K均值聚类算法(K-Means)
K均值聚类算法(K-Means). 实验目标使用Sklearn库操作机器学习2. 实验主要使用的 ????????????ℎ????????Python 库¶名称版本简介Numpy1.16.0线性代数Pandas0.25.0数据分析Matplotlib3.1.0数据可视化SKlearn0.22.1机器学习
K均值聚类算法(K-Means)
. 实验目标
使用Sklearn库操作机器学习
2. 实验主要使用的 𝑃𝑦𝑡ℎ𝑜𝑛Python 库¶
| 名称 | 版本 | 简介 |
|---|---|---|
| Numpy | 1.16.0 | 线性代数 |
| Pandas | 0.25.0 | 数据分析 |
| Matplotlib | 3.1.0 | 数据可视化 |
| SKlearn | 0.22.1 | 机器学习 |
理论学习部分
机器学习(Machine Learning, ML)是人工智能(AI)的一个子集,是使计算机具有智能的根本途径。
在本实验中,您将学习K-Means聚类算法的基本思想、算法以及如何用Python实现。
实验步骤
步骤1 安装并引入必要的库
代码示例:
pip install numpy==1.16.0
pip install pandas==0.25.0
pip install scikit-learn==0.22.1
pip install matplotlib==3.1.0代码示例:
import random
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets.samples_generator import make_blobs
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets import load_iris
%matplotlib inline步骤2 生成随机数
创建数据集!
首先,我们需要建立一个随机种子。 使用numpy的random.seed()函数,其中种子将被设置为0
代码示例:
np.random.seed(0)
接下来,我们将使用make_blobs类进行*随机点集群*。make_blobs类接受很多输入,但我们将使用这些特定的输入:**
输入
n_samples: 生成随机点总数取值为: 5000centers:生成样本点的中心取值为: [[4, 4], [-2, -1], [2, -3],[1,1]]cluster_std:类的标准差取值为: 0.9
输出**X: 形状为 [n_samples, n_features]的数组。 (特征矩阵(Feature Matrix))生成的样本.y: 形状为[n_samples]的数组. (响应向量(Response Vector))样本对应的类别标签**
代码示例:
X, y = make_blobs(n_samples=5000, centers=[[4,4], [-2, -1], [2, -3], [1, 1]], cluster_std=0.9)
显示随机生成的数据的散点图。
代码示例:
plt.scatter(X[:, 0], X[:, 1], marker='.')

步骤3 设置K-Means
现在我们有了我们的随机数据,让我们设置我们的 K-Means聚类。
KMeans类有许多可以使用的参数,但我们将使用这三个参数:
-
init: 类中心的初始化方法。
-
- 取值为: “k-means++”
- k-means++: 以智能方式为k均值聚类选择初始聚类中心,以加速收敛。
-
n_clusters: 要形成的聚类数量也是要生成的聚类中心数量。
-
- 取值为: 4
-
n_init: 设置选择质心种子次数。返回聚类中心最好的一次结果(好是指计算时长短)
-
- 取值为: 12
使用这些参数初始化KMeans,其中输出参数称为k_means。
代码示例:
k_means = KMeans(init = "k-means++", n_clusters = 4, n_init = 12)
现在让我们用我们上面创建的特征矩阵X来拟合KMeans模型
代码示例:
k_means.fit(X)
现在让我们使用KMeans的 .labels_ 属性为模型中的每个点获取标签,并将其保存为 k_means_labels
代码示例:
k_means_labels = k_means.labels_
k_means_labels
我们还将使用KMeans的.cluster_centers_ 取聚类中心的坐标,并将其保存为k_means_cluster_centers
代码示例:
k_means_cluster_centers = k_means.cluster_centers_
k_means_cluster_centers
步骤4 绘图
所以现在我们已经生成了随机数据并且初始化了KMeans模型,让我们对它们进行绘制并看看它是什么样的!
请仔细阅读代码和注释以了解如何绘制模型。
代码示例:
# 指定图形尺寸
fig = plt.figure(figsize=(6, 4))
#颜色使用一个颜色映射,它将根据标签的数量生成一个颜色数组。 我们使用set(k_means_labels)来获取唯一的标签。
colors = plt.cm.Spectral(np.linspace(0, 1, len(set(k_means_labels))))
#创建一个黑色背景(背景为黑色,这样有助于我们看到各类中的样本点与聚类中心的连接)
ax = fig.add_subplot(1, 1, 1, facecolor = 'black')
# 用于绘制数据点和聚类中心的循环。
#k将在0-3范围内,这将匹配每个数据点所在的可能簇。
for k, col in zip(range(len([[2, 2], [-2, -1], [4, -3], [1, 1]])), colors):
# 创建所有数据点的列表,其中类中的数据点标记为true,否则标记为false。
my_members = (k_means_labels == k)
# 定义聚类中心
cluster_center = k_means_cluster_centers[k]
# 使用color col绘制数据点.
ax.plot(X[my_members, 0], X[my_members, 1], 'w',
markerfacecolor=col, marker='.')
# 指定颜色绘制聚类中心
ax.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=6)
# 图名称
ax.set_title('KMeans')
# 删除x轴刻度
ax.set_xticks(())
# 删除y轴刻度
ax.set_yticks(())
# 展示图
plt.show()
# 显示上面的散点图进行比较。
plt.scatter(X[:, 0], X[:, 1], marker='.')


步骤5 聚类分析
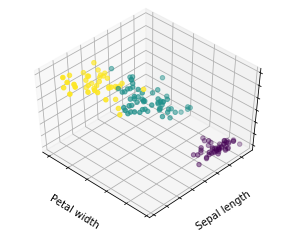
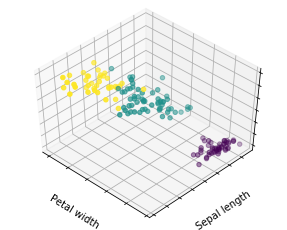
对iris数据集进行聚类分析
使用 load_iris() 函数, 将iris数据集储存在变量iris中
代码示例:
iris = load_iris()
同时将iris.data赋值给X变量,将iris.target赋值给y变量
代码示例:
X = iris.data
y = iris.targe
现在让我们运行其余的代码,看看K-Means产生的结果!
代码示例:
estimators = {'k_means_iris_3': KMeans(n_clusters=3),
'k_means_iris_8': KMeans(n_clusters=8),
'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1,
init='random')}
fignum = 1
for name, est in estimators.items():
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float))
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
fignum = fignum + 1
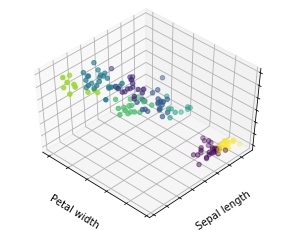
# 绘制结果
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
for name, label in [('Setosa', 0),
('Versicolour', 1),
('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(),
X[y == label, 0].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
#重新排序标签以使颜色与聚类结果匹配
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
plt.show()

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)