E9%259B%2586%26spm%3D1001.2101.3001.7020),定义小于 32x32 pix 的为小目标。
小目标检测的难点:可利用特征少,现有数据集中小目标占比少,小目标聚集问题
首先小目标本身分辨率低,图像模糊,携带的信息少。由此所导致特征表达能力弱,也就是在提取特征的过程中,能提取到的特征非常少,这不利于我们对小目标的检测。
另外通常网络为了减少计算量,都使用到了下采样,而下采样过多,会导致小目标的信息在最后的特征图上只有几个像素(甚至更少),信息损失较多。
1 数据。
提高图像采集的分辨率:基于 GAN 的方法解决的也是小目标本身判别性特征少的问题,其想法非常简单但有效:利用 GAN 生成高分辨率图片或者高分辨率特征。
2 Data Augmentation。一些特别有用的小物体检测增强包括随机裁剪、随机旋转和马赛克增强。copy pasting, 增加小目标数量。缩放与拼接,增加中小目标数量
3 修改模型输入尺寸。提高模型的输入分辨率,也就是减少或者不压缩原图像。tiling,将图像切割后形成batch,可以在保持小输入分辨率的同时提升小目标检测,但是推理时也需要 tiling,然后把目标还原到原图,整体做一次 NMS。
4 修改 Anchor。适合小目标的 Anchor
5 Anchor Free。锚框设计难以获得平衡小目标召回率与计算成本之间的矛盾,而且这种方式导致了小目标的正样本与大目标的正样本极度不均衡,使得模型更加关注于大目标的检测性能,从而忽视了小目标的检测。
6 多尺度学习。FPN, 空洞卷积,通过多尺度可以将下采样前的特征保留,尽量保留小目标
减小下采样率。比如对于 YOLOv5 的 stride 为 32, 可以调整其 stride 来减小下采样率,从而保留某些比较小的特征。
7 SPP 模块。增加感受野,对小目标有效果,SPP size 的设置解决输入 feature map 的size 可能效果更好。
损失函数。小目标大权重,此外也可以尝试 Focal Loss。
LINK

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 43
43 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)